Note for Inference Algorithms in Probabilistic ML

Record the principles and derivations of algorithms used for inferring unknown variables in probabilistic machine learning, such as Variational Inference, Expectation Maximization, and Markov Chain Monte Carlo. Many contents and derivations, as well as images, come from the online course and lecture notes of Professor Xu Yida at the University of Technology Sydney. Professor Xu’s series of videos on non-parametric Bayesian methods are very good, and you can find the videos by searching his name on Bilibili or Youku. The address of Professor Xu’s course notes is roboticcam/machine-learning-notes. Unless otherwise specified, some screenshots and code are from Professor Xu’s lecture notes. Other contents come from various books or tutorials, and the references will be indicated in the text.
Bayesian Inference
- In Bayesian inference, it is necessary to distinguish observable quantities (data) from unknown variables (which may be statistical parameters, missing data, or latent variables)
- Statistical parameters are regarded as random variables in the Bayesian framework, and we need to make probabilistic estimates of the model’s parameters. In the frequentist framework, parameters are determined and non-random quantities, mainly used for probabilistic estimates of the data
- In the frequentist framework, only the likelihood is focused on $p(x|\theta)$ , while the Bayesian school believes that the parameters $\theta$ should be treated as variables, making prior assumptions about the parameters $p(\theta)$ before observing the data
- Posterior proportionality to the product of likelihood and prior, representing the parameter probability distribution we obtain after adjusting the prior for the observed data
- In the Bayesian framework, we are more concerned with precision, which is the reciprocal of variance, for example, in the posterior of a normal distribution, precision is the sum of the precision of the prior and the data
- The posterior is actually a balance between the maximum likelihood estimation and the prior
- As the amount of data increases, the posterior gradually ceases to depend on the prior
- Many times, we do not have prior knowledge, in which case a flat, dispersed distribution is generally used as the prior distribution, such as a uniform distribution with a wide range or a normal distribution with a large variance
- Sometimes we do not need to know the entire posterior distribution but only make some point estimates or interval estimates
Markov Chain Monte Carlo
- MCMC, the first MC stands for how to sample so that the sampling points satisfy the distribution, and the second MC stands for using random sampling to estimate the parameters of the distribution
- Maximum likelihood estimation and the EM algorithm are both point estimations, while MCMC finds the complete posterior distribution through sampling
- Monte Carlo simple sampling is known for its distribution, but it is not possible to directly calculate certain statistics of functions on this distribution. Therefore, statistics are indirectly calculated by generating samples through random sampling of this distribution and then using the samples to compute the statistics
- Monte Carlo inference involves an unknown distribution and known samples (data), where the distribution is inferred from the samples (question mark pending determination)
Sampling
It is difficult (or the distribution is unknown) to derive some statistical quantities directly through the distribution function; we can obtain the statistical quantities by generating a series of samples that conform to this distribution and calculating the statistical quantities through sample statistics, i.e., by random sampling
In parameter inference, we can randomly sample a series of samples from the posterior distribution that satisfies the parameters, thereby estimating the parameters based on the samples
The simplest sampling: inverse sampling from the cumulative distribution function, which is first performing a uniform distribution sampling from [0,1], and then using this value as the output of the cdf function; the sampling value is the input to the cdf:
Refuse Sampling
Not all cumulative distribution functions of distributions are easy to invert. Another sampling method is called rejection sampling.
For a probability density function, we cannot sample it directly, so we construct a distribution that is everywhere greater than the probability density function, surrounding this function, as shown in the figure where the red line encloses the green line
![i0oFwd.jpg]()
We calculate the distance of each point to the red line and the green line, dividing it into acceptance and rejection regions. Thus, we first sample from the red distribution to obtain samples, and then perform a [0,1] uniform distribution sampling. If the sample falls within the acceptance region, it is accepted; otherwise, it is rejected
显然红色分布处处比绿色大是不可能的,积分不为 1,因此需要按比例放缩一下,乘以一个系数 M,算法如下:
i=0 while i!= N x(i)~q(x) and u~U(0,1) if u< p(x(i))/Mq(x(i)) then accept x(i) i=i+1 else reject x(i) end end

- rejection sampling efficiency is too low because if the red distribution is not chosen well, and it cannot tightly enclose the green distribution, the acceptance rate is too low, and most samples will be rejected.
Adaptive Rejection Sampling
- When the distribution is log-concave, we can effectively construct the envelope of the green distribution, which means the red distribution is closer to the green distribution and has a higher acceptance rate
- The basic idea is to divide the green distribution to be sampled into k regions, with the leftmost point in each region serving as the starting point. If the green distribution at the starting point in each region can be enveloped by its tangent line, we can then use the tangent lines on these k regions to form the red region
- However, this requires that the original distribution be concave in each region, but for example, the probability density function of the Gaussian distribution is not a concave function; however, the Gaussian distribution becomes concave after taking the logarithm, which is what is called log-concave. Therefore, we first take the logarithm, draw the tangent, and then calculate the exponential to return to the original distribution, obtaining the k-segment tangents of the original distribution.
![i0oEFI.jpg]()

Importance Sampling
The sampling algorithm mentioned above samples from a simple distribution (proposed distribution), calculates the acceptance rate for each sample through the relationship between the simple distribution and the complex distribution, and rejects some samples to ensure that the remaining samples satisfy the complex distribution
The idea of importance sampling is to weight the sample points rather than simply rejecting or accepting them, thus fully utilizing each sample point.
For example, we hope to obtain the expected value of a distribution through sampling
p(x) is difficult to sample, so we convert it to sampling from q(x). Here, $\frac{p(x)}{q(x)}$ represents the importance weight.
We thus eliminate the restriction that the red distribution must envelop the green distribution, as long as we calculate the importance weights and perform importance weighting on the sampled points, we can obtain some statistical quantities under the green distribution.
Markov Monte Carlo and Metropolis-Hastings algorithms
MCMC is another sampling method, where the sample sequence is regarded as a Markov chain, and the samples sampled by MCMC are not independent; the probability distribution of the next sample is related to the previous sample
Different from the concepts of general sampling acceptance or rejection, MCMC calculates the probability distribution of the next sample’s position under the premise of the current sample after each sample, which is the key transition probability.
After sampling a sample, we draw the next one according to the transition probability, obtaining a series of samples that conform to the given distribution. It is evident that the transition probability needs to be related to the given distribution. We utilize the convergence of the Markov chain, hoping that the distribution after convergence, denoted as $\pi$ , is the given distribution, assuming the transition probability is denoted as $k(x^{‘} | x)$ , from sample $x$ to sample $x^{‘}$ .
In the Markov chain, there is the following Chapman-Kolmogorov equation:
The significance of this formula is self-evident. We hope to achieve the convergence of Markov chains. After convergence, regardless of how the transition is made, the sequence of samples obtained should satisfy the same given distribution, then the requirement is:
Actual use relies on another important formula, known as the detailed balance condition:
From detailed balance, it can be deduced that the Chapman-Kologronvo equation holds, but the converse is not necessarily true.
When the detailed balance condition is satisfied, the Markov chain is convergent
In the LDA blog, mh and Gibbs are introduced, and Metropolis-Hasting is the result of the basic MCMC where the acceptance rate on one side is raised to 1:
![i0okTA.jpg]()
In the mh, we did not alter the transition matrix to adapt to the given distribution, but instead used the given distribution to correct the transition matrix, thus, the transition matrix is one that we ourselves designed. Generally, the transition matrix (proposal distribution) is designed as a Gaussian distribution centered around the current state. For this Gaussian distribution, when the variance is small, the probability is concentrated around the current sampling point, so the position transferred to the next sampling point is unlikely to change much, resulting in a high acceptance rate (since the current sampling point is the one that passed the acceptance, it is likely to be in a position with a high acceptance rate). However, this will cause the random walk to be slow; if the variance is large, it will wander everywhere, and the acceptance rate will decrease.
Despite one side’s sample acceptance rate reaching 1, there is always one side below 1. If it is rejected, the MCMC will repeat sampling at the same location once and then continue.
And Gibbs raised both acceptance rates to 1, which shows that Gibbs is a special case of MCMC. MCMC does not modify the transition probability but adds the acceptance rate, linking the original transition probability with the distribution to be sampled. However, it is obvious that if we ourselves choose the transition probability and make it more closely related to the original distribution, the effect will be better, and Gibbs follows this approach.

Hybrid Metropolis-Hasting
- To be supplemented
Gibbs Sampling
A motivation for Gibbs sampling: It is difficult to sample directly from the joint distribution of multiple parameters, but if other parameters are fixed as conditions, sampling from the conditional distribution of just one parameter becomes much simpler, and it can be proven that the samples obtained after convergence satisfy the joint distribution
Firstly, let’s consider why the Gibbs sampling process does not change the joint probability distribution through iterative conditional sampling. Firstly, when excluding the i-th parameter to calculate the conditional probability, the marginal distribution of the excluded n-1 variables is the same as the marginal distribution of the true joint probability distribution for these n-1 variables, because their values have not changed; the condition on which the conditional probability is based is unchanged compared to the true distribution, so the conditional probability distribution is also unchanged. Both the marginal distribution and the conditional probability distribution are unchanged (true), so the joint distribution obtained by multiplying them is naturally unchanged, and therefore, in each iteration step, sampling is done according to the true distribution and the iteration does not change this distribution.
Gibbs sampling is a coordinate descent method similar to variational inference, updating one component of the sample at a time, based on the conditional probability of the current updating component’s dimension given the other components:
![i0oVYt.jpg]()
Industrial applications of Gibbs sampling are widespread due to its speed. In fact, such an iterative algorithm cannot be parallelized, but the collapsed Gibbs sampling can parallelize the iteration. The principle is to treat several components as a whole, collapsing them into one component. When other components are updated using this set of components, they are considered independent (there is some doubt; another way to describe collapse is to ignore some conditional variables. Basic Gibbs sampling is essentially collapsed Gibbs sampling, and the approach of treating several components as a whole is blocked Gibbs sampling):
u~p(u|x,y,z) x,y,z~p(x,y,z|u) =p(x|u)p(y|u)p(z|u)

The three conditional probabilities concerning x, y, and z can be computed in parallel.
Now we prove that Gibbs is a special case of Metropolis-Hastings with an acceptance rate of 1, let’s first look at the acceptance rate of Metropolis-Hastings
In Gibbs
And in fact, from $x{¬i}$ to $x{¬i}^{‘}$ , only the ith component changes, with the other components remaining unchanged, therefore
Next, let’s examine Gibbs’ acceptance rate
Expectation Maximization
Update
- deep|bayes2018 mentions using stochastic gradient descent for the M-step in EM, as it is stochastic, the E-step only targets a portion of the data, reducing overhead, and enabling inference of latent variable models on large-scale datasets. At the time, it was applied to word2vec, adding a qualitative latent variable for each word to indicate one of its multiple meanings, aiming to resolve ambiguity issues, and even parameterize the number of word meanings using the Chinese restaurant process. Will look at it in detail when I have time.
Formula
- For simple distributions, we want to perform parameter inference, which only requires maximum likelihood estimation, first calculating the log-likelihood:
Afterward, differentiate the log-likelihood to calculate the extrema; however, for complex distributions, it may not be convenient to differentiate
We can use the EM algorithm to iteratively solve this. The EM algorithm considers the latent variables in the probabilistic generative model and assigns probabilities to them, updating their probability distribution and the parameter $\theta$ simultaneously with each iteration. It can be proven that after each iteration, the obtained $\theta$ will increase the log-likelihood.
Each iteration is divided into two parts, E and M, which correspond to seeking the expectation and maximization
- The expectation is the expectation of $\log p(x,z|\theta)$ over the distribution $p(z|x,\theta ^{(t)})$ , where $\theta ^{(t)}$ is the parameter calculated at the t-th iteration
- Maximization, that is, seeking the $\theta$ that maximizes this expectation, as the result of the parameter update in this iteration
The formula for the EM algorithm is obtained when combined:
Why Effective
That is to prove, the maximum likelihood will increase after each iteration
To prove:
Reformulate the log-likelihood
Both sides of the distribution $p(z|x,\theta ^{(t)})$ calculate the expectation, noting that the left side of the equation is independent of z, therefore, after calculating the expectation, it remains unchanged:
The Q part is the E part of the EM algorithm, note that here $\theta$ is a variable, $\theta ^{(t)}$ is a constant
After the iteration, due to the role of the M part in the EM algorithm, the Q part must have increased (greater than or equal to), then what will the new $\theta$ after this iteration that makes the Q part increase change when substituted into the H part?
