Prompt - Task Reformulation in NLP
- Record of recent task reconstruction methods based on templates, a
particularly interesting direction since the appearance of GPT-3. These
methods typically design prompts for tasks, converting samples and tasks
into natural language templates, which are then directly input into
pre-trained language models to generate text, thereby indirectly
completing the tasks. The construction of prompts standardizes the form
of downstream tasks and pre-trained tasks (language models), achieving
good results in few-shot learning. Key papers to read include the
following nine:
- Early work that converts questions into natural language and uses
pre-trained language models for answers:
- (Harvard) Commonsense Knowledge Mining from Pretrained Models
- (Heidelberg) Argumentative Relation Classification as Plausibility Ranking
- (NVIDIA) Zero-shot Text Classification With Generative Language Models
- The PET approach, Pattern Exploiting Training:
- (LMU) Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference
- (LMU) It’s Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners
- (UNC) Improving and Simplifying Pattern Exploiting Training
- Automatically constructing prompts, Automatically Searching Prompts:
- (UCI, UCB) AUTOPROMPT: Eliciting Knowledge from Language Models with Automatically Generated Prompts
- (Princeton, MIT) Making Pre-trained Language Models Better Few-shot Learners
- (THU) GPT Understands, Too
- Early work that converts questions into natural language and uses
pre-trained language models for answers:
Commonsense Knowledge Mining from Pretrained Models
- The authors aim to mine commonsense knowledge from data with unknown distributions, whereas traditional supervised learning methods are easily influenced by the data distribution in the training set, leading to biased results.
- They convert relation triples into masked sentences and input them into BERT. The mutual information between the predicted results from BERT and the triples is used to rank the credibility of the triples.
- The task involves scoring a given triple to determine its likelihood
of representing real-world knowledge. This is divided into two steps:
Converting the triple into a masked sentence: multiple templates were manually designed for each relationship, and a set of rules was designed to ensure grammatical correctness (singular/plural, inserting articles, modifying nouns, etc.). All combinations of these templates and rules form a series of candidate sentences, which are then input into a pre-trained unidirectional language model to compute the log-likelihood score of each sentence being grammatically correct.
Inputting the generated sentences into BERT for scoring: here, the authors use conditional pointwise mutual information (PMI), where the mutual information between the head and tail entities, conditioned on the relation r, serves as the score:
\[ PMI(tail, head | relation) = \log p(tail | head, relation) - \log p(tail | relation) \]
In the language model, this effectively means masking the tail and predicting it. The first term in the equation masks only the tail, while the second term also masks the head (no prediction for the head). Additionally, if entities are composed of multiple words, a greedy approximation is used. Initially, all words are masked, and the highest-probability word is unmasked, followed by iterative predictions for the remaining words, where each time the highest-probability word is restored. The product of these probabilities gives the conditional probability of the entire word. The equation is asymmetric, so the authors also compute the head entity probability based on the relationship and tail entity, and average the two PMI values as the final result.
- The final results, although not as good as supervised learning, achieved the best results in unsupervised learning.
- This is an early attempt to use pre-trained models for Mask Predict, where the task is framed as a Cloze task. The patterns here are still manually designed (with a set of rules designed for each relation).
Argumentative Relation Classification as Plausibility Ranking
- The task in this paper is Argumentative Relation Classification, i.e., text pair classification, where the goal is to distinguish whether a pair of texts supports or contradicts a given (or implicit) conclusion. In positive text pairs, both texts support the conclusion, while in negative pairs, one supports and the other contradicts the conclusion.
- For this interesting task, the authors propose a similarly
interesting approach: using a Siamese network for ranking, where the
ranking is based on the plausibility (credibility) of the constructed
text. And what is this constructed text? Quite simple: the two sentences
to be classified are connected by a conjunction to form the constructed
text:
- Positive example: Text A, and Text B
- Negative example: Text A, however, Text B
- If Text A and Text B are contradictory, the credibility of the negative example is high. If Text A and Text B support each other, the credibility of the positive example is high.
- The next step involves using a pre-trained language model as the encoder in the Siamese network for ranking.
- The core idea here is to transform the task into natural language and use the language model, which has learned general knowledge about natural text, to perform the task and make predictions indirectly.
