Notes for ML

Notes on some concepts and algorithms in machine learning, sourced from:
- Elective Course on Pattern Recognition (An elective course for third-year students at Beijing University of Posts and Telecommunications, Pattern Recognition, textbook is “Pattern Recognition” compiled by Zhang Xuegong, published by Tsinghua University Press)
- Watermelon Book
- Statistical Learning Methods
- Deep Learning (Translated in Chinese: exacity/deeplearningbook-chinese)
Update:
2017-02-12 Overview Update
2017-03-01 Update k-Nearest Neighbors
2017-03-08 Update SVM
2018-01-04 Update of fundamental knowledge of machine learning and mathematical knowledge in the book “Deep Learning”
2018-08-09 The content of Statistical Learning Methods has been posted in another article titled “Handwritten Notes on Statistical Learning Methods,” and it is estimated that it will not be updated anymore. Later, some remaining contents in “Deep Learning” may be updated
Introduction to Statistical Learning Methods
Statistical Learning, Supervised Learning, Three Elements
- If a system can improve its performance by executing a certain process, that is learning
- The methods of statistical learning are based on constructing statistical models from data for the purpose of prediction and analysis
- Obtain the training dataset; determine the hypothesis space containing all possible models; establish the criteria for model selection; implement the algorithm for solving the optimal model; select the optimal model through learning methods; use the optimal model for predicting or analyzing new data
- The task of supervised learning is to learn a model that can make a good prediction for the corresponding output of any given input
- Each specific input is an instance, typically represented by a feature vector. It constitutes a feature space, with each dimension corresponding to a feature.
- Supervised learning learns a model from a training dataset, which consists of input-output pairs (samples)
- Supervised learning learns a model from a training set, represented as a conditional probability distribution or a decision function
- Statistical Learning Three Elements: Method = Model + Strategy + Algorithm. The model includes probabilistic models (conditional probability) and non-probabilistic models (decision functions); the strategy refers to the method of selecting the optimal model, introducing the concepts of loss function (cost function) and risk function, and realizing the optimization of empirical risk or structural risk; the algorithm refers to the specific computational method for learning the model.
Loss function is used to measure the degree of error between the predicted values and the true values, common ones include: 0-1 loss function, squared loss function, absolute loss function, logarithmic loss function, denoted as $L(Y,P(Y|X))$ , risk function (expected loss) is the average loss below the joint distribution of the model:
, empirical risk (empirical loss) is the average loss of the model about the training set:
Ideally, expected risk can be estimated using empirical risk, however, when the sample size is small, minimizing empirical risk is prone to overfitting, thus the concept of structural risk (regularization) is proposed:
, where J(f) represents the complexity of the model, and the coefficient $\lambda$ is used to weigh the empirical risk and model complexity. ML belongs to empirical risk minimization, while MAP belongs to structural risk minimization.
Model evaluation, model selection
- The error of the model on the training set and the test set is respectively called training error and test error. The loss function used may not be consistent, and making them consistent is ideal
- Overfitting: Learning too much, the complexity of the model is higher than the real model, performing well on the learned data but poor in predicting unknown data. To avoid overfitting, the correct number of features and the correct feature vectors are required.
- Two methods for model selection: regularization and cross-validation
Regularization, cross-validation
- Add a regularization term (penalty) to the empirical risk, with higher penalties for more complex models
- The general method is to randomly divide the dataset into three parts: the training set, the validation set, and the test set, which are used respectively for training data, selecting models, and finally evaluating the learning method. Cross-validation involves repeatedly randomly splitting the data into training and test sets, learning multiple times, and conducting testing and model selection.
- Cross-validation types: Simple cross-validation; S-fold cross-validation; Leave-one-out cross-validation
Generalization ability
- Generalization error: Error in predicting unknown data
- Generalization error upper bound is generally a function of the sample size; as the sample size increases, the upper bound of generalization tends to 0. This implies that the larger the hypothesis space capacity, the harder the model is to learn, and the larger the upper bound of the generalization error
- For binary classification problems, the upper bound of generalization error: where d is the capacity of the function set, for any function, at least with probability $1-\delta$
Generative model, discriminative model
- The generation method is based on learning the joint probability distribution of data, and then calculating the conditional probability distribution as the predictive model, i.e., the generative model, such as the Naive Bayes method and the Hidden Markov Model
- Discriminant methods learn decision functions or conditional probability distributions directly from data as predictive models, i.e., discriminant models, such as k-nearest neighbors, perceptrons, decision trees, logistic regression models, maximum entropy models, support vector machines, boosting methods, and conditional random fields, etc
- The generation method can recover the joint probability distribution, has a fast learning convergence speed, and is suitable for cases with latent variables
- High accuracy of discrimination methods, capable of abstracting data, and simplifying learning problems
Categorization, annotation, regression
Categorization, which takes discrete finite values as output, is also known as a classification decision function or classifier
For binary classification, the total number of four cases: correctly predicted as correct TP; correctly predicted as incorrect FN; incorrectly predicted as correct FP; incorrectly predicted as incorrect TN
Annotation: Input an observation sequence, output a marked sequence
Regression: Function fitting, the commonly used loss function is the squared loss function, which is fitted using the least squares method
k-Nearest Neighbors method
k-Nearest Neighbors method
- k-Nearest Neighbor method assumes that a training dataset is given, with instances of predetermined categories. In classification, for new instances, predictions are made based on the categories of the k nearest training instances, through majority voting or other methods.
- k-value selection, distance measurement, and classification decision rules are the three elements of the k-nearest neighbor method.
- k-Nearest Neighbor is a lazy learning method; it does not train the samples.
k-Nearest Neighbors algorithm
For new input instances, find the k nearest instances to the instance in the training dataset, and if the majority of these k instances belong to a certain class, classify the instance into that class. That is:
When $y_i=c_i$ is $I=1$ , the neighborhood $N_k(x)$ consists of k nearest neighbor points covering x.
When k=1, it is called the nearest neighbor algorithm
k-nearest neighbor algorithm does not have an explicit learning process
k-Nearest Neighbors model
k-nearest neighbor model refers to the partitioning of the feature space.
In the feature space, for each training instance point, all points closer to this point than others form a region called a unit. Each training instance point has a unit, and the units of all training instance points constitute a partition of the feature space, with the class of each instance being the class label of all points within its unit.
Distance metrics include: Euclidean distance, $L_p$ distance, Minkowski distance.
The Euclidean distance is a special case of the $L_p$ distance (p=2), and when p=1, it becomes the Manhattan distance, defined as:
k value is small, approximation error is small, estimation error is large, the overall model is complex, prone to overfitting. k value is large, estimation error is small, approximation error is large, the model is simple
Generally, the cross-validation method is used to determine the value of k
The majority voting rule is equivalent to empirical risk minimization
k-d tree
- kd-tree is a special structure used to store training data, which improves the efficiency of k-nearest neighbor search, which is essentially a binary search tree
- Each node of the k-d tree corresponds to a k-dimensional hyperrectangle region
- Method for constructing a balanced kd-tree: Divide by taking the median of each dimension sequentially, for example, in three dimensions, first draw a line at the median of the x-axis, divide it into two parts, then draw a line at the median of the y-axis for each part, and then along the z-axis, and then cycle through x, y, z.
- After the construction of the kd-tree is completed, it can be used for k-nearest neighbor searches. The following uses the nearest neighbor search as an example, where k=1:
- Starting from the root node, recursively search downwards to the area where the target point is located, until reaching the leaf nodes
- Taking this leaf node as the current nearest point, the distance from the current nearest point to the target point is the current nearest distance, and our goal is to search the tree to find a suitable node to update the current nearest point and the current nearest distance
- Recursive upward rollback, perform the following operation on each node
- If the instance point saved by the node is closer to the target point than the current nearest point, update the instance point to the current nearest point, and update the distance from the instance point to the target point to the current nearest distance
- The child nodes of this node are divided into two, one of which contains our target point. This part we have come from the target point all the way up recursively, and it has been updated. Therefore, we need to find the other child node of this node to see if it can be updated: Check if the corresponding area of the other child node intersects with the hypersphere centered at the target point and with the current shortest distance as the radius. If they intersect, move to this child node and continue the upward search; if they do not intersect, do not move and continue the upward search.
