ML Basic Practices
Introduction
In November 2016, the decision was made to start delving into machine learning. Initially, I followed the official example on the Kaggle platform for the first task, "Titanic Survivor Analysis."
2017 February Update: Data was reorganized using pandas, detailed accuracy was calculated, and Linear Regression from scikit-learn was tested
Title Introduction is here: Titanic: Machine Learning from Disaster
Below is the dataset table style, each person has 12 attributes

Not an Algorithm Algorithm
The official example is to classify by several attributes, such as age, gender, ticket price (.....) and then sum up the survival data (0 or 1) for all individuals within each attribute to calculate the average. The English comments are all explanations from the official documentation; I used them as an introductory tutorial and included them all. The code is as follows:
# -*- coding: utf-8 -*-
"""
Created on Sun Oct 30 15:28:22 2016
@author: thinkwee
"""
import csv as csv
import numpy as np
from glue import qglue
test_file=(open(r'文件目录略', 'r'))
test_file_object = csv.reader(open(r'文件目录略', 'r'))
testheader = next(test_file_object)
predictions_file = open(r"文件目录略", "w")
predictions_file_object = csv.writer(predictions_file)
p = csv.writer(predictions_file)
p.writerow(["PassengerId", "Survived"])
csv_file_object = csv.reader(open(r'文件目录略', 'r'))
trainheader = next(csv_file_object) # The next() command just skips the
# first line which is a header
data=[] # Create a variable called 'data'.
for row in csv_file_object: # Run through each row in the csv file,
data.append(row) # adding each row to the data variable
print(type(data))
data = np.array(data) # Then convert from a list to an array
# Be aware that each item is currently
# a string in this format
number_passengers = np.size(data[0::,1].astype(np.float))
number_survived = np.sum(data[0::,1].astype(np.float))
proportion_survivors = number_survived / number_passengers
women_only_stats = data[0::,4] == "female" # This finds where all
# the elements in the gender
# column that equals “female”
men_only_stats = data[0::,4] != "female" # This finds where all the
# elements do not equal
# female (i.e. male)
# Using the index from above we select the females and males separately
women_onboard = data[women_only_stats,1].astype(np.float)
men_onboard = data[men_only_stats,1].astype(np.float)
# Then we finds the proportions of them that survived
proportion_women_survived = \
np.sum(women_onboard) / np.size(women_onboard)
proportion_men_survived = \
np.sum(men_onboard) / np.size(men_onboard)
# and then print it out
print ('Proportion of women who survived is %s' % proportion_women_survived)
print ('Proportion of men who survived is %s' % proportion_men_survived)
# The script will systematically will loop through each combination
# and use the 'where' function in python to search the passengers that fit that combination of variables.
# Just like before, you can ask what indices in your data equals female, 1st class, and paid more than $30.
# The problem is that looping through requires bins of equal sizes, i.e. $-9, undefined-29, $30-39.
# For the sake of binning let's say everything equal to and above 40 "equals" 39 so it falls in this bin.
# So then you can set the bins
# So we add a ceiling
fare_ceiling = 40
# then modify the data in the Fare column to = 39, if it is greater or equal to the ceiling
data[ data[0::,9].astype(np.float) >= fare_ceiling, 9 ] = fare_ceiling - 1.0
fare_bracket_size = 10
number_of_price_brackets = fare_ceiling // fare_bracket_size
# Take the length of an array of unique values in column index 2
number_of_classes = len(np.unique(data[0::,2]))
number_of_age_brackets=8
# Initialize the survival table with all zeros
survival_table = np.zeros((2, number_of_classes,
number_of_price_brackets,
number_of_age_brackets))
#Now that these are set up,
#you can loop through each variable
#and find all those passengers that agree with the statements
for i in range(number_of_classes): #loop through each class
for j in range(number_of_price_brackets): #loop through each price bin
for k in range(number_of_age_brackets): #loop through each age bin
women_only_stats_plus = data[ #Which element
(data[0::,4] == "female") #is a female
&(data[0::,2].astype(np.float) #and was ith class
== i+1)
&(data[0:,9].astype(np.float) #was greater
>= j*fare_bracket_size) #than this bin
&(data[0:,9].astype(np.float) #and less than
< (j+1)*fare_bracket_size)
&(data[0:,5].astype(np.float)>=k*10)
&(data[0:,5].astype(np.float)<(k+1)*10)#the next bin
, 1] #in the 2nd col
men_only_stats_plus = data[ #Which element
(data[0::,4] != "female") #is a male
&(data[0::,2].astype(np.float) #and was ith class
== i+1)
&(data[0:,9].astype(np.float) #was greater
>= j*fare_bracket_size) #than this bin
&(data[0:,9].astype(np.float) #and less than
< (j+1)*fare_bracket_size)#the next bin
&(data[0:,5].astype(np.float)>=k*10)
&(data[0:,5].astype(np.float)<(k+1)*10)
, 1]
survival_table[0,i,j,k] = np.mean(women_only_stats_plus.astype(np.float))
survival_table[1,i,j,k] = np.mean(men_only_stats_plus.astype(np.float))
#if nan then the type will change to string from float so this sentence can set nan to 0.
survival_table[ survival_table != survival_table ] = 0.
#Notice that data[ where function, 1] means
#it is finding the Survived column for the conditional criteria which is being called.
#As the loop starts with i=0 and j=0,
#the first loop will return the Survived values for all the 1st-class females (i + 1)
#who paid less than 10 ((j+1)*fare_bracket_size)
#and similarly all the 1st-class males who paid less than 10.
#Before resetting to the top of the loop,
#we can calculate the proportion of survivors for this particular
#combination of criteria and record it to our survival table
#In the official example, probabilities greater than 0.5 are considered survivors,
#here we skip it directly
#Print detailed probabilities
#survival_table[ survival_table < 0.5 ] = 0
#survival_table[ survival_table >= 0.5 ] = 1
#Then we can make the prediction
for row in test_file_object: # We are going to loop
# through each passenger
# in the test set
for j in range(number_of_price_brackets): # For each passenger we
# loop thro each price bin
try: # Some passengers have no
# Fare data so try to make
row[8] = float(row[8]) # a float
except: # If fails: no data, so
bin_fare = 3 - float(row[1]) # bin the fare according Pclass
break # Break from the loop
if row[8] > fare_ceiling: # If there is data see if
# it is greater than fare
# ceiling we set earlier
bin_fare = number_of_price_brackets-1 # If so set to highest bin
break # And then break loop
if row[8] >= j * fare_bracket_size\
and row[8] < \
(j+1) * fare_bracket_size: # If passed these tests
# then loop through each bin
bin_fare = j # then assign index
break
for j in range(number_of_age_brackets):
try:
row[4] = float(row[4])
except:
bin_age = -1
break
if row[4] >= j * 10\
and row[4] < \
(j+1) * 10: # If passed these tests
# then loop through each bin
bin_age = j # then assign index
break
if row[3] == 'female': #If the passenger is female
p.writerow([row[0], "%f %%" % \
(survival_table[0, int(row[1])-1, bin_fare,bin_age]*100)])
else: #else if male
p.writerow([row[0], "%f %%" % \
(survival_table[1, int(row[1])-1, bin_fare,bin_age]*100)])
# Close out the files.
test_file.close()
predictions_file.close()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
***
# Multivariate Linear Regression
After buying the watermelon book, I changed this example to a linear regression model:
Assume that each person's survival may be linearly related to the person's gender, price, cabin, and age,
we use the least squares method to find a set of linear coefficients,
so that the distance between all samples and the linear function is minimized
Use mean squared error as performance measurement, mean squared error is a function of linear coefficients
Derivative of linear coefficients w can get the closed-form solution of w
The key formula is
** $$ w^*=(X^TX)^{-1}X^Ty $$ **
- X:data set matrix, each row corresponds to a person's data, and a 1 is added at the end of each row,
if the training set has m people and n attributes, the matrix size is m*(n+1)
- w:linear coefficients
- y:survival result $$ y=w^T*x $$
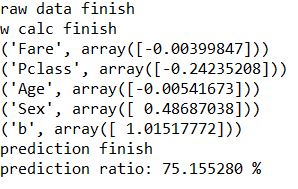
When writing, all missing values in age were deleted, 891 data were given, 193 were used to verify the calculation accuracy, and the final accuracy was 75.155280 %
The code is as follows
```Python
train1=train.dropna(subset=(['Age']),axis=0)
vali1=vali.dropna(subset=(['Age']),axis=0)
validata=np.array(vali1)
data=np.array(train1)
fare_ceiling = 40
data[data[0::,9].astype(np.float)>=fare_ceiling,9] = fare_ceiling - 1.0
train = np.column_stack((data[0::,9],data[0::,2],data[0::,5],data[0::,4]))
predict=np.column_stack((validata[0::,9],validata[0::,2],validata[0::,5],validata[0::,4]))
survive = np.column_stack((data[0::,1]))
for i in range(train.shape[0]):
if (train[i][3]=='male'):
train[i][3]=0.00
else:
train[i][3]=1.00
for i in range(predict.shape[0]):
if (predict[i][3]=='male'):
predict[i][3]=0.00
else:
predict[i][3]=1.00
x0=np.ones((train.shape[0],1))
train=np.concatenate((train,x0),axis=1)
x0=np.ones((predict.shape[0],1))
predict=np.concatenate((predict,x0),axis=1)
print('raw data finish')
survive=survive.T.astype(np.float)
traint=train.T.astype(np.float)
w0=traint.dot(train.astype(np.float))
w1=(np.linalg.inv(w0))
w2=w1.dot(traint)
w=w2.dot(survive) #w=(Xt*X)^-1*Xt*y
print('w calc finish')
feature=['Fare','Pclass','Age','Sex','b']
for i in zip(feature,w):
print(i)
valipredict_file_object.writerow(["PassengerName", "Actual Survived","Predict Survived","XO"])
count=0.0
for i in range(predict.shape[0]):
temp=predict[i,0::].T.astype(float)
answer=temp.dot(w)
answer=answer[0]
if ((answer>0.5 and validata[i][1]==1) or (answer<0.5 and validata[i][1]==0)):
flag="Correct"
count=count+1.0;
else:
flag="Error"
valipredict_file_object.writerow([validata[i][3],validata[i][1],answer,flag])
print("prediction finish")
print("prediction ratio:","%f %%"%(count/predict.shape[0]*100))
* * *
Multivariate Linear Regression in scikit-learn
==============================================
Experimented with scikit, added several attributes, with the same data, but some attributes seem not very good, resulting in the accuracy dropping to 64.375000 %.

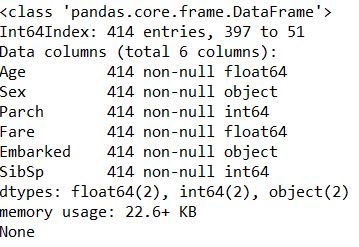
If errors occur during the model fitting stage, please check if there are any empty elements, infinite elements, or inconsistent lengths of attributes in the x, y dataset you are fitting, and you can use info() to get an overview
train=train.dropna(subset=['Age','Embarked'],axis=0)
vali=vali.dropna(subset=(['Age','Embarked']),axis=0)
train.loc[train["Sex"]=="male","Sex"]=0
train.loc[train["Sex"]=="female","Sex"]=1
train.loc[train["Embarked"] == "S", "Embarked"] = 0
train.loc[train["Embarked"] == "C", "Embarked"] = 1
train.loc[train["Embarked"] == "Q", "Embarked"] = 2
trainx=train.reindex(index=train.index[:],columns=['Age']+['Sex']+['Parch']+['Fare']+['Embarked']+['SibSp'])
vali.loc[vali["Sex"]=="male","Sex"]=0
vali.loc[vali["Sex"]=="female","Sex"]=1
vali.loc[vali["Embarked"] == "S", "Embarked"] = 0
vali.loc[vali["Embarked"] == "C", "Embarked"] = 1
vali.loc[vali["Embarked"] == "Q", "Embarked"] = 2
vali1=vali.reindex(index=vali.index[:],columns=['Age']+['Sex']+['Parch']+['Fare']+['Embarked']+['SibSp'])
survive=vali.reindex(index=vali.index[:],columns=['Survived'])
survive=np.array(survive)
feature=['Age','Sex','Parch','Fare','Embarked','SibSp']
trainy=train.reindex(index=train.index[:],columns=['Survived'])
trainy=trainy.Survived
X_train, X_test, y_train, y_test = train_test_split(trainx, trainy, random_state=1)
model=LinearRegression()
model.fit(X_train,y_train)
print(model)
for i in zip(feature,model.coef_):
print(i)
predict=model.predict(vali1)
count=0
for i in range(len(predict)):
if (predict[i]>1 and survive[i] == 1) or (predict[i]<1 and survive [i]== 0 ):
count=count+1.0
print("prediction finish")
print("prediction ratio:","%f %%"%(count/len(predict)*100))
{% endlang_content %}
{% lang_content zh %}
***
# 不是算法的算法
官方示例就是按几个属性分类,比如年龄,性别,票价(.....)
然后对每个属性内所有人的生还数据(0或者1)加一起求平均。
英文注释都是官方文档的说明
我就当入门教程学了,也全打了上去
代码如下:
```Python
# -*- coding: utf-8 -*-
"""
Created on Sun Oct 30 15:28:22 2016
@author: thinkwee
"""
import csv as csv
import numpy as np
from glue import qglue
test_file=(open(r'文件目录略', 'r'))
test_file_object = csv.reader(open(r'文件目录略', 'r'))
testheader = next(test_file_object)
predictions_file = open(r"文件目录略", "w")
predictions_file_object = csv.writer(predictions_file)
p = csv.writer(predictions_file)
p.writerow(["PassengerId", "Survived"])
csv_file_object = csv.reader(open(r'文件目录略', 'r'))
trainheader = next(csv_file_object) # The next() command just skips the
# first line which is a header
data=[] # Create a variable called 'data'.
for row in csv_file_object: # Run through each row in the csv file,
data.append(row) # adding each row to the data variable
print(type(data))
data = np.array(data) # Then convert from a list to an array
# Be aware that each item is currently
# a string in this format
number_passengers = np.size(data[0::,1].astype(np.float))
number_survived = np.sum(data[0::,1].astype(np.float))
proportion_survivors = number_survived / number_passengers
women_only_stats = data[0::,4] == "female" # This finds where all
# the elements in the gender
# column that equals “female”
men_only_stats = data[0::,4] != "female" # This finds where all the
# elements do not equal
# female (i.e. male)
# Using the index from above we select the females and males separately
women_onboard = data[women_only_stats,1].astype(np.float)
men_onboard = data[men_only_stats,1].astype(np.float)
# Then we finds the proportions of them that survived
proportion_women_survived = \
np.sum(women_onboard) / np.size(women_onboard)
proportion_men_survived = \
np.sum(men_onboard) / np.size(men_onboard)
# and then print it out
print ('Proportion of women who survived is %s' % proportion_women_survived)
print ('Proportion of men who survived is %s' % proportion_men_survived)
# The script will systematically will loop through each combination
# and use the 'where' function in python to search the passengers that fit that combination of variables.
# Just like before, you can ask what indices in your data equals female, 1st class, and paid more than $30.
# The problem is that looping through requires bins of equal sizes, i.e. $0-9, $10-19, $20-29, $30-39.
# For the sake of binning let's say everything equal to and above 40 "equals" 39 so it falls in this bin.
# So then you can set the bins
# So we add a ceiling
fare_ceiling = 40
# then modify the data in the Fare column to = 39, if it is greater or equal to the ceiling
data[ data[0::,9].astype(np.float) >= fare_ceiling, 9 ] = fare_ceiling - 1.0
fare_bracket_size = 10
number_of_price_brackets = fare_ceiling // fare_bracket_size
# Take the length of an array of unique values in column index 2
number_of_classes = len(np.unique(data[0::,2]))
number_of_age_brackets=8
# Initialize the survival table with all zeros
survival_table = np.zeros((2, number_of_classes,
number_of_price_brackets,
number_of_age_brackets))
#Now that these are set up,
#you can loop through each variable
#and find all those passengers that agree with the statements
for i in range(number_of_classes): #loop through each class
for j in range(number_of_price_brackets): #loop through each price bin
for k in range(number_of_age_brackets): #loop through each age bin
women_only_stats_plus = data[ #Which element
(data[0::,4] == "female") #is a female
&(data[0::,2].astype(np.float) #and was ith class
== i+1)
&(data[0:,9].astype(np.float) #was greater
>= j*fare_bracket_size) #than this bin
&(data[0:,9].astype(np.float) #and less than
< (j+1)*fare_bracket_size)
&(data[0:,5].astype(np.float)>=k*10)
&(data[0:,5].astype(np.float)<(k+1)*10)#the next bin
, 1] #in the 2nd col
men_only_stats_plus = data[ #Which element
(data[0::,4] != "female") #is a male
&(data[0::,2].astype(np.float) #and was ith class
== i+1)
&(data[0:,9].astype(np.float) #was greater
>= j*fare_bracket_size) #than this bin
&(data[0:,9].astype(np.float) #and less than
< (j+1)*fare_bracket_size)#the next bin
&(data[0:,5].astype(np.float)>=k*10)
&(data[0:,5].astype(np.float)<(k+1)*10)
, 1]
survival_table[0,i,j,k] = np.mean(women_only_stats_plus.astype(np.float))
survival_table[1,i,j,k] = np.mean(men_only_stats_plus.astype(np.float))
#if nan then the type will change to string from float so this sentence can set nan to 0.
survival_table[ survival_table != survival_table ] = 0.
#Notice that data[ where function, 1] means
#it is finding the Survived column for the conditional criteria which is being called.
#As the loop starts with i=0 and j=0,
#the first loop will return the Survived values for all the 1st-class females (i + 1)
#who paid less than 10 ((j+1)*fare_bracket_size)
#and similarly all the 1st-class males who paid less than 10.
#Before resetting to the top of the loop,
#we can calculate the proportion of survivors for this particular
#combination of criteria and record it to our survival table
#官方示例中将概率大于0.5的视为生还,这里我们略过
#直接打印详细概率
#survival_table[ survival_table < 0.5 ] = 0
#survival_table[ survival_table >= 0.5 ] = 1
#Then we can make the prediction
for row in test_file_object: # We are going to loop
# through each passenger
# in the test set
for j in range(number_of_price_brackets): # For each passenger we
# loop thro each price bin
try: # Some passengers have no
# Fare data so try to make
row[8] = float(row[8]) # a float
except: # If fails: no data, so
bin_fare = 3 - float(row[1]) # bin the fare according Pclass
break # Break from the loop
if row[8] > fare_ceiling: # If there is data see if
# it is greater than fare
# ceiling we set earlier
bin_fare = number_of_price_brackets-1 # If so set to highest bin
break # And then break loop
if row[8] >= j * fare_bracket_size\
and row[8] < \
(j+1) * fare_bracket_size: # If passed these tests
# then loop through each bin
bin_fare = j # then assign index
break
for j in range(number_of_age_brackets):
try:
row[4] = float(row[4])
except:
bin_age = -1
break
if row[4] >= j * 10\
and row[4] < \
(j+1) * 10: # If passed these tests
# then loop through each bin
bin_age = j # then assign index
break
if row[3] == 'female': #If the passenger is female
p.writerow([row[0], "%f %%" % \
(survival_table[0, int(row[1])-1, bin_fare,bin_age]*100)])
else: #else if male
p.writerow([row[0], "%f %%" % \
(survival_table[1, int(row[1])-1, bin_fare,bin_age]*100)])
# Close out the files.
test_file.close()
predictions_file.close()
多元线性回归
之后买了西瓜书,我把这个例题改成了线性回归模型: 假设每一个人生还可能与这个人的性别,价位,舱位,年龄四个属性成线性关系, 我们就利用最小二乘法找到一组线性系数,是所有样本到这个线性函数直线上的距离最小 用均方误差作为性能度量,均方误差是线性系数的函数 对线性系数w求导,可以得到w最优解的闭式
关键公式是 ** \[ w^*=(X^TX)^{-1}X^Ty \] **
- X:数据集矩阵,每一行对应一个人的数据,每一行最后添加一个1, 假如训练集有m个人,n个属性,则矩阵大小为m*(n+1)
- w:线性系数
- y:生还结果 \[ y=w^T*x \]
写的时候把年龄中缺失值全删除了,官方给了891条数据,我分了193条用于验证计算正确率,最后正确率是75.155280 %

代码如下
1 | train1=train.dropna(subset=(['Age']),axis=0) |
scikit-learn中的多元线性回归
试了一下scikit,增加了几个属性,一样的数据,但是好像有些属性不太好,导致正确率下降至64.375000 %

如果再模型的fit阶段出现错误,请检查你fit的x,y数据集是否出现了空元素,无限大元素,或者各个属性的长度不一致,可以用info()做一个概览

1 | train=train.dropna(subset=['Age','Embarked'],axis=0) |