Pandas Basics
Using the data from the Titanic as an example, introduce the basic operations performed on the data in the early stages.
Introducing the library
import csv as csv
import pandas as pd
import numpy as npRead file
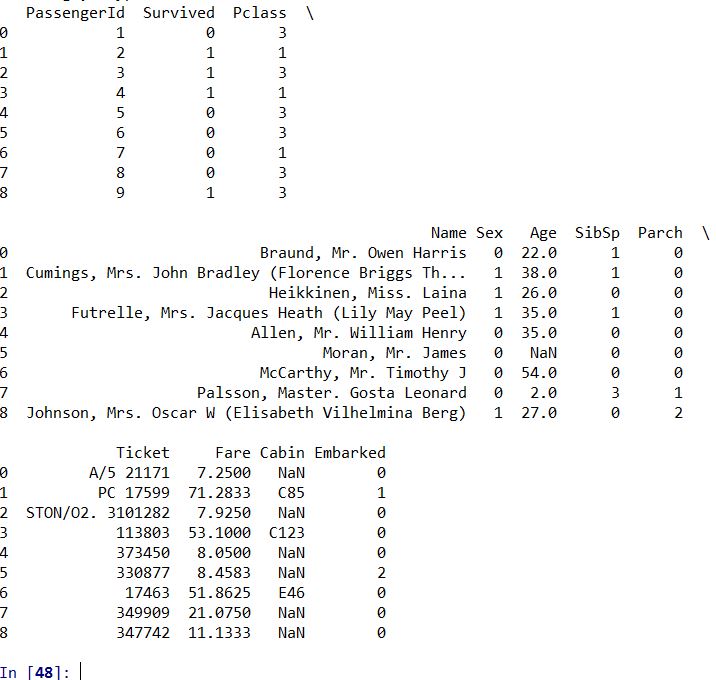
train = pd.read_csv(r"文件目录") At this moment, the style of the data is: 
or Data Overview
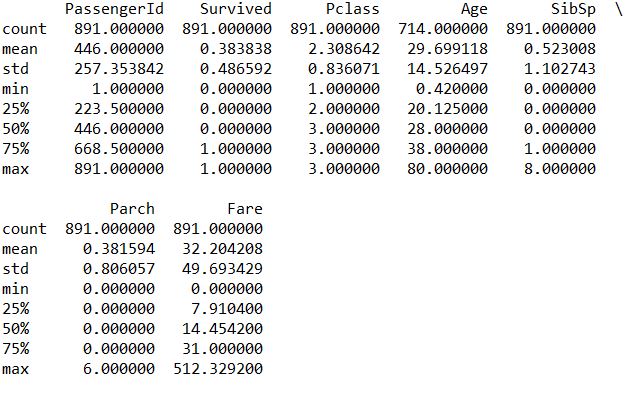
describe the common attributes of the overall data display
print(train.describe())![i0TP3V.jpg]()
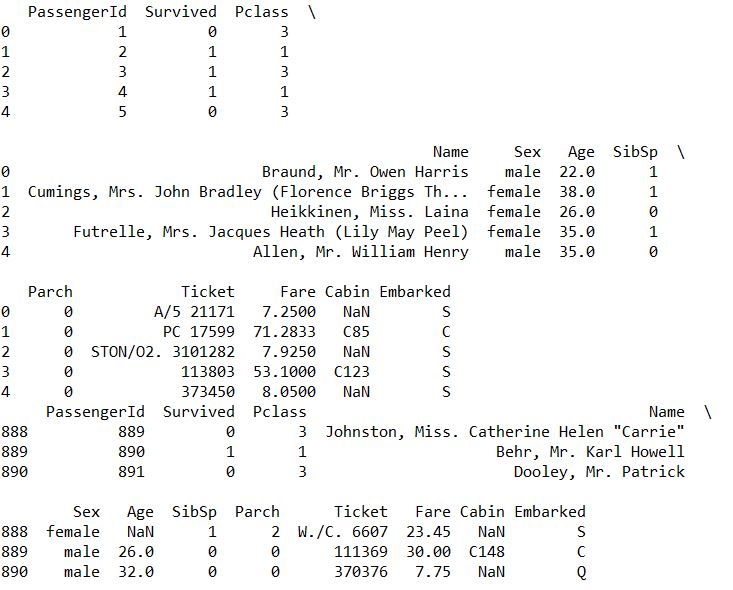
head tail display some data at the beginning and end
print(train.head(5)) print(train.tail(3))![i0TFjU.jpg]()
index: index, default built-in integer index; columns: columns; values: data values
print(train.index) print(train.columns) print(train.values)Data Manipulation
Data Transposition
print(train.T)![i0TAuF.jpg]()
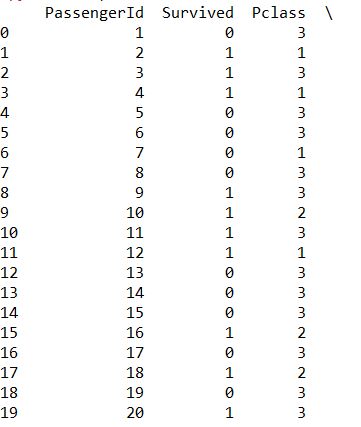
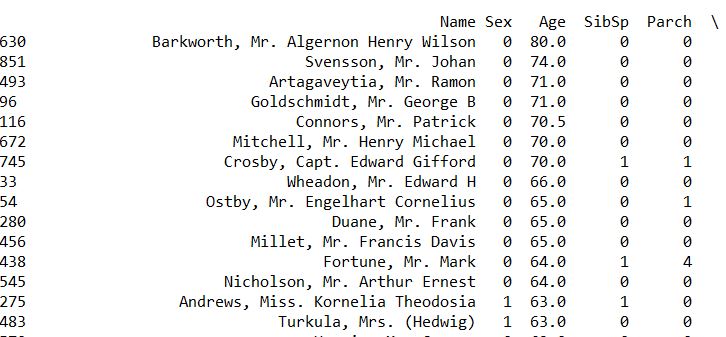
sort: Can be sorted by index or value, axis selects the dimension (row or column), ascending selects ascending or descending order, and NaN is always placed at the end, regardless of ascending or descending order
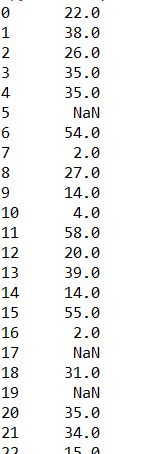
print(train.sort_index(axis=0,ascending=True)) print(train.sort_values(by="Age",ascending=False))![i0TEB4.jpg]()
![i0TmNR.jpg]()

Data Selection
Select by tag, select columns, row slicing
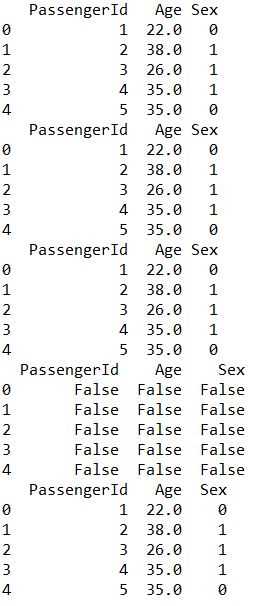
print(train['Age']) print(train[0:9])![i0TVHJ.jpg]()
![i0TeE9.jpg]()
Utilize loc to freely select certain rows and columns; at can be used instead
print(train.loc[train.index[4:6]]) print(train.loc[:,['Age','Fare']]) print(train.loc[3:5,['Age','Fare']]) print(train.loc[4,'Age']) print(train.at[4,'Age'])Using iloc to select by position
print(train.iloc[5]) print(train.iloc[3:5,2:4]) print(train.iloc[[1,2,4],[2,5]]) print(train.iloc[3,3])Boolean selection
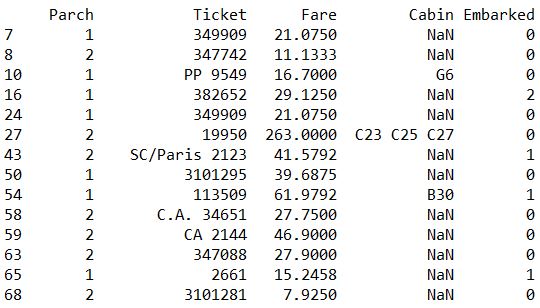
print( train[ (train['Age']>40) & (train['Age']<50) ] ) print(train[train['Parch'].isin([1,2])]) print(train[pd.isnull(train['Age'])==True])![i0TK9x.jpg]()
![i0TM36.jpg]()
![i0TljO.jpg]()


Handling Missing Values
Using reindex to select and copy part of the data, and then handle missing values. Some functions will automatically filter out missing values, such as mean().
train1=train.reindex(index=train.index[0:5],columns=['PassengerId']+['Age']+['Sex'])#选择前5行,只取选定的三列 print(train1) print(train1.dropna(axis=0)) #删除存在nan值的行 print(train1.dropna(subset=['Age','Sex'])) #删除年龄性别列中存在nan值的行 print(pd.isnull(train1)) #nan值改为true,其余值改为false print(train1.fillna(value=2333)) #缺失值替换为2333![i0TcUs.jpg]()
Applied Functions
Can write functions and apply them to the rows or columns of data, selecting rows or columns through the axis parameter
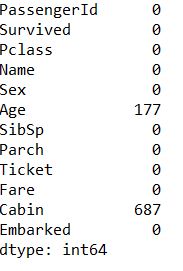
#写函数统计包含nan值的行数 def null_count(column): column_null=pd.isnull(column) null=column[column_null == True] return len(null) print(train.apply(null_count))![i0TQgK.jpg]()
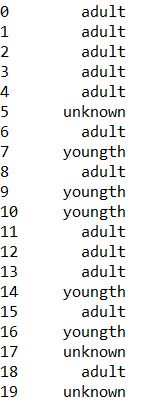
#写函数对年龄列进行分类 def judge(row): if pd.isnull(row['Age']) ==True: return 'unknown' return 'youngth' if row['Age']<18 else 'adult' print(train.apply(judge,axis=1))![i07jFs.jpg]()
Data 透视表
Select categories and values for data pivot, such as categorizing by pclass and sex, and calculating the average age and fare
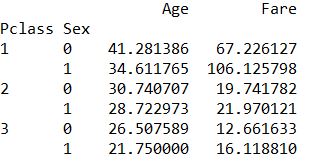
print(train.pivot_table(index=["Pclass","Sex"], values=["Age", "Fare"], aggfunc=np.mean))![i0T3uD.jpg]()
Data merging
Some operations of data merging, to be completed
import pandas as pd data1 = pd.DataFrame({'level':['a','b','c','d'], 'numeber':[1,3,5,7]}) data2=pd.DataFrame({'level':['a','b','c','e'], 'numeber':[2,3,6,10]}) print("merge:\n",pd.merge(data1,data2),"\n") data3 = pd.DataFrame({'level1':['a','b','c','d'], 'numeber1':[1,3,5,7]}) data4 = pd.DataFrame({'level2':['a','b','c','e'], 'numeber2':[2,3,6,10]}) print("merge with left_on,right_on: \n",pd.merge(data3,data4,left_on='level1',right_on='level2'),"\n") print("concat: \n",pd.concat([data1,data2]),"\n") data3 = pd.DataFrame({'level':['a','b','c','d'], 'numeber1':[1,3,5,np.nan]}) data4=pd.DataFrame({'level':['a','b','c','e'], 'numeber2':[2,np.nan,6,10]}) print("combine: \n",data3.combine_first(data4),"\n")![i0T8De.jpg]()