We first calculate, assuming that the $\theta$ of section H remains unchanged, directly using the previous $\theta ^{(t)}$ to input, that is, $H(\theta ^{(t)},\theta ^{(t)})$
The inequality in question utilizes the Jensen inequality. That is, directly using the previous $\theta ^{(t)}$ as $\theta$ to substitute into H is the maximum value of H! Then, regardless of how much $\theta ^{(t+1)}$ is obtained from the new argmax Q part, substituting it into H will cause the H part to decrease (less than or equal to) ! The numerator becomes larger, and the denominator smaller, so the result is that the log-likelihood is definitely larger, which proves the effectiveness of the EM algorithm.
Understanding from the perspective of the Evidence Lower Bound (ELBO)
We can also derive the formula for the EM algorithm from the perspective of ELBO (Evidence Lower Bound)
In the previous rewriting of the log-likelihood, we obtained two expressions $p(x,z|\theta)$ and $p(z|x,\theta)$ . We introduce a distribution $q(z)$ of latent variables, and by computing the KL divergence between these two expressions and $q(z)$ , we can prove that the log-likelihood is the difference between these two KL divergences:
That is to say
ELBO is the evidence lower bound, because of $KL(q(z)||p(z|x,\theta)) \geq 0$ , thus ELBO is a lower bound for the log-likelihood. We can maximize this lower bound to maximize the log-likelihood.
It can be seen that the ELBO has two parameters, $q$ and $\theta$ . First, we fix $\theta ^{(t-1)}$ , and find the $q^{(t)}$ that maximizes the ELBO, which is actually the E-step of the EM algorithm. Next, we fix $q^{(t)}$ , and find the $\theta ^{(t)}$ that maximizes the ELBO, which corresponds to the M-step of the EM algorithm
We substitute $\theta = \theta ^{(t-1)}$ into the ELBO expression:
What value of q maximizes the ELBO? It is obvious that when the KL divergence is 0, the ELBO reaches its maximum value, which is when the lower bound reaches the logarithmic likelihood itself, at which point $q(z)=p(z|x,\theta ^{(t-1)})$ , next we fix $q$ , and seek the value of $\theta$ that maximizes the ELBO, first rewriting the definition of ELBO:
The second item is unrelated to $\theta$ , therefore:
Substitute the $q(z)=p(z|x,\theta ^{(t-1)})$ obtained in the previous step, and we get
Similarly, the iterative formula of the EM algorithm is obtained
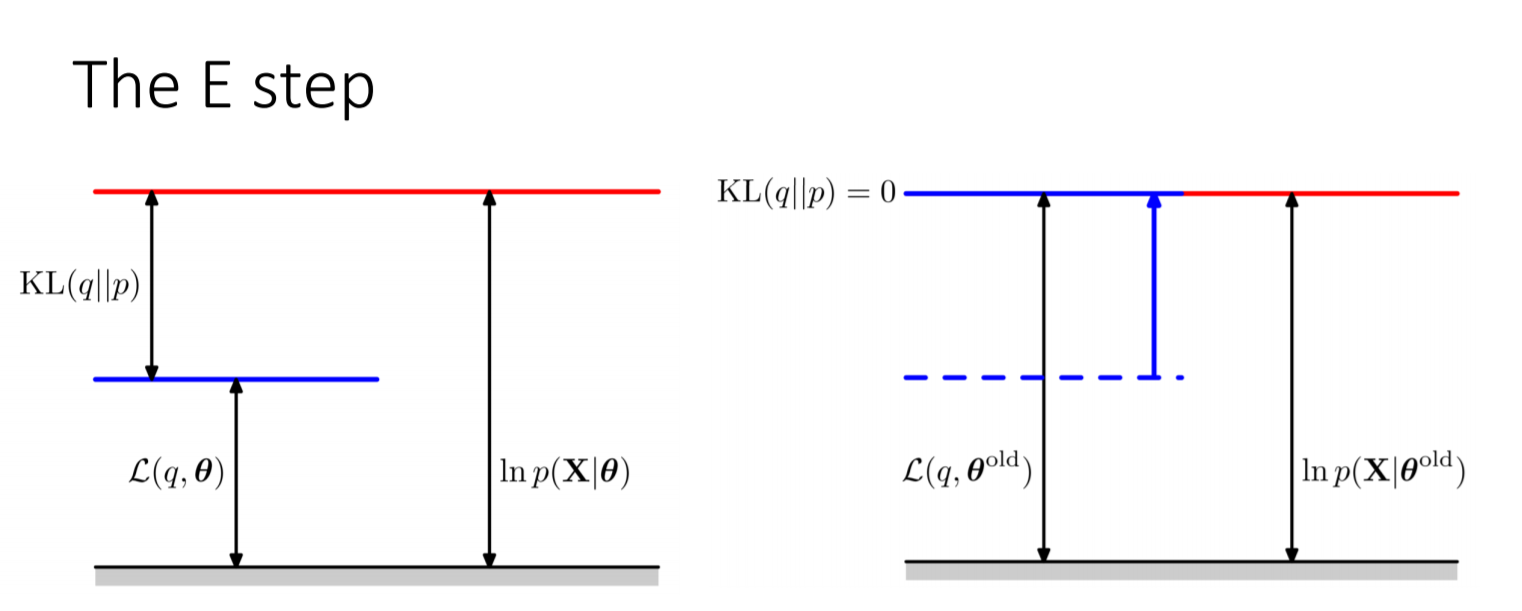
The following two figures are extracted from Christopher M. Bishop’s Pattern Recognition and Machine Learning, illustrating what the E-step and M-step actually do: The E-step raises the lower bound ELBO to the log-likelihood, but at this point only the latent variables are updated, so the log-likelihood does not change. When the updated latent variables are used to update the parameters $\theta$ , i.e., after the M-step is executed, we continue to obtain a higher ELBO and its corresponding log-likelihood. At this time, q does not change, but p changes, so KL is not 0, and the log-likelihood must be greater than the ELBO, i.e., it will increase. Intuitively, we increase the ELBO in both the E and M steps; the E-step first raises the ELBO to the log-likelihood in one go, and then the M-step can still increase the ELBO, but the log-likelihood will definitely be greater than or equal to (in fact, greater than) the ELBO at the M-step, so the log-likelihood is “pushed up” by the ELBO increased by the M-step.
![i0oZfP.png]()
![i0ou6S.png]()
The remaining issue is how to select z and q; in the mixed model, z can be introduced as an indicator function, while the other probability models containing latent variables can directly introduce the latent variables during design

From the perspective of assuming latent variables to be observable
- This understanding comes from the tutorial by Chuong B Do & Serafim Batzoglou: What is the Expectation Maximization Algorithm?
- EM is used for inference in probabilistic models with unobserved latent variables. In fact, if we make the latent variables observable from unobserved, and perform maximum likelihood estimation for each possible value of the latent variables, we can still obtain results, but the time cost is quite high.
- EM then improves this naive algorithm. One understanding of the EM algorithm is: The EM algorithm first guesses a probability distribution of the hidden variables in each iteration, creates a weighted training set considering all possible values of the hidden variables, and then performs a modified version of maximum likelihood estimation on it.
- Guessing the probability distribution of a hidden variable is the E-step, but we do not need to know the specific probability distribution; we only need to calculate the expectation of the sufficient statistic on this distribution.
- The EM algorithm is a natural generalization of maximum likelihood estimation to data containing hidden variables (or data containing partially unobserved samples).
From the perspective of missing values in the latent variables
- How are missing values generally handled? Replaced with random values, mean values, 0 values, cluster center values, etc
- EM is equivalent to replacing missing values with the mean, i.e., the latent variable, but it utilizes more information: this mean is obtained by taking the expectation over the known distribution of x
- The EM iteration involves repeatedly processing missing values (latent variables), then adjusting the distribution of x based on the complete data, and finally treating the latent variables as missing values for adjustment
EM algorithm and K-means
- K-means is a Hard-EM algorithm that, like the EM algorithm, makes assumptions about various possible latent variables (the class to which the sample belongs), but it does not calculate probabilities and expectations on the class level. Instead, it is more rigid, specifying only one class as the sample’s class, with a probability of 1 for this class and 0 for all others.
Benefits of Introducing Latent Variables
In fact, it should be said the other way around: many times, we design latent variables based on logic and then use the EM algorithm to infer the latent variables, rather than deliberately designing latent variables to simplify computation.
For GMM, one advantage of introducing latent variables is that it simplifies the computation of maximum likelihood estimation (of course, this is under the assumption that we know the latent variables), by exchanging the logarithm with the summation operation, referring to the blog of the great pluskid: On Clustering (Extra Chapter): Expectation Maximization
Before introducing latent variables as indicator functions for GMM, the maximum likelihood estimation is:
After introducing latent variables, the indicator function corresponding to the ith sample $x_i$ is $z_i$ , which is a k-dimensional one-hot vector representing which of the k Gaussian models the ith sample belongs to. If it belongs to the mth model, then $z_i^m$ equals 1, and the rest are 0. Now, the maximum likelihood estimation is:
Application of Monte Carlo Method in the EM Algorithm
When the E-step cannot parse the computation, the integral of the M-step can be approximated using Monte Carlo methods:
We sample a finite number of $Z^l$ based on the posterior estimate $p(z|x,\theta ^{(t)})$ of the latent variables obtained now, and then substitute these $Z^l$ into $\log p(x,z|\theta)$ to approximate the integral:
An extreme example of the Monte Carlo EM algorithm is the random EM algorithm, which is equivalent to sampling only one sample point in the E-step at each iteration. In the solution of mixed models, the latent variables act as indicator functions, and sampling only one latent variable implies hard assignment, with each sample point assigned to a component with a probability of 1.
Monte Carlo EM algorithm extended to the Bayesian framework results in the IP algorithm
I steps:
Sample from $p(\theta | X)$ , then substitute into it, and subsequently sample from $p(Z | \theta ^l ,X)$ into $Z^l$ .
P-step: Sampling from the I-step obtained $Z^l$ for estimating the posterior parameters:
Generalized EM Algorithm
- Will not chicken out
Wake-Sleep algorithm
- Pigeon Ethics Philosophy
Generalized EM Algorithm and Gibbs Sampling
- When you think I won’t chicken out and I do, it’s also a form of not chickening out
Variational Inference
ELBO
Next, we introduce variational inference, and it can be seen that the EM algorithm can be generalized to variational inference
Reintroducing the relationship between ELBO and log-likelihood:
Seek the expectation of the hidden distribution $q(z)$ on both sides
We hope to infer the posterior distribution of the latent variable $z$ , for this purpose, we introduce a distribution $q(z)$ to approximate this posterior. Under the premise of the current observations, i.e., the log-likelihood, the approximation of the posterior is equivalent to minimizing the KL divergence between $q(z)$ and $p(z|x)$ . From the above formula, it can be seen that when the ELBO is maximized, the KL divergence is minimized.
Next is the discussion on how to maximize the ELBO
Variational inference on arbitrary distributions
For any distribution, update one component of the latent variable at a time, such as the jth component
Ourself-selected $q(z)$ is of course simpler than the approximate distribution; here, it is assumed that the distribution is independent, and the latent variable is $M$ -dimensional:
Therefore, the ELBO can be expressed in two parts
The part1 can be expressed in the form of multiple integrals over the various dimensions of the latent variables, and we select the jth dimension to rewrite it as
In this context, we define a form of pseudo-distribution, which is the pseudo-distribution of a distribution, obtained by integrating the logarithm of the distribution and then exponentiating the result:
This part 1 can be rewritten in the form of pseudo-distribution
In part 2, because the components of the latent variables are independent, the sum of the function can be rewritten as the sum of the expectations of each function over the marginal distributions, in which we focus on the j-th variable, treating the rest as constants:
Combine part 1 and part 2 to obtain the form of the ELBO for component j:
The ELBO is written as the negative KL divergence between a pseudo-distribution and an approximate distribution, maximizing the ELBO is equivalent to minimizing this KL divergence
When is this KL divergence minimum? That is to say:
We have obtained the iterative formula for the approximate distribution of a single component of the latent variables under variational inference. When calculating the probability of the jth component, the expectation over all other components $q_i(z_i)$ is used, and then this new probability of the jth component participates in the next iteration, calculating the probabilities of the other components.
Exponential family distribution
Define the exponential family distribution:
Amongst
- sufficient statistics
- $\theta$:parameter of the family
- $\eta$:natural parameter
- underlying measure
- $A(\theta)$ : log normalizer / partition function
Attention: The parameter of the family and the natural parameter are both vectors. When the exponential family distribution is in the form of scalar parameters, i.e., $\eta _i (\theta) = \theta _i$ , the exponential family distribution can be written as:
When we express the probability density function in the exponential family form, we have:
Continuing to seek extrema, we can obtain a very important property of the exponential family distribution regarding the log normalizer and sufficient statistics:
For example, the Gaussian distribution is written in the form of an exponential family distribution:
Using natural parameters to replace variance and mean, expressed in the exponential family distribution form:
Wherein:
- $T(x)$:$[x \ x^2]$
- $\eta$:$[ \eta _1 \ \eta _2] ^T$
- $-A(\eta)$:$\frac{\eta _1 ^2}{4 \eta _2} + \frac 12 \log (-2 \eta _2 )$
Next, we utilize the properties of the exponential family to quickly calculate the mean and variance
Why is $A(\eta)$ called log normalizer? Because the integral of the exponential family distribution of the probability density has:
Below discusses the conjugate relationships of exponential family distributions, assuming that both the likelihood and the prior are exponential family distributions:
Rewritten in the form of a vector group:
In the original expression, $\beta$ , $h(x)$ , and $A(\alpha)$ are all constants, which are eliminated from the proportional expression and then substituted into the vector group:
We note that if we let $-g(\beta)=-A_l (\beta)$ , the original expression can be written as:
The prior and posterior forms are consistent, that is, conjugate
We thus write down the likelihood and prior in a unified form
Here we can calculate the derivative of the log normalizer with respect to the parameters, note that this is a calculated result, different from the properties of the log normalizer and sufficient statistics obtained from the maximum likelihood estimation of the exponential family distribution
The above equation can be proven by integrating over the exponential family distribution with the integral equal to 1, and taking the derivative with respect to $\beta$ yields 0, transforming this equation to prove it.
Variational Inference under Exponential Family Distributions
Next, we will express the parameter posterior in the ELBO in the form of an exponential family distribution, and it can be seen that the final iteration formula is quite concise
We assume that there are two parameters to be optimized, x and z, and we use $\lambda$ and $\phi$ to approximate $\eta(z,x)$ and $\eta(\beta ,x)$ . The goal remains to maximize the ELBO, at which point the adjusted parameter is $q(\lambda , \phi)$ , which is actually $\lambda$ and $\phi$
We adopt a method of fixing one parameter and optimizing another, iteratively making the ELBO larger
First, we rewrite the ELBO, noting $q(z,\beta)=q(z)q(\beta)$
The posterior is distributed in the exponential family, and the q-distribution is approximated using simple parameters $\lambda$ and $\phi$
Now we fix $\phi$ , optimize $\lambda$ , and remove irrelevant constants from the ELBO, yielding:
Substitute the exponential family distribution, eliminate the irrelevant constant $- E_{q(z)}[A_g(\eta(x,z))]$ , and simplify to obtain:
Using the conclusions from the previous log normalizer regarding parameter differentiation, we have:
Differentiate the above equation, set it to 0, and we have:
We have obtained the iterative $\lambda$ ! Similarly, we can obtain:
Should be written as:
The variable update paths for these two iterative processes are: