Edit-based Text Generation
- Record the methods of editing seq2seq in recent years, which have the advantages of high efficiency (partially autoregressive or non-autoregressive decoding) and less data hungry (small output vocabulary) for tasks with the same language input and output and minor changes (error correction, simplification, summarization).
- Mainly read five papers, sorted by their publication date on arXiv:
- (LevT, Facebook) Levenshtein Transformer
- (Huawei) EditNTS: An Neural Programmer-Interpreter Model for Sentence Simplification through Explicit Editing
- (LaserTagger, Google) Encode, Tag, Realize: High-Precision Text Editing
- (PIE) Parallel Iterative Edit Models for Local Sequence Transduction
- (Google) Felix: Flexible Text Editing Through Tagging and Insertion
Levenshtein Transformer
- Contributions
- Proposed an edit-based transformer using insertion and deletion operations, improving efficiency by 5 times.
- Designed a dual-policy reinforcement learning training method, addressing the complementarity of insertion and deletion.
- Unified the tasks of text generation and text refinement.
Problem Definition
The authors unify text generation and text refinement into a single Markov process, defined by the tuple (Y, A, \(\xi\), R, \(y_0\)) (sequence, action set, environment, reward function, initial sequence).
- Y represents the text sequence, with size \(V^N\).
- \(\xi\) is the environment. At each decoding step, the agent receives a sequence y as input, takes an action a, and then receives a reward r.
- The reward function is defined as the distance between the current sequence and the ground truth sequence, using Levenshtein distance (edit distance) in this case.
- The policy the agent learns is a mapping from sequence y to a probability distribution over actions P(A).
- It is worth noting that \(y_0\) can be an empty sequence, representing text generation, or a previously generated sequence, representing text refinement.
Actions
- Deletion operation: For each token in the sequence, perform binary classification to decide whether it should be deleted. The first and last tokens are retained without deletion checks to avoid breaking the sequence boundaries.
- Insertion operation: The insertion operation is performed in two steps: first, predict the insert position by performing a multi-class classification on each pair of adjacent token positions (the number of insert positions). It is important to note that the input includes these two tokens. Then, for each predicted position, a classification is done over a vocabulary V to generate the specific word to insert.
The entire process is divided into three steps: input sequence \(y_0\), perform deletion operations in parallel at all positions in the sequence to obtain \(y_1\); for \(y_1\), predict insert positions at all positions in the sequence, add placeholders according to the predictions to obtain \(y_2\); for all placeholders in \(y_2\), predict specific words to generate the final result, completing one iteration.
The three operations share a single transformer, and to reduce complexity (turning one autoregressive text generation round into three non-autoregressive operations), the classifiers for deletion and insert position predictions are attached to the middle transformer blocks. The classifier for text generation is only attached to the final transformer block, as the first two tasks are relatively simple and do not require complex feature extraction.
Training
The training process follows imitation learning. While there are many reinforcement learning concepts, it essentially involves perturbing the data and having the model learn to recover, still following Maximum Likelihood Estimation (MLE). I will attempt to explain its specific operations in the context of NLP tasks:
The training still uses teacher forcing, meaning the model directly learns to predict the oracle (ground truth) from the input, without autoregression.
For Levenshtein Transformer, three components are needed during training:
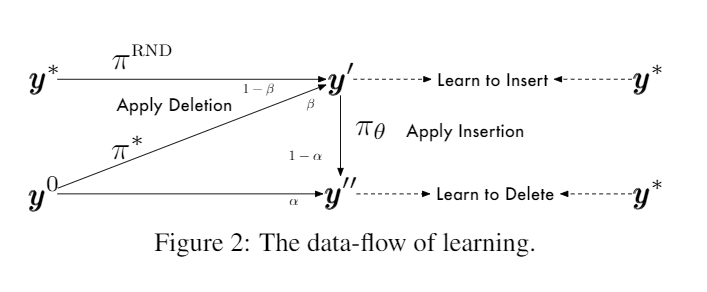
- Training input: The input is the text requiring edit operations (state distribution fed during training). These sentences should be original texts that have been disturbed by perturbation operations (roll-in policy). This is easy to understand—e.g., deleting some tokens and then having the model learn to insert them. The construction of this input involves two steps: determining the original text and applying perturbation operations. The original text can either be empty or the ground truth. In the design of the perturbation operations, the authors introduce the so-called dual policy, which essentially means allowing the model’s own operations to also serve as perturbations.
Operation Perturbation Type Learn from Model Dual Policy Randomly drop words from oracle text as input Deletion Insertion Directly use oracle input text as input Insertion Deletion Use the text after model deletion as input Deletion Insertion √ Use the text after model insertion as input Insertion Deletion √ The authors use probabilities to choose the operations for constructing data, as shown in the diagram below:
![gaoEPx.png]()
- Training output: After learning the opposite operations of the perturbation, the model needs to restore the original text. Once the input and output are determined, the ground truth actions (expert policy) are set. Generally, the model should restore the oracle, but since direct restoration can be difficult, the model is trained to restore a low-noise version with a certain probability. This low-noise version is derived from sequence distillation. Specifically, a normal transformer is trained on a unified dataset, and this transformer is used to infer each piece of data, using beam search to find non-top-1 sentences as low-noise versions for the model to learn to restore.
- Ground truth actions during training: Once the input and output are determined, the minimum edit distance operation is computed using dynamic programming as the ground truth action (expert policy) for the model to learn.
Inference
- During inference, the model performs multiple rounds of editing on the input text (each round includes one deletion, prediction of position, and insertion), greedily selecting the operation with the highest probability.
- Multiple rounds of editing continue until:
- A loop occurs (i.e., the same text reappears after editing),
- A preset maximum number of rounds is reached.
- Too many placeholders can lead to overly short generated text, and a penalty term can be added to control the number of placeholders.
- The use of two editing operations adds a degree of interpretability to the model’s inference.
Experiments
- The evaluation metrics include six items: BLEU scores for three translation pairs and ROUGE-1, ROUGE-2, and L values for the Gigaword summarization task. For English-Japanese translation and Gigaword, the original Transformer achieved the best results, outperforming LevT by about one point. For the other two translation datasets, the sequence-distilled LevT outperformed the original Transformer by about one point.
- For LevT, training with sequence distillation is generally better than using the original oracle sequence.
- In terms of inference speed, the LevT with sequence distillation is the fastest, with single sentence inference around 90ms, while the original Transformer takes 200-300ms for translation and 116ms for summarization tasks. The authors also report the number of inference iterations, showing that LevT requires an average of only 2 iterations, i.e., two deletions and two insertions, applied to the entire sentence. In contrast, the original Transformer’s average number of iterations is proportional to the length of the sentence. For short summarization datasets, the average number of iterations is 10.1, while for translation datasets, it reaches over 20. This demonstrates another advantage of LevT: its inference speed is not overly sensitive to text length and is primarily related to the number of iterations required for processing the entire sentence. The growth rate of iterations with length is smaller than the logarithmic complexity and far smaller than the quadratic complexity of traditional Transformers. The inference latency of the Transformer scales roughly linearly with text length, while LevT remains around 90ms with just two iterations.
- Ablation studies show that the design of the two operations, parameter sharing, and the dual policy all contribute to better final metrics.
- For deletion and insert position prediction, early exiting after the first transformer block yields good results, with BLEU dropping 0.4 but speeding up inference by a factor of 3.5 to 5 times compared to using the sixth layer.
- Additionally, the authors found that a LevT trained on translation tasks can be used zero-shot for text refinement, with performance within 0.3 BLEU points of a separately trained text refinement LevT, and even better performance on Ro-En. Both outperform traditional Transformers. This adaptability to text refinement aligns with intuition, as text refinement involves smaller edits compared to generating new text, where the hypothesis space is larger and more difficult to reach an ideal result. After fine-tuning on a text refinement dataset, LevT outperformed all models comprehensively.
EditNTS
A sentence simplification model is proposed that explicitly performs three types of operations: insertion, deletion, and retention.
Unlike LevT, EditNTS remains autoregressive, meaning it does not operate on the entire sentence simultaneously, and it introduces more information when predicting operations.
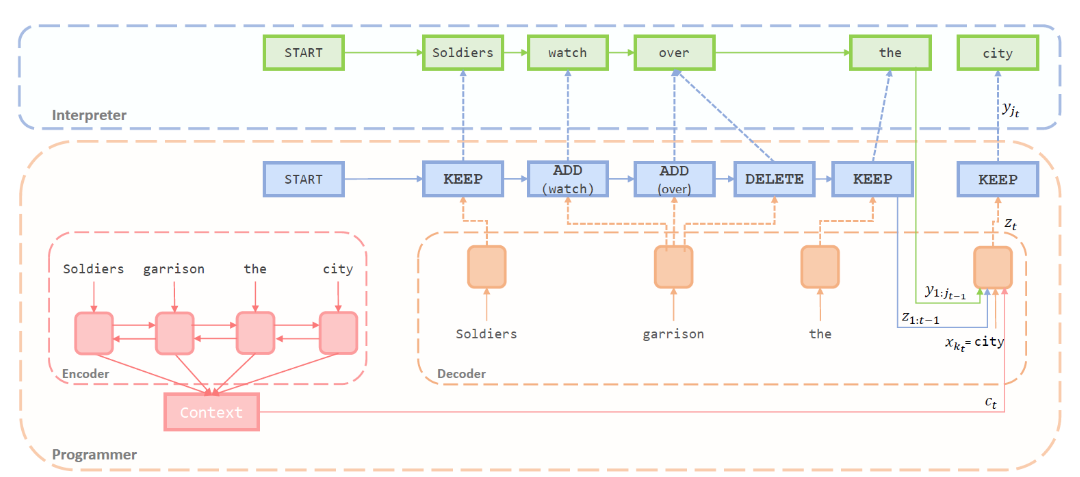
The model consists of two parts: an LSTM-based seq2seq model as the programmer that predicts the operation for each token position, generating a sequence of editing operations; and an additional interpreter that executes these operations to generate the edited sentence. The interpreter also includes a simple LSTM that aggregates the contextual information of the edited sentence.
![gdTVa9.png]()
Three key points to note:
- After predicting deletion and retention, the programmer moves to the next word. However, when predicting an insertion operation, the programmer stays on the current word and continues predicting the next operation, which enables the insertion of multiple words.
- The interpreter not only performs the editing based on the programmer’s predicted results, but also uses an LSTM to aggregate the contextual information of the sentence at the current time step after editing.
- When predicting editing operations, the programmer uses four pieces
of information:
- The encoder’s context, which comes from the last-layer attention-weighted output of the encoder LSTM.
- The word being processed, which comes from the decoder LSTM’s hidden state.
- The already edited sentence’s context, which comes from the interpreter LSTM’s attention-weighted output.
- The already generated editing operation sequence, which comes from the attention-weighted edit label output. Here, a simple attention mechanism is used, not an LSTM.
The encoder input also introduces position embedding.
Label construction, similar to LevT, involves creating a ground truth sequence of editing operations based on an edit distance dynamic programming approach. When multiple operation sequences exist, the sequence with more insertions is prioritized. The authors experimented with other prioritization strategies (e.g., prioritizing deletions, random, introducing replacement operations), but found that prioritizing insertions yielded the best results.
The model uses 100-dimensional GloVe vectors to initialize word vectors and edit label embeddings, 30-dimensional vectors to initialize position embeddings, and uses inverse frequency of the edit labels as loss weights to balance the loss contributions from each label.
The results are not very impressive. In terms of metrics, the model does not outperform non-editing methods, and while human evaluation shows some improvement, it is subjective. Ablation studies do not show significant improvements.
LaserTagger
- LaserTagger also uses the three operations: retention, deletion, and insertion, but it incorporates BERT, with Google's engineering capabilities enabling an acceleration factor of 100-200 times.
- Contributions:
- Introduced the model and proposed a method for generating label dictionaries from data.
- Proposed two versions based on BERT: one directly uses BERT for tagging, which is faster, and the other uses BERT to initialize a seq2seq encoder, which yields better results.
Text Editing as Tagging
- LaserTagger transforms the text editing problem into a sequence
labeling problem, which consists of three main components:
- Labeling Operations: Instead of using the three basic operations (retain, delete, insert), the labels are divided into two parts: a base tag (B), which includes retain and delete operations, and an added phrase (P), which can take V different values representing inserted fragments (empty space, words, or phrases). The vocabulary for P is built from the training data. The combination of B and P generates the labels, so there are a total of 2V possible labels. Task-specific labels can also be added based on downstream tasks.
- Building the Added Phrase Vocabulary: Constructing the vocabulary is a combinatorial optimization problem. On one hand, we want the vocabulary to be as small as possible; on the other, we want it to cover the most editing scenarios. Finding the perfect solution is NP-hard, so the authors used another approach. For each training pair, they compute the longest common subsequence (LCS) between the input and the target sequence using dynamic programming. The added phrases are derived by subtracting the LCS from the target sequence. These phrases are then ranked by frequency, and the top-k phrases are selected. For public datasets, the top 500 phrases cover 85% of the data.
- Constructing the Label Sequence: This is done using
a greedy approach, matching the shortest phrase to insert for each word,
without the need for dynamic programming.
![gdxc0x.png]() This approach may sometimes result in cases where no edits are made,
which are then filtered out from the training set. The authors argue
that this can also be seen as a form of noise reduction.
This approach may sometimes result in cases where no edits are made,
which are then filtered out from the training set. The authors argue
that this can also be seen as a form of noise reduction. - Editing the Sentence Based on Predictions: This is the direct operation where, based on downstream tasks, special labels may be predicted to perform task-specific operations. The authors argue that modularizing the editing operations makes the model more flexible than an end-to-end approach.

Experiment
- There are two versions of the model: one directly uses BERT for tagging, and the other uses seq2seq with a BERT-initialized encoder. In the first case, a transformer block is added to BERT’s last layer to perform the tagging.
- Four tasks were tested: sentence fusion, sentence splitting and rephrasing, summarization, and grammar correction. All tasks outperformed the baseline, with sentence fusion achieving new SOTA results. However, LaserTagger's standout performance lies in its efficiency, achieving up to 200 times acceleration with just the BERT encoder (since the text generation is reduced to a sequence labeling task with a small dictionary). It is also very friendly for few-shot learning.
- The authors also analyzed common issues with seq2seq models and
editing-based models, their respective advantages, and the causes of
these problems:
- Imaginary Words: seq2seq models may generate non-existent words at the subword level, whereas LaserTagger does not have this problem.
- Premature Termination: seq2seq models may prematurely generate EOS tokens, resulting in incomplete or overly short sentences. While this is theoretically possible for LaserTagger, the authors have not observed it in practice, as it would require predicting many deletion operations, which are rare in the training data.
- Repetitive Phrases: In sentence splitting tasks, seq2seq models often repeat phrases, while LaserTagger tends to avoid splitting or uses a "lazy split."
- Hallucination: Both models may generate text that is unrelated or counterfactual, but seq2seq models tend to hide this issue more effectively (appearing fluent but actually illogical), while LaserTagger is more transparent.
- Coreference Resolution: Both models struggle with coreference resolution. Seq2seq models may incorrectly replace pronouns with the wrong noun, while LaserTagger may fail to resolve pronouns properly.
- Error Deletion: While LaserTagger appears more controllable in terms of text generation, it still sometimes deletes words, leaving the remaining sentence fluent but incorrect in meaning.
- Lazy Split: In sentence splitting tasks, LaserTagger might only split the sentence without performing any post-processing on the resulting sentences.
PIE
- PIE also combines BERT with sequence labeling, while constructing a phrase dictionary from the data.
- The editing operations include copying (retaining), insertion, deletion, and morphological transformation (for grammar correction).
- Constructing the phrase dictionary, ground truth editing operations, and the method are quite similar to LaserTagger.
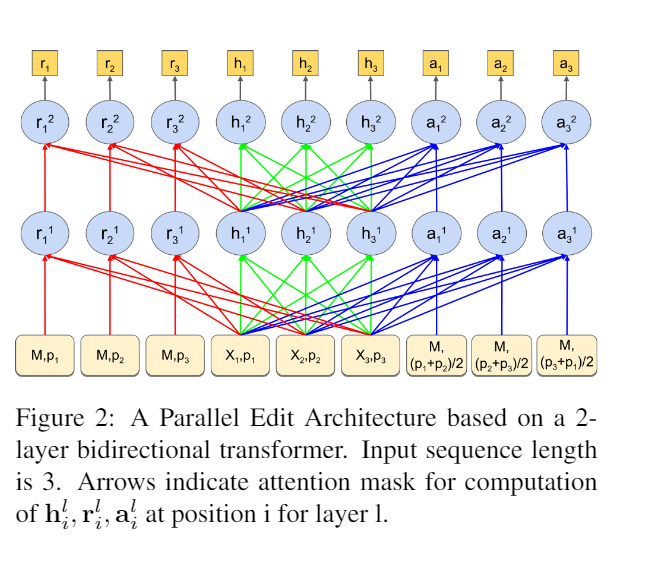
- BERT is extended on both sides with two additional components to
obtain the information required for replacement or insertion:
- The input layer includes M for mask identifiers (embedding), p for positional embeddings, and X for word embeddings.
- h represents the original BERT information, containing both word and positional information.
- r represents replacement information, where the word at the current position is masked and replaced by M, and attention is not applied to the current word's h during the calculation.
- a represents insertion information, where the current word is masked
and replaced by M, and the positional embedding p is replaced by the
average positional embedding of neighboring tokens.
![gwZarT.png]()
- Afterward, the three types of information are used to compute the
probabilities for different operations, which are then normalized. CARDT
represents the operations: copy (retain), insert, replace, delete, and
morphological transformation.
![gwZ5IH.png]()
- The first term in the formula is the score for each editing operation. The second term is the score for retaining the current word, with deletion and replacement not contributing to the score. Other operations are parameterized using the word embedding \(\phi(x_i)\), though the exact meaning of \(\phi\) is unclear. The third term represents the effect of new words, which is only relevant for replacement and insertion.
- Inference also involves multiple rounds of editing (output becoming input), stopping when a repeated sentence is produced.
- The motivation behind the design of the editing operations is not fully clear, and the final results are quite average. Only under ensemble settings does PIE perform on par with a Transformer + Pre-training + LM + Spellcheck + Ensemble Decoding model. Ablation studies show that pre-trained models are the main contributor to performance improvement.
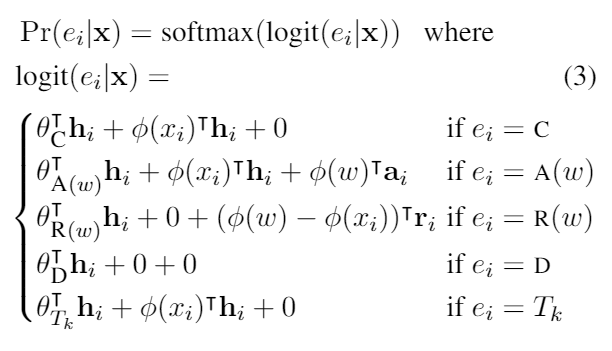
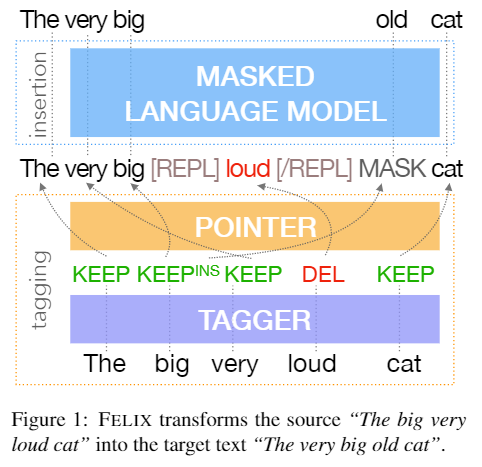
Felix
- Felix divides the editing operations into two non-autoregressive parts: first, a Transformer-based pointer network performs tagging and reordering, inserting placeholders; second, a masked language model (MLM) predicts the words for the placeholders.
- The design of Felix considers three needs:
- Flexible editing, suitable for various text generation tasks.
- Efficient utilization of pre-trained models like BERT.
- Efficient inference.
![gwKovR.png]()
- The diagram below clearly shows the tagging design of Felix, where
y^t represents the editing operation sequence predicted by the
tagging model, and y^m represents the intermediate sequence
after inserting special tokens (REPL, MASK) based on the editing
operation sequence. This intermediate sequence is then fed to the MLM to
predict the words that need to be inserted, resulting in the final
prediction.
![gwMHzj.md.png]()
- Two points to note:
- Although the MLM only predicts the insertion of words, it still requires the full editing operation information. Instead of simply deleting the words predicted for deletion, the authors use REPL to bracket the span that should be deleted, providing the MLM with information about the deletions.
- The diagram shows two forms of Mask and Infill, which involve different masking strategies for the intermediate sequence and deciding who is responsible for tasks like multi-token insertion. In the Mask approach, the task is handled by the tagging model, which directly predicts multi-word insertions (e.g., \(DEL^{INS\_2}\) for inserting two words, corresponding to two MASK tokens in the intermediate sequence). In the Infill approach, the task is handled by the MLM, where four MASK tokens are prepared for each insertion position, with extra tokens predicted as PAD.
- To model more flexibly, the tagging model also performs reordering, as swapping two words requires first deleting and then adding them, which increases complexity. The reordering is handled using pointer network attention, which directs each word to its subsequent word, with the first word indicated by a special CLS token. During inference, controlled beam search is used to avoid cyclical pointer sequences.
- Compared to LaserTagger, Felix performs better in terms of performance and small sample learning, and it does not suffer from the limitations of phrase vocabulary. The authors also performed experiments on phrase vocabulary and reordering, with results available in the original paper.

Summary
Here's a summary of the key models with their editing operations, performance, and tasks:
| Model | Editing Operations | Acceleration | Multiple Word Insertion | Ground Truth Construction | Editing Failure | Test Tasks |
|---|---|---|---|---|---|---|
| LevT | Insert, Delete | Multi-round non-autoregressive, 5x | Predict placeholder count first, then replace | Dynamic programming based on edit distance | Degrades to text generation | Translation, Summarization |
| EditNTS | Insert, Delete, Retain | Autoregressive, acceleration not mentioned | Stay at position for insertion until done | Dynamic programming based on edit distance | Degrades to text generation | Text Simplification |
| LaserTagger | Insert, Delete, Retain | One-round sequence labeling, 100+ times | Direct insertion of phrases, phrase vocabulary built from training data | Greedy matching | No editing (lazy) | Sentence Fusion, Sentence Splitting and Paraphrasing, Summarization, Grammar Correction |
| PIE | Insert, Delete, Replace, Copy, Morphological Transformation | Sequence labeling, 2x | Direct insertion of phrases, phrase vocabulary built from training data | Greedy matching | Not specified | Grammar Correction |
| Felix | Delete, Insert, Retain, Reordering | Tagging + MLM, faster than LaserTagger | Use multiple masks for MLM to predict | Simple comparison | Poor MLM prediction | Sentence Fusion, Post-processing in Machine Translation, Summarization, Text Simplification |
This table gives an overview of each model's characteristics, strengths, and weaknesses across different editing operations and tasks.