Multi-agent Reinforcement Learning Notes

A simple note on the RL used in single-agent and multi-agent.
Sequential Decision Making
- Modeling agents in sequential decision making problems, rather than just single-step or one-shot decision problems.
- Discuss a sequential decision problem in:
- A fully observable stochastic environment
- With a Markov transition model
- Additive rewards Typically includes a set of states, a set of actions, a transition model, and a reward function. The solution to the problem is the policy.
- If the sequence has no time limit, and the optimal policy only depends on the state, independent of time, it is called a stationary policy.
Bellman Equation, U and Q Functions
The value function represents the cumulative reward of a state/action sequence, such as U(s0,a0,s1,a0....), starting from the current state and action s0,a0.
The value is defined by an additive discount, where future rewards are discounted by gamma:
\[ U\left(\,\left[s_{0},\,s_{1},\,s_{2},\,\cdots\,\right]\,\right)=R(s_{0})+\gamma R(s_{1})+\gamma ^2 R(s_{2})+\,\cdots \]
- Because recent rewards are more important.
- If rewards can be invested, earlier rewards have higher value.
- This is equivalent to each transition having a \(1-\gamma\) chance of unexpected termination.
- Satisfies stationarity, meaning the best action at time t+1 is the same as the best action at time t in the future.
- Prevents infinite sequence transitions.
Based on the value function, the best action can be selected at each state, i.e., the action that maximizes the current value (instantaneous reward + expected discounted future value):
There is an expectation here, as each action can lead to different future states (with probability), so the value of an action is the sum of its expected value over all possible future states.
The value function is only a function of the state, as it has already accumulated the expectation over all actions:
\[ \pi^*(s) = \underset{a \in A(s)}{\text{argmax}} \sum_{s^{'}} P(s^{'}|s,a)[R(s,a,s^{'}) + \gamma U(s^{'})] \]
Similarly, the value function is only a function of the state, and has already accumulated the expectation over all actions. This is essentially the same as the previous formula, but without the argmax to select actions; instead, it's a max, as the agent assumes the best action is taken. The interpretation is: if the agent selects the best action, the state value is the expected reward of the next transition plus the discounted value of the next state:
\[ U(s) = \underset{a \in A(s)}{\text{max}} \sum_{s^{'}} P(s^{'}|s,a)[R(s,a,s^{'}) + \gamma U(s^{'})] \]
- Note that these two formulas are essentially the same; both involve selecting actions and summing over all possible states, but this is based on an estimate of the future expectation. The actual execution is choosing an action and transitioning to a state.
- This equation is the Bellman Equation.
Introduce the Q-function, which is a function of both action and state, while U is just a function of state. The relationship between them is as follows:
\[ U(s) = \underset{a \in A(s)}{\text{max}} Q(s,a) \]
Similarly, the Bellman equation can be written for the Q-function:
\[ Q(s,a) = \sum_{s^{'}} P(s^{'}|s,a)[R(s,a,s^{'}) + \gamma Q(s^{'},a^{'})] \]
Note that the above discussion focuses on the optimal value function and optimal Q-function, both using max, meaning they compute the return under the optimal policy, as opposed to on-policy value functions and Q-functions, which calculate the expected return.
Reward Shaping
The reward function R can be modified (without changing the optimal policy) to stabilize the reinforcement learning process.
- Constraints: Avoid agent exploitation of reward.
- Exploration: Encourage exploration.
- Acceleration: Improve sparse reward situations by breaking tasks down into smaller sub-tasks, making it easier for the agent to learn.
A common modification is the introduction of a potential function.
A potential function is a state-only function \(\Phi(s)\) (unlike the value function, it is independent of action/state sequences and does not result from removing actions).
The potential function encodes the objective environmental factors that influence the rewards.
It can be proven that a potential function can be any arbitrary function of state s, and when added to the immediate reward, the optimal policy derived from the Bellman equation remains unchanged. Specifically, when the reward function is modified as:
\[ R^{'}(s,a,s^{'}) = R(s,a,s^{'}) + \gamma \Phi(s^{'}) - \Phi(s) \]
The optimal policy remains unchanged, \(Q(s,a)=Q^{'}(s,a)\).
Solving MDPs
Value Iteration
With n states, there are n equations and n unknowns in the Bellman equation. The analytical solution of nonlinear equations is difficult, but an iterative method can be used. Starting with random initial values, each state's value is updated based on neighboring states' values until equilibrium is reached.
Introduce an iteration timestep i, the Bellman update (Bellman Update) is as follows:
\[ U_{i+1}(s) \leftarrow \underset{a \in A(s)}{\text{max}} \sum_{s^{'}} P(s^{'}|s,a)[R(s,a,s^{'}) + \gamma U_i(s^{'})] \]
It can be proven that infinite iterations will guarantee convergence to the optimal solution (assuming the immediate rewards are correct).
Policy Iteration
Sometimes we do not need to compute the exact value function, just the action that yields the maximum value. This leads to the idea of directly iterating and optimizing the policy.
Starting with an initial policy, the following two steps are alternated:
- Policy Evaluation: Given a policy, compute the value of each state under the policy at a particular timestep.
- Policy Improvement: Calculate a new policy based on the value function (using the Bellman equation) for all states.
The process continues until policy improvement does not result in a significant change in the value function.
Policy evaluation is also based on the Bellman equation, but we do not need to traverse actions since they are determined by the policy. By fixing the current policy \(\pi_i\) at timestep i, we obtain n equations, which can be solved:
\[ U_{i}(s) = \sum_{s^{'}} P(s^{'}|s,\pi_i(s))[R(s,\pi_i(s),s^{'}) + \gamma U_i(s^{'})] \]
When the state space is large, solving it exactly becomes difficult. In this case, a modified policy iteration can be used for policy evaluation, where the value function for the next timestep is computed directly from the current policy and iterated repeatedly:
\[ U_{i+1}(s) \leftarrow \sum_{s^{'}} P(s^{'}|s,\pi_i(s))[R(s,\pi_i(s),s^{'}) + \gamma U_i(s^{'})] \]
The above method is synchronous, meaning all states are updated at each iteration. In fact, we can update only a subset of states, which is called asynchronous policy iteration.
- The advantage is that we can focus on updating strategies for certain effective states, as some states may not reach an optimal solution regardless of the action taken.
Linear Programming
- TBD
Online Algorithms
- Value iteration and policy iteration are offline methods: given all conditions/rewards, the optimal solution is computed, and the agent executes it.
- Online algorithms: The agent does not receive an offline solution and execute it. Instead, it computes decisions in real-time at each decision point.
Slot Machine Problem
- TBD
POMDP
- Partially Observable Markov Decision Process
- Since the agent is uncertain about its current state (the definition
of partial observability), a belief state is introduced, and the agent’s
decision-making cycle has an additional step:
- Act based on the belief state.
- Perceive observations (evidence).
- Update the belief state based on the perception, action, and previous belief state through some updating mechanism.
- In physical state space, solving POMDP can be simplified to solving the MDP in the belief state space.
- Value iteration for POMDPs.
Single Agent RL
- The agent is in an MDP but does not know the transition model or reward function and needs to take actions to learn more information.
- The sequential decision-making problem above assumes a known environment and optimal policy derivation. However, in general reinforcement learning, the environment is unknown, and the agent learns the optimal policy through interaction with the environment.
- Model-based Methods:
- The environment provides a transition model or initially an unknown model that needs to be learned.
- Typically, a value function is learned, defined as the total reward accumulated from state s.
- The sequential decision-making problems discussed above
are often solved through value iteration or policy iteration in a model-based manner. - Model-free Methods: - The environment is not known beforehand and needs to be learned. Instead of computing and using a model, the agent computes and learns the value function or policy. - Model-free approaches are often simpler to implement than model-based methods but may require more interactions with the environment. Examples: - Q-learning - SARSA - Monte Carlo methods.
Passive Reinforcement Learning
- The policy is fixed, and the value function is learned.
- The policy is fixed, for example, a greedy approach that selects the action with the maximum value. In this case, the Q-function only needs to be learned, and the optimal action under the fixed policy will emerge.
- This is similar to policy evaluation (where, given a policy, the value of each state at a particular time step is computed), but the agent doesn't know the transition probabilities between states or the immediate rewards after taking an action.
Direct Value Estimation
- The value of a state is defined as the expected total reward (reward-to-go) from that state.
- Each trial will leave a sample of the value for the states it passes through (multiple visits to the same state will provide multiple samples).
- This way, samples are collected, and supervised learning can be used to map states to values.
- However, this method ignores an important constraint: the value of a state should satisfy the Bellman equation for the fixed policy, i.e., the value of the state is related to the reward and expected value of the successor states, not just its own value.
- Ignoring this will lead to a larger search space and slow convergence.
Adaptive Dynamic Programming (ADP)
- The agent learns the transition model between states and uses dynamic programming to solve the MDP.
- In a fully observable or deterministic environment, the agent continually runs trials to gather data, then trains a supervised model that takes the current state and action as inputs and outputs the transition probabilities (the transition model).
- After obtaining the transition model, the agent can solve the MDP using sequence decision methods, correcting the policy iteratively.
- ADP requires the agent to trial continuously, gather historical data with reward signals, and then learn the environment's transition model, which transforms the problem into a known sequence decision problem.
- ADP can be seen as an extension of policy iteration in the passive reinforcement learning setting.
Temporal Difference Learning
In the passive reinforcement learning setting, where a policy \(\pi\) is given, if the agent takes action \(\pi(s)\) from state \(s\) and transitions to state \(s^{'}\), the value function is updated using the temporal difference equation:
\[ U^{\pi}(s) \leftarrow U^{\pi}(s) + \alpha (R(s,\pi(s),s^{'}) + \gamma U^{\pi}(s^{'}) - U^{\pi}(s)) \]
Here, \(\alpha\) is the learning rate. Compared to Bellman, temporal difference updates the value based on the observed difference between the value of state \(s\) and the reward plus discounted future value of state \(s^{'}\):
The difference term provides error information, and the update reduces this error.
The modified formula shows that the value of the state is updated using interpolation between the current value and the reward + future discounted value:
\[ U^{\pi}(s) \leftarrow (1-\alpha)U^{\pi}(s) + \alpha (R(s,\pi(s),s^{'}) + \gamma U^{\pi}(s^{'})) \]
Connection and difference with adaptive dynamic programming:
- Both adjust the current value based on future estimates, but ADP uses a weighted sum over all possible successor states, while temporal difference only uses the observed successor state.
- ADP aims for as many adjustments as possible to ensure consistency between the value estimate and the transition model, while TD makes a single adjustment based on the observed transition.
- TD can be seen as an approximation of ADP:
- TD can use the transition model to generate multiple pseudo-experiences, rather than relying only on the actual observed transition, leading to value estimates that are closer to ADP.
- Prioritized sweeping updates states that are highly probable and recently had large adjustments in their successor states.
- One advantage of TD as an approximation of ADP is that early on, the transition model may not be accurate, so learning an exact value function to match the transition model is less meaningful.
Active Reinforcement Learning
- The policy needs to be learned.
- A complete transition model needs to be learned, taking into account all possible actions since the policy is not fixed (unknown).
- Consider whether, after learning the optimal policy, simply executing it is always the right action.
Introducing Exploration
- Adaptive dynamic programming is greedy, so exploration needs to be introduced.
- A broad design would introduce an exploration function \(f(u, n)\), where a higher value \(u\) encourages greediness, and fewer trials \(n\) encourage exploration.
TD Q-learning
A temporal difference method for active reinforcement learning.
No model of the transition probabilities is required (model-free method).
The agent learns the action-value function to avoid needing the transition model itself:
\[ Q(s,a) \leftarrow Q(s,a) + \alpha (R(s,a,s^{'}) + \gamma \max_{a^{'}}Q(s^{'},a^{'}) - Q(s,a)) \]
No transition model \(P(s'|s,a)\) is needed.
Since no policy is provided, we need to take the max over all possible actions.
Learning is difficult when rewards are sparse.
Sarsa
Sarsa stands for state, action, reward, state, action, and represents the update rule for this five-tuple:
\[ Q(s,a) \leftarrow Q(s,a) + \alpha (R(s,a,s^{'}) + \gamma Q(s^{'},a^{'}) - Q(s,a)) \]
Compared to TD Q-learning, it does not take the max over all possible actions, but instead updates based on the action actually taken.
If the agent is greedy and always selects the action with the highest Q-value, then Sarsa and Q-learning are equivalent. If not greedy, Sarsa penalizes actions that encounter negative rewards during exploration.
On/Off Policy:
- Sarsa is on-policy: "If I stick to my policy, what is the value of this action at this state?"
- Q-learning is off-policy: "If I stop following my current policy and instead use an estimated optimal policy, what is the value of this action at this state?"
Generalization in Reinforcement Learning
- Both the value function and the Q-function are stored in table form, and the state space is large.
- If they can be parameterized, the number of parameters to be learned can be greatly reduced.
- In passive reinforcement learning, supervised learning can be used to learn the value function based on trials, and functions or neural networks can be used to parameterize this.
- In temporal difference learning, the difference term can be parameterized and learned through gradient descent.
- There are several issues with parameterizing and approximating the
value or Q-function:
- Difficulty in convergence.
- Catastrophic forgetting: This can be mitigated by experience replay, where trajectories are saved and replayed to ensure that value functions for states not currently visited remain accurate.
- Reward function design, how to address sparse rewards?
- Issue: credit assignment, which action should be credited for the final positive or negative reward?
- Reward shaping can help by providing intermediate rewards; potential functions are one example, reflecting progress towards partial goals or measurable distances from the final desired state.
- Another approach is hierarchical reinforcement learning, TBD.
Policy Search
Adjust the policy as long as there is improvement in performance.
A policy is a function mapping states to actions.
If the policy is parameterized, it can be optimized. However, optimizing the Q-function doesn't necessarily lead to the optimal value estimate or Q-function because policy search only cares whether the policy is optimal.
Directly learning Q-values and then using argmax to derive the policy can lead to discrete, non-differentiable issues. In this case, Q-values are treated as logits, and softmax is used to represent action probabilities, with techniques like Gumbel-Softmax ensuring the policy is continuously differentiable.
If the expected reward from executing the policy can be written as a parameterized expression, policy gradient methods can be used for direct optimization. Otherwise, the expression can be computed by observing accumulated rewards during policy execution and optimized using experience gradients.
For the simplest case where only one action is taken, the policy gradient can be written as:
\[ \triangledown_{\theta}\sum_a R(s_0,a,s_0)\pi_{\theta}(s_0,a) \]
This sum can be approximated using samples generated from the policy’s probability distribution, and extended to sequential states, resulting in the REINFORCE algorithm. Here, the policy probability weighted sum is approximated over N trials, and the single-step reward is extended to a value function, with states extended to the entire state space of the environment:
\[ \frac{1}{N} \sum_{j=1}^N \frac{u_j(s) \triangledown_{\theta}\pi_{\theta}(s,a_j)}{\pi_{\theta}(s,a_j)} \]
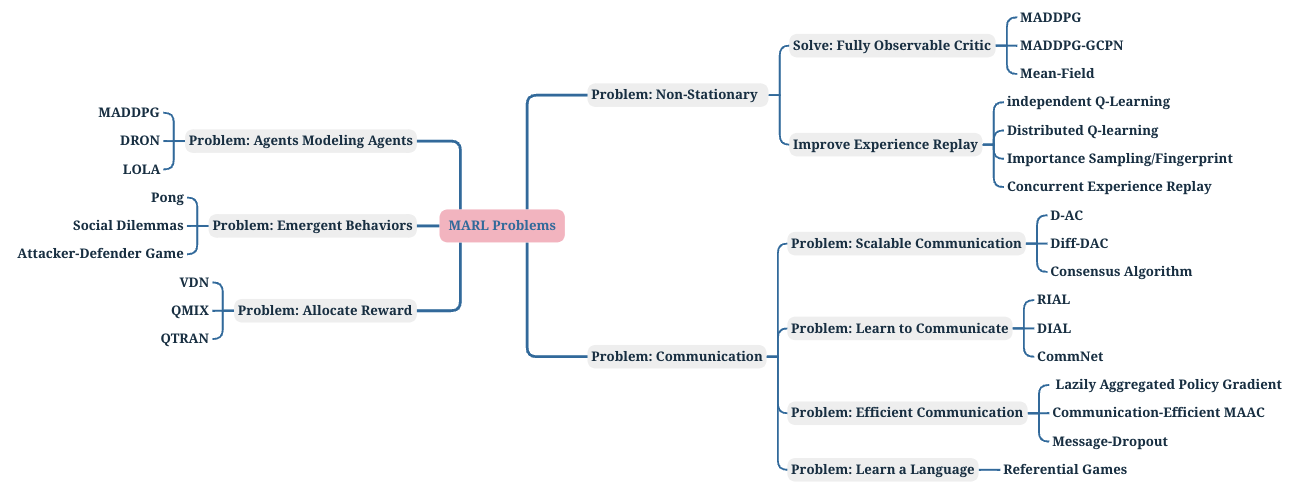
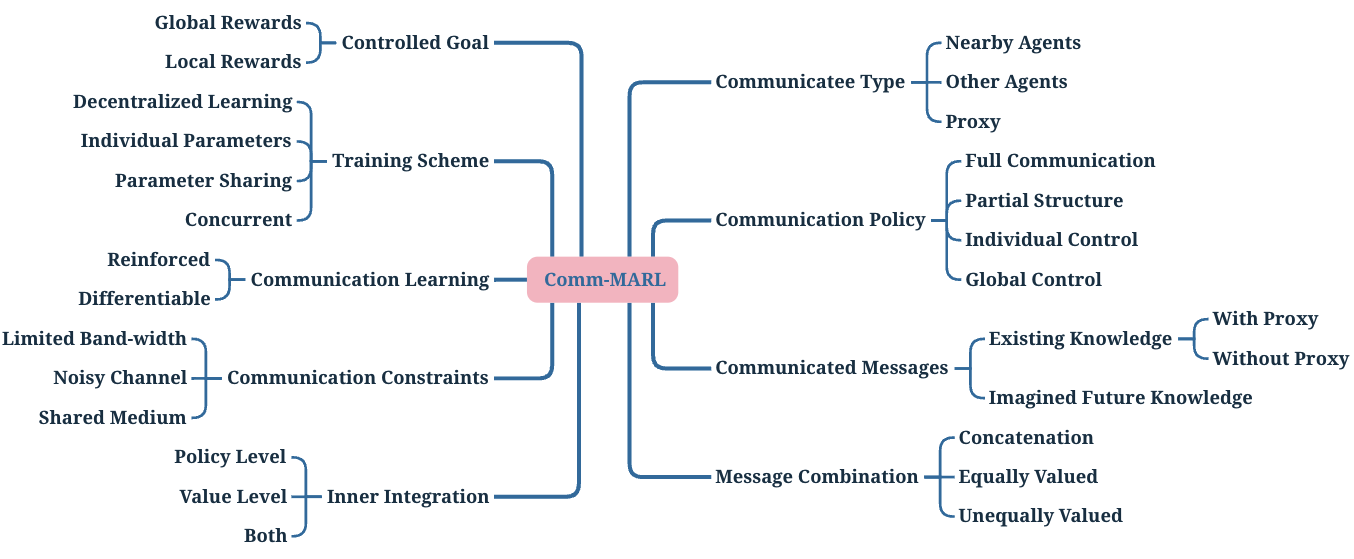
MARL (Multi-Agent Rl)
- TBD
![]()
![]()
![]()
![]()