- Until the root node is searched, the current nearest point at this time is the nearest neighbor of the target point.
- The computational complexity of k-d tree search is $O(logN)$ , suitable for k-nearest neighbor search when the number of training instances is much larger than the number of spatial dimensions
Support Vector Machine
Linearly separable support vector machine and hard margin maximization
The goal of learning is to find a separating hyperplane in the feature space that can distribute instances into different classes (binary classification). The separating hyperplane corresponds to the equation $wx+b=0$ , determined by the normal vector w and the intercept b, and can be represented by (w, b)
Here, x is the feature vector $(x_1,x_2,…)$ , and y is the label of the feature vector
Given a linearly separable training dataset, the separating hyperplane learned by maximizing the margin or solving the equivalent convex quadratic programming problem, denoted as $wx+b=0$ , and the corresponding classification decision function denoted as $f(x)=sign(wx+b)$ , is called a linearly separable support vector machine
Under the determination of the hyperplane $wx+b=0$ , the distance from the point (x,y) to the hyperplane can be
Whether the symbol of $wx+b$ is consistent with the symbol of class label y indicates whether the classification is correct, $y=\pm 1$ , thus obtaining the geometric distance
Simultaneously define the relative distance as the function interval
Hard margin maximization is for linearly separable hyperplanes, while soft margin maximization is for approximately linearly separable cases
Finding a hyperplane with the maximum geometric margin, which can be represented as the following constrained optimization problem
We can convert geometric intervals into functional intervals, which has no effect on optimization. Moreover, if we fix the relative interval as a constant (1), the maximization of the geometric interval can be transformed into the minimization of $||w||$ , thus the constrained optimization problem can be rewritten as
The above equation is the basic form of SVM, and when the above optimization problem is solved, we obtain a separating hyperplane with the maximum margin, which is the maximum margin method
The maximum margin separating hyperplane exists and is unique, proof omitted
In the linearly separable case, the instances of the nearest sample points to the separating hyperplane in the training dataset are called support vectors
For the positive example points of $y_i=1$ , the support vectors lie on the plane $wx+b=1$ , similarly, the negative example points lie on the plane $wx+b=-1$ . These two planes are parallel and there are no training data points between them. The distance between the two planes is the margin, which depends on the normal vector w of the separating hyperplane, as $\frac 2 {||w||}$
Thus, it can be seen that support vector machines are determined by a very small number of important training samples (support vectors)
To solve the optimization problem, we introduce the dual algorithm and also introduce kernel functions to generalize to nonlinear classification problems
To be supplemented
Linear Algebra Basics
Moore-penrose
For non-square matrices, their inverse matrix is undefined, therefore we specially define the pseudoinverse of non-square matrices: Moore-Penrose pseudoinverse
The actual algorithms for computing the pseudo-inverse do not base themselves on this definition, but rather use the following formula:
U, D, and V are the matrices obtained from the singular value decomposition of matrix A, which are diagonal matrices. The pseudo-inverse $D^+$ of the diagonal matrix D is obtained by taking the reciprocal of its non-zero elements and then transposing.
When the number of columns of matrix A exceeds the number of rows, using the pseudoinverse to solve the linear equation is one of many possible methods. Particularly, $x = A^+y$ is the one with the smallest Euclidean norm among all feasible solutions to the equation.
When the number of rows of matrix A exceeds the number of columns, there may be no solution. In this case, the pseudo-inverse $x$ obtained minimizes the Euclidean distance between $Ax$ and $y$ .
To be supplemented
迹
-
Trace operation returns the sum of the diagonal elements of the matrix.
Using trace operations, the matrix Frobenius norm can be described as:
Trace has transposition invariance and permutation invariance
The trace of a scalar is its own
PCA Explanation
- To be supplemented
Probability Theory and Information Theory
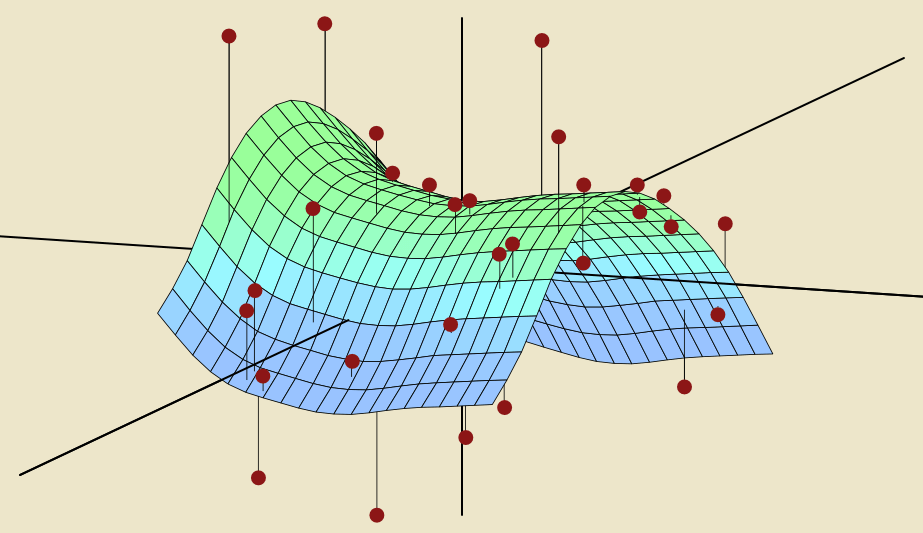
Logistic Sigmoid
Logistic and sigmoid are often used interchangeably, this function is used to compress real numbers into the interval (0,1), representing binary classification probabilities:
Softmax is an extension of the sigmoid, being a smoothed version of the argmax function (argmax returns a one-hot vector while softmax returns probabilities for various possible outcomes), extending binary classification to the multi-class (disjoint) case:
Both exhibit saturation phenomena when the input is too large or too small, but when the two functions are introduced as nonlinear activation units in a neural network, because the cost function takes the negative logarithm, this saturation phenomenon can be eliminated.
Softmax function, due to the inclusion of exponential functions, also has issues with underflow and overflow. When the input is uniformly distributed and the number of input samples is large, the denominator exponential values approach 0, and the summation may also approach 0, leading to underflow in the denominator. Overflow can also occur when the parameters of the exponential function are large. The solution is to process the input x as z = x - max(xi), that is, subtracting the maximum component from each component of the vector. Adding or subtracting a scalar from the input vector does not change the softmax function values (redundancy of the softmax function), but at this point, the maximum value of the processed input is 0, excluding overflow. After the exponential function, at least one term in the summation of the denominator exists as 1, excluding underflow.
Utilizing the redundancy of the softmax function can also deduce that sigmoid is a special case of softmax:
![i0HRXT.png]()
KL divergence and cross-entropy
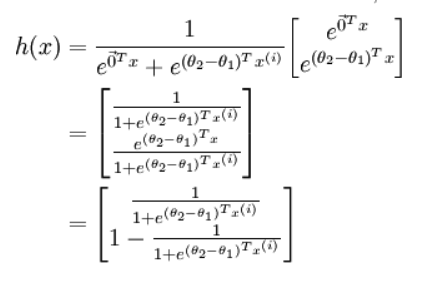
KL divergence: A measure of the difference between two distributions, PQ, non-negative and asymmetric:
Cross-entropy:
The cross-entropy form is simple, and the minimization of KL divergence with respect to Q (actual output) is unrelated to the first term in the divergence formula, therefore, minimizing KL divergence can actually be seen as minimizing cross-entropy. Moreover, since KL divergence represents the difference between PQ (actual output and correct output), it can be regarded as a loss function
In dealing with binary classification problems using logistic regression, q(x) refers to the logistic function, and p(x) refers to the actual distribution of the data (either 0 or 1)
The expected self-information of q with respect to p, i.e., the binary cross-entropy (Logistic cost function):
Similarly, we can obtain the multi-class cross-entropy (Softmax cost function):
Cross-entropy and maximum log-likelihood relationship
Given a sample dataset X with distribution $P{data}(x)$ , we aim to obtain a model $P{model}(x,\theta)$ whose distribution is as close as possible to $P{data}(x)$ . $P{model}(x,\theta)$ maps any x to a real number to estimate the true probability $P{data}(x)$ . In $P{model}(x,\theta)$ , the maximum likelihood estimate of $\theta$ is the $\theta$ that maximizes the product of probabilities obtained by the model for the sample data:
Because taking the logarithm and scaling transformation does not change argmax, taking the logarithm transforms it into a summation and then dividing by the sample size to average it yields:
It can be observed that the above expression is the negative of the cross-entropy, and its value is maximized when Pdata(x) = Pmodel(x,θ), so:
Maximum likelihood = minimum negative log-likelihood = minimizing cross-entropy = minimizing KL divergence = minimizing the gap between data and model = minimizing the cost function
Maximum likelihood estimation can be extended to maximum conditional likelihood estimation, which constitutes the foundation of most supervised learning: Formula:
Maximum likelihood estimation is consistent.
Computational Method
Gradient Descent
- How to transform parameters (inputs) to make the function smaller (minimize the cost function)?
- The principle is that moving the input in the opposite direction of the derivative by a small step can reduce the function’s output.
- Extend the input to vector-form parameters, treat the function as a cost function, and thus obtain a gradient-based optimization algorithm.
- First-order optimization algorithm: including gradient descent, using the Jacobian matrix (including the relationship between partial derivatives of vectors), and updating the suggested parameter updates through gradient descent:
![i0opQO.png]()
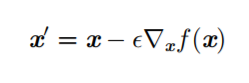
Newton’s Method
- Second-order optimization algorithm (求最优补偿,定性临界点): First-order optimization requires adjusting the appropriate learning rate (step size), otherwise it cannot reach the optimal point or will produce shaking, and it cannot update the parameters at the critical point (gradient is 0), which reflects the need for second-order derivative information of the cost function, for example, when the function is convex or concave, the predicted value based on the gradient and the true value of the cost function have a deviation. The Hessian matrix contains second-order information. Newton’s method uses the information of the Hessian matrix, uses the second-order Taylor expansion to obtain the function information, and updates the parameters using the following formula:
![i0o9yD.png]()
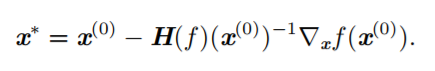
Constraint Optimization
Only contains equality constraint conditions: Lagrange
Inequality constraint conditions: KTT
Modify algorithm
Modify the hypothesis space
Machine learning algorithms should avoid overfitting and underfitting, which can be addressed by adjusting the model capacity (the ability to fit various functions).
Adjusting the model capacity involves selecting an appropriate hypothesis space (assuming input rather than parameters), for example, previously only fitting polynomial linear functions:
If nonlinear units, such as higher-order terms, are introduced, the output remains linearly distributed relative to the parameters:
This increases the model’s capacity while simplifying the generated parameters, making it suitable for solving complex problems; however, a too high capacity may also lead to overfitting.
Regularization
No free lunch theorem (after averaging over all possible data generation distributions, each classification algorithm has the same error rate on points that have not been observed beforehand) indicates that machine learning algorithms should be designed for specific tasks, and algorithms should have preferences. Adding regularization to the cost function introduces preferences, causing the learned parameters to be biased towards minimizing the regularization term.
An example is weight decay; the cost function with the addition of the weight decay regularization term is:
λ controls the preference degree, and the generated models tend to have small parameters, which can avoid overfitting.