- Similar to the previous paper, the key here is to convert the task into natural language (a template) and cleverly use pre-trained language models to indirectly complete the task (by completing the constructed task).
Zero-shot Text Classification With Generative Language Models
- The authors use GPT to transform the text classification task into a natural language question by combining the original text with the category, and indirectly determine the category through text generation.
- The main advantage, as highlighted in the title, is zero-shot learning, which allows the model to generalize to categories that do not exist in the training data.
- Specifically, the text classification problem is turned into a multiple-choice QA task, where the options are formulated into a question: "Which category does this text belong to? A; B; C; D..." and then the text to be classified is appended. The goal is to train the language model to directly generate the correct category as text.
- To minimize the gap between pre-training and fine-tuning, the authors introduce a pre-training task, called title prediction pretraining, where all candidate titles are concatenated with the main text and the correct title is generated.
- This is a very intuitive, indirect, and bold use of language models
for classification tasks, where the language model directly generates
category labels.
![gW98oV.png]()
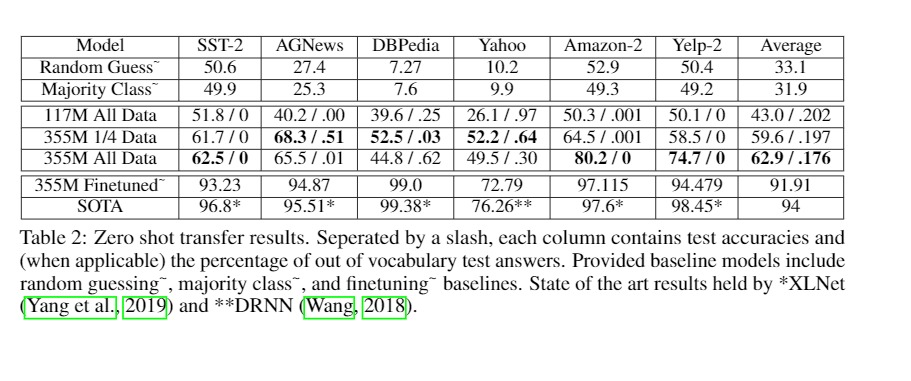
- The final zero-shot results, while not as good as fine-tuning or state-of-the-art models, show a strong generalization ability, outperforming the random and majority baseline models. The key takeaway is how the language model is used creatively to solve the classification task by designing multiple-choice questions.
Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference
- This paper formally introduces the concept of PET: Pattern-Exploiting Training.
- In the previous three papers, we see that many NLP tasks can be completed unsupervised or indirectly by providing natural language descriptions of the tasks through language models. However, these methods still fall short compared to supervised learning methods.
- PET offers a semi-supervised learning approach that successfully outperforms supervised models in low-resource settings.
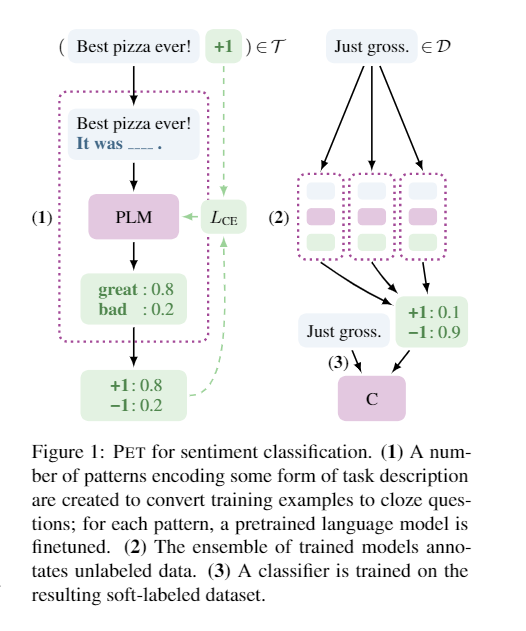
- The principle of PET is explained in a single diagram:
![gWivmd.png]()
- The authors introduce two concepts: pattern, which transforms the input text into a masked Cloze text based on the task, and verbalizer, which maps the predicted masked words from the language model to labels. Each pattern corresponds to a verbalizer, forming a PvP (pattern-verbalizer pair).
- The PET process is divided into three steps:
- First, use PvP to fine-tune the pre-trained language model on a small training set.
- Second, for each task, multiple PvPs can be designed to create different models through fine-tuning, and then a soft label is assigned to unannotated data using these models.
- Third, a classifier is trained on the labeled data to complete supervised learning.
- In the second step, there are two small details: ensemble learning with multiple classifiers (adding the predicted label distributions, which can be equally weighted or weighted based on zero-shot performance in the training set) and using soft labels (probability distributions) when labeling the data, with softmax applied at temperature T=2. These two techniques help better leverage the knowledge from the language model, one through ensemble robustness and the other through knowledge distillation.
- The authors also introduce iPET, a traditional semi-supervised learning approach that iterates between labeling and training, using increasing amounts of data and different generations of models to improve performance.
- The advantage of this semi-supervised framework is that the final operation is still supervised learning, achieving high accuracy, while reducing the uncertainty introduced by the language model through knowledge distillation (soft labels).
It's Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners
- The original PET team has another paper where the motivation is that small models can also achieve results comparable to large models like GPT-3 in few-shot learning when using PET, promoting environmental sustainability.
- In this paper, the authors extend the prediction of masked words in PvP to multiple masks, inserting a fixed maximum number of masks during training and then performing post-processing during prediction.
- They provide more extensive experimental results, which, while still in preprint form (not yet published in conferences...), later won the NAACL 2021 Outstanding Paper Award.
Improving and Simplifying Pattern Exploiting Training
![gIih5j.png]()
This paper improves PET by further simplifying the design of the pattern-verbalizer pair and reducing the number of patterns needed to achieve few-shot learning in a broad set of tasks.
The simplification helps lower the entry barrier for researchers and developers by making it easier to implement this framework with minimal effort.
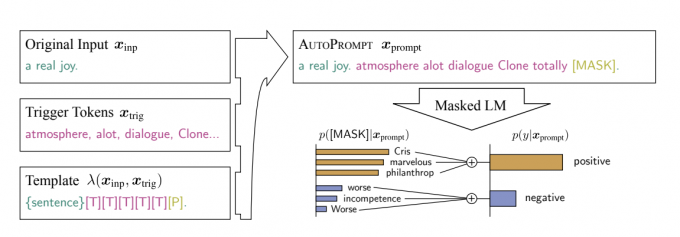
AUTOPROMPT: Eliciting Knowledge from Language Models with Automatically Generated Prompts
From the work introduced above, it can be seen that constructing effective text to trigger language models to generate results is crucial, which means constructing the prompt. Currently, all prompts are manually constructed, but later a series of works emerged attempting to automatically construct prompts.
This work cannot really be considered as prompts; a more accurate term would be "trigger words sequence," because it essentially applies a method for generating adversarial text samples to the task of constructing prompts.
Specifically, it draws on two papers: HotFlip: White-box adversarial examples for text classification and Universal Adversarial Triggers for Attacking and Analyzing NLP. The idea is to concatenate a sequence of trigger words into the sample, which can lead the model to make incorrect predictions. The search for trigger words in the model primarily uses the HotFlip method:
Initialize the trigger word \[\mathbf{e}_{adv}\] (e.g., words like the, a, an), then pass the model forward to obtain the gradient of the loss with respect to the trigger word embedding \[\nabla_{\mathbf{e}_{adv}} \mathcal{L}\]. Note that the label used for loss calculation should be the incorrect label that the model is intended to be fooled into predicting (i.e., the label after fooling the model).
We aim to replace the \(i\)-th trigger word with a word \[\mathbf{e}_{i}\] such that the loss is minimized most significantly after replacement, meaning the model is most likely to predict the wrong label. Therefore, the word we are looking for is \[ \underset{\mathbf{e}_{i}^{\prime} \in \mathcal{V}}{\arg \min } \mathcal{L}(\mathbf{e}_{i}^{\prime}) \], where a first-order Taylor expansion is used for approximation. We need to compute the gradient of the loss with respect to the token. Since token embedding lookup is not differentiable, we need to compute the gradient of the embedding of a specific token.
\[ \mathcal{L}(\mathbf{e}_{i}^{\prime}) = \mathcal{L}(\mathbf{e}_{adv_{i}}) + \left[\mathbf{e}_{i}^{\prime}-\mathbf{e}_{adv_{i}}\right]^{\top} \nabla_{\mathbf{e}_{adv_{i}}} \mathcal{L} \]
\[ \propto \left[\mathbf{e}_{i}^{\prime}-\mathbf{e}_{adv_{i}}\right]^{\top} \nabla_{\mathbf{e}_{adv_{i}}} \mathcal{L} \]
- This results in the first trigger word in the first round of iteration. Then, through beam search, the remaining trigger words are generated, iterating multiple times to eventually obtain a sequence of trigger words that can be used to attack the model.
The above describes the HotFlip method for text adversarial attacks. Its essence is to generate trigger words and append them to the sample to make the model predict an incorrect label. The idea of autoprompt is to generate trigger words to make the model predict a specified label.
![ghFDuF.md.png]()
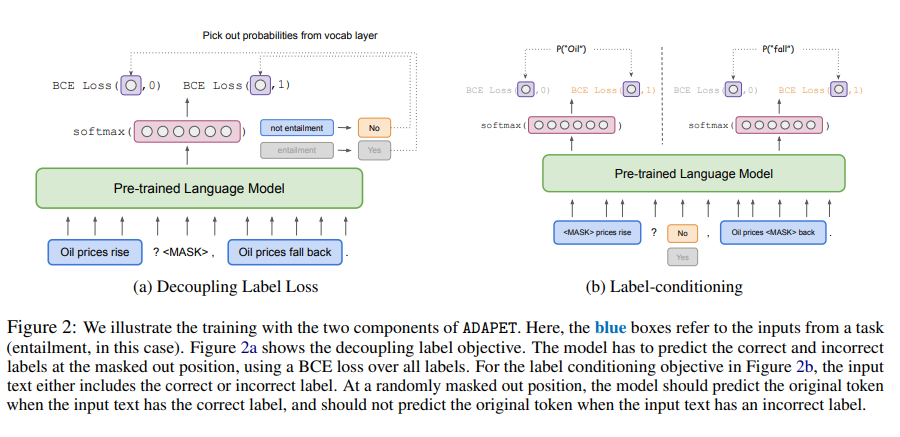
Now it becomes simpler. The authors first used the HotFlip method to generate trigger words for each task in the training set, then used a template to transform the sample into a sentence. As shown in the figure, the sentence is concatenated with the trigger word sequence ([T]) and the mask position ([P]) that the PLM is to predict. The model then predicts the word, and the label is obtained through post-processing. The specific post-processing operation involves summing the probabilities of the predicted words for each label, and finally normalizing these sums to get the probability for each label.
The above only explains the automatic prompt construction method in PvP. As for the verbalizer, i.e., the mapping from predicted words to labels, the authors also propose an automatic search method:
- After encoding the PLM and obtaining the embedding of the mask token containing contextual information, this embedding is used as a feature input, and the label is used as the output to train a logistic classifier. Then, the PLM-encoded embedding of each word is fed into this classifier to obtain a score for each word on each label. The top k words with the highest scores are chosen for each label as the mapped word set. Essentially, this compares the mask token's encoded embedding (needed for predicting the label) with the embeddings of each word, selecting the top k closest words, but using a logistic classifier to apply class-related feature weighting. This is not merely based on the semantic similarity of the PLM encoding but is a very clever method.
Making Pre-trained Language Models Better Few-shot Learners
The title of this paper is essentially the title of GPT-3 with "better" added, emphasizing how to better use prompts for few-shot learning.
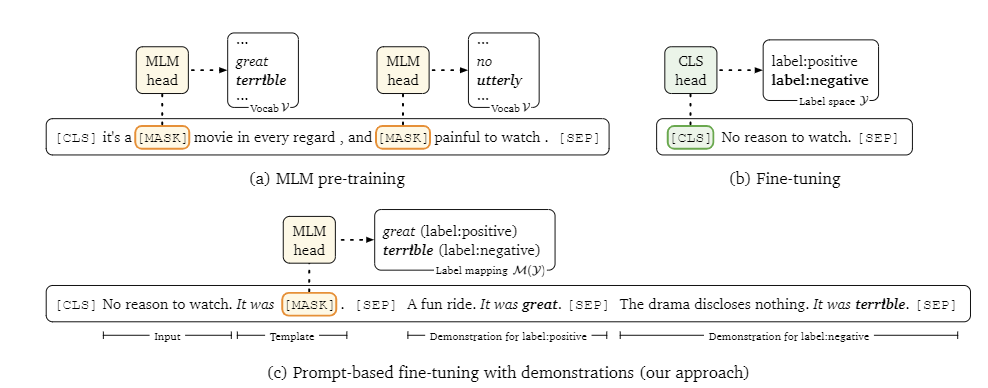
A training framework is proposed: prompt-based fine-tuning + automatic prompt generation + dynamically and selectively integrating task descriptions into prompts, all of which are strongly task-agnostic. Let's now go through these three improvements in detail.
![g58yOe.png]()
The image above clearly demonstrates the first improvement: prompt-based fine-tuning. As we can see, compared to previous prompt-based methods, in addition to the input and prompt, the input is also concatenated with a description for each label.
As for automatic prompt generation, it is divided into two parts:
- How to automatically generate the mapping from target words to labels given a template. Here, the author iterates over the results of a pre-trained language model (PLM). First, for each class, all the training samples of this class are identified, and the probability distribution of the masked word is inferred using the PLM. The top-k words are selected by accumulating the probability distributions of all samples to get the word-to-label mapping for that category. Since the model parameters change during the fine-tuning process, the result may shift, so the mapping needs to be re-ranked and adjusted after each training round.
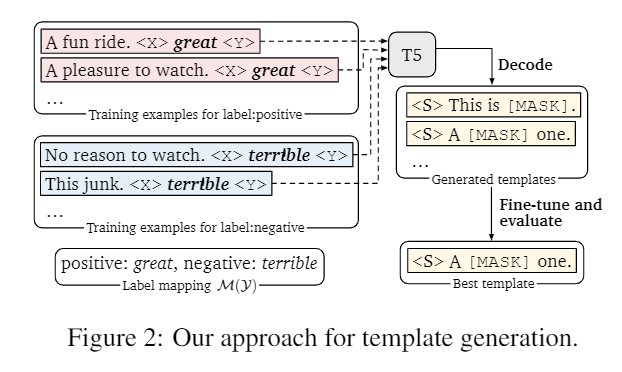
- Given a category and its target word, how to generate a template.
The author uses the T5 model because its mask span seq2seq pretraining
task aligns well with the template generation task. This can be
explained in a single diagram:
![g5YjfI.png]() The
generated prompt takes into account both the context of the training
samples and the semantic context of the label word. The author uses a
wide beam width to beam search a set of prompt candidates (100+), then
fine-tunes each sample on a small training set, selecting the one with
the highest performance on the validation set (or using top-k ensemble)
as the final prompt.
The
generated prompt takes into account both the context of the training
samples and the semantic context of the label word. The author uses a
wide beam width to beam search a set of prompt candidates (100+), then
fine-tunes each sample on a small training set, selecting the one with
the highest performance on the validation set (or using top-k ensemble)
as the final prompt. - Dynamic selective integration of tasks, which is more complicated. After obtaining the prompt, the question is how to construct the input sample. As shown in the first image, for each category, a sample is randomly selected and converted into a prompt to serve as the description for that category. All category descriptions are concatenated with the input sample (the one to be trained). During sampling, sentence-BERT is used to obtain the semantic embeddings of each sample, and only the top 50% of samples with the highest semantic similarity to the input sample are selected.
The design of this prompt is somewhat similar to a semantic similarity task, where the input is "x is a mask example? y is positive; z is negative." This essentially compares the semantic similarity between x and yz, propagating the label through this comparison.
 The
generated prompt takes into account both the context of the training
samples and the semantic context of the label word. The author uses a
wide beam width to beam search a set of prompt candidates (100+), then
fine-tunes each sample on a small training set, selecting the one with
the highest performance on the validation set (or using top-k ensemble)
as the final prompt.
The
generated prompt takes into account both the context of the training
samples and the semantic context of the label word. The author uses a
wide beam width to beam search a set of prompt candidates (100+), then
fine-tunes each sample on a small training set, selecting the one with
the highest performance on the validation set (or using top-k ensemble)
as the final prompt.GPT Understands, Too
![g52dDH.png]()
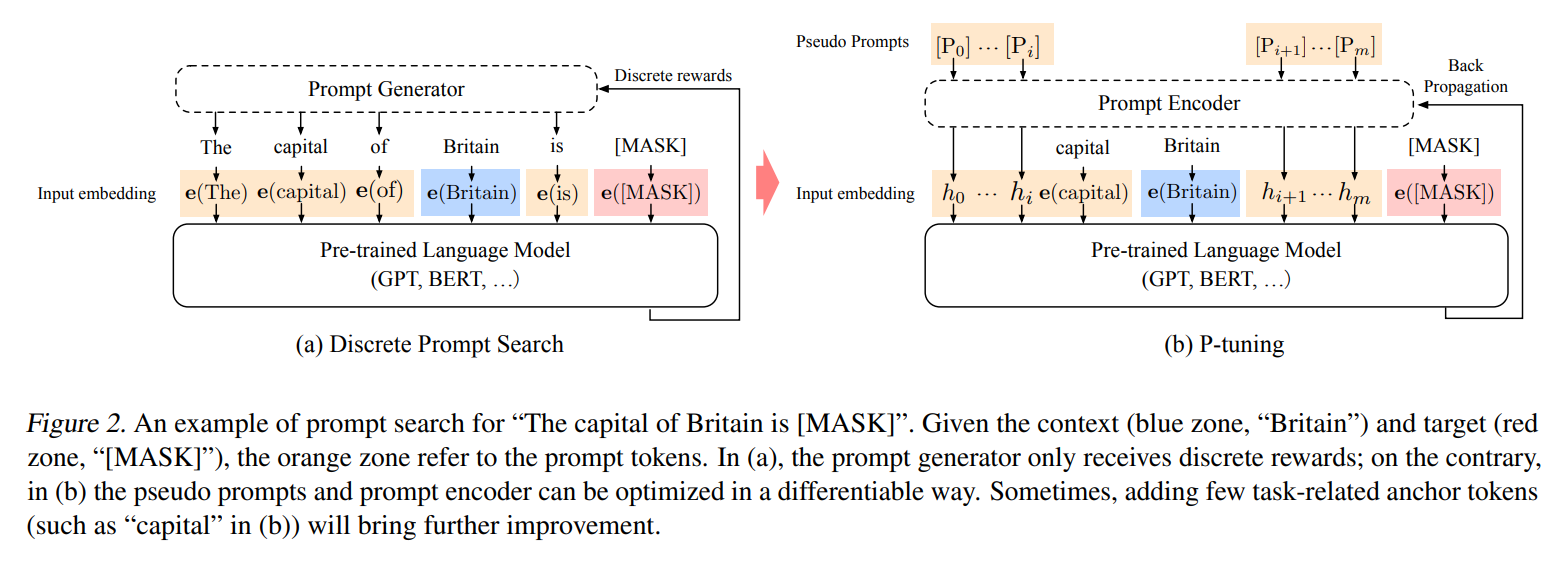
- This paper introduces P-tuning, which is not about finding discrete prompts (specific texts), but rather continuous ones (embeddings).
- Let's review the entire prompt-based method. It essentially transforms data and tasks into a form suitable for language model tasks, bringing them closer to pretraining objectives and enabling better utilization of the pretrained model's knowledge. In practice, this involves adding some prompt-generated templates to the input, and the output becomes target words related to category labels. The author reflects on whether these prompt-generated templates necessarily need to be human-understandable text. After all, what the model actually processes are embeddings. So, when searching for prompts, why not directly optimize the embeddings instead? Therefore, the author proposes using some unused symbols from word tables (such as the "unused" tokens in BERT) as pseudo-template tokens. These tokens are fixed, and rather than searching for new tokens, we directly optimize the embeddings corresponding to these tokens.
- To make these pseudo-tokens resemble natural language more closely, rather than just being independent symbols, the author also uses a bidirectional LSTM for encoding, which serves as the prompt encoder. However, the motivation for this approach isn't fully clear. Why not directly model the relationship within the PLM itself?
- From this perspective, the approach is essentially about concatenating a few embeddings to the input and optimizing them. The output and post-processing adopt the PET (Prompt-based Elicitation of Task) form, which feels like adding a layer for fine-tuning (hence the name Prompt finetuning?). In my view, both layer-based fine-tuning and P-tuning introduce a small number of parameters to adapt the PLM to downstream tasks, but P-tuning changes the format of the downstream task to better align with pretraining objectives, making the fine-tuning structural priors more reasonable. It also offers a higher-level summary of prompt-based work.