Note for Latent Dirichlet Allocation

Latent Dirichlet Allocation Document Topic Generation Model Study Notes This article mainly summarizes from "Mathematical Curiosities of LDA(LDA数学八卦)," which is written very beautifully (recommend reading the original first). There are many places that spark further thought, and this article sorts out the steps to derive LDA, removes some irrelevant extensions, and summarizes LDA in plain language.
What is LDA used for
- LDA is a topic model; the question is actually what is a topic model used for? It is used to represent documents. Here, documents are viewed as a bag of words.
- If each word in the dictionary is considered a feature and the tfidf value is used as the magnitude of the feature to represent a document, then the feature vector of the document is too sparse and has too high a dimensionality
- The solution of LSI is to perform singular value decomposition on the document-word matrix, reduce dimensions, but the reduced dimension space obtained, i.e., the latent variables between words and documents, is unexplainable; a purely mathematical method, too forceful
- PLSA proposes that latent variables should be topics, which can represent documents as topic vectors, and define topics as a certain polynomial distribution on the dictionary. This way, PLSA contains two layers of polynomial distributions: the polynomial distribution from documents to topics (the mixing proportion of various topics in a document, i.e., the feature vector of the document), and the polynomial distribution from topics to words (the probability distribution over the entire dictionary, representing the probability of each word appearing under different topics)
- LDA specifies Dirichlet priors for the parameters of these two polynomial distributions, introducing a Bayesian framework for PLSA
Bayesian model
LDA is a Bayesian model
Given the training data, how does a Bayesian model learn parameters (the distribution of parameters): Bayesian estimation
Prior distribution for the parameter \(p(\theta)\)
Given the data, calculate the likelihood \(p(X|\theta)\) and evidence \(P(X)\) , and then compute the posterior distribution of the parameters according to Bayes' formula
Posterior distribution is the distribution of the learned parameters
\[ p(\vartheta | X)=\frac{p(X | \vartheta) \cdot p(\vartheta)}{p(\mathcal{X})} \]
The data may be too much, so update in batches; the posterior obtained after the last update serves as the prior for the next update, similar to the idea in stochastic gradient descent
For the likelihood of new data, unlike maximum likelihood estimation or maximum a posteriori estimation, both of which are point estimates, directly calculating \(p(x_{new}|\theta _{ML})\) , \(p(x_{new}|\theta _{MAP})\) , Bayesian estimation requires integrating over the parameter distribution:
\[ \begin{aligned} p(\tilde{x} | X) &=\int_{\vartheta \in \Theta} p(\tilde{x} | \vartheta) p(\vartheta | X) \mathrm{d} \vartheta \\ &=\int_{\vartheta \in \Theta} p(\tilde{x} | \vartheta) \frac{p(X | \vartheta) p(\vartheta)}{p(X)} \mathrm{d} \vartheta \end{aligned} \]
Two issues often arise in Bayesian estimation
- With prior knowledge and likelihood, the calculated posterior is complex
- evidence is hard to calculate
Therefore, conjugate and Gibbs sampling respectively solve these two problems
- Conjugate: Given the likelihood, find a prior such that the posterior has the same form as the prior
- gibbs sampling: Using the idea of MCMC to approximate the posterior without explicit computation of the evidence
If it is a Bayesian model with latent variables, then there is
\[ p(\vartheta|x) = \int_{z} p(\vartheta|z)p(z|x) \]
In LDA, the latent variable z represents the topic to which a word belongs (the word's topic assignment), so \(p(\vartheta|z)\) is naturally easy to calculate, and then the remaining \(p(z|x)\) can be calculated using the formula for Bayesian inference:
\[ p(z | X)=\frac{p(X | z) \cdot p(z)}{p(\mathcal{X})} \]
Before introducing LDA, two other models are introduced: the Bayesian unigram and PLSA. The former can be considered as LDA without a topic layer, and the latter as LDA without Bayesian regularization
Next, we will separately introduce conjugate, Gibbs sampling, Bayesian unigram/PLSA, and finally, LDA
Conjugation
Gamma function
Definition
\[ \Gamma (x) = \int _0 ^{\infty} t^{x-1} e^{-t} dt \]
Due to its recursive nature \(\Gamma(x+1)=x\Gamma(x)\) , the definition of factorial can be extended to the real number domain, thereby extending the definition of the derivative of a function to the real set, for example, calculating the second derivative at 1/2
Bohr-Mullerup theorem: If \(f:(0,\infty) \rightarrow (0,\infty)\) and satisfy
- \(f(1)=1\)
- \(f(x+1)=xf(x)\)
- If \(log f(x)\) is a convex function, then \(f(x)=\Gamma(x)\)
Digamma function
\[ \psi (x)=\frac{d log \Gamma(x)}{dx} \]
It has the following properties
\[ \psi (x+1)=\psi (x)+\frac 1x \]
The result of inferring LDA using variational inference is in the form of the digamma function
Gamma distribution
Transform the above equation
\[ \int _0 ^{\infty} \frac{x^{\alpha -1}e^{-x}}{\Gamma(\alpha)}dx = 1 \]
Therefore, it is advisable to take the function in the integral as the probability density, obtaining the density function of the simplest form of the Gamma distribution:
\[ Gamma_{\alpha}(x)=\frac{x^{\alpha -1}e^{-x}}{\Gamma(\alpha)} \]
Exponential distribution and \(\chi ^2\) distribution are both special cases of the Gamma distribution, and they are very useful as prior distributions, widely applied in Bayesian analysis.
Gamma distribution and Poisson distribution have a formal consistency, and in their usual representations, there is only a difference of 1 in the parameters. As previously mentioned, factorials can be represented by the Gamma function, therefore, it can be intuitively considered that the Gamma distribution is a continuous version of the Poisson distribution over the set of positive real numbers.
\[ Poisson(X=k|\lambda)=\frac{\lambda ^k e^{-\lambda}}{k!} \]
The limit distribution of the binomial distribution with \(np=\lambda\) is the Poisson distribution as n approaches infinity and p approaches 0. A common example used to explain the Poisson distribution is the reception of calls by a switch. Assuming the entire time is divided into several time intervals, with at most one call per interval, the probability being p, the total number of calls follows a binomial distribution. When np is a constant \(\lambda\) , dividing time into an infinite number of segments, which are almost continuous, substituting \(p=\frac{\lambda}{n}\) into the binomial distribution, taking the limit yields the Poisson distribution. On this basis, by making the distribution values continuous (i.e., replacing the factorial of k in the Poisson distribution with the Gamma function) we obtain the Gamma distribution.
Beta distribution
- Background:
How to obtain the distribution of the kth order statistic \(p=x_k\) when n random variables uniformly distributed in the interval [0,1] are sorted in ascending order?
To obtain the distribution, by employing the idea of limits, we calculate the probability that this variable falls within a small interval \(x \leq X_{k} \leq x+\Delta x\)
Divide the entire interval into three parts: before the small interval, the small interval, and after the small interval. If only the k-th largest number is present in the small interval, then there should be k-1 numbers before the small interval, and n-k numbers after the small interval. The probability of this situation is
\[ \begin{aligned} P(E)&=x^{k-1}(1-x-\Delta x)^{n-k}\Delta x \\ &=x^{k-1}(1-x)^{n-k}\Delta x+\omicron (\Delta x) \\ \end{aligned} \]
If there are two or more numbers within a small interval, the probability of this situation is \(\omicron (\Delta x)\) , therefore, only consider the case where there is only the k-th largest number within the small interval. In this case, let \(\Delta x\) tend towards 0, then we obtain the probability density function of the k-th largest number (note that the coefficient of event E should be \(nC_n^k\) ):
\[ f(x)=\frac{n!}{(k-1)!(n-k)!}x^{k-1}(1-x)^{n-k} \quad x \in [0,1] \]
Expressed in terms of the Gamma function (let \(\alpha =k,\beta = n-k+1\) ), we obtain:
\[ \begin{aligned} f(x)&=\frac{\Gamma(\alpha+\beta)}{\Gamma(\alpha)\Gamma(\beta)}x^{\alpha-1}(1-x)^{\beta-1} \\ &=Beta(p|k,n-k+1) \\ &=Beta(\alpha,\beta) \\ \end{aligned} \]
This is the Beta distribution; we can take the point of the maximum probability distribution as the predicted value for the kth largest number.
- Beta distribution is actually a prediction of a distribution, that is, the distribution of distributions. In the background, we are looking for the probability distribution of the kth largest order statistic, and we denote this kth largest order statistic as p. Now, we know there are n values uniformly distributed in the interval [0,1], and n and k establish a relative position within the interval [0,1], which is the role of \(\alpha\) and \(\beta\) (because \(\alpha\) and \(\beta\) are calculated from n and k), representing where I tend to believe p is within [0,1]. Since the n statistics are uniformly distributed and p is the kth largest among them, p tends to be at the position \(\frac kn\) .
- Therefore, the parameters of the Beta distribution ( \(\alpha\) and \(\beta\) ) are clearly meaningful, representing my prior belief about the possible location of p, even when I know nothing, that is, the prior. The result of the Beta distribution is the distribution of p calculated under this prior influence, and the actual meaning of this p is the parameter of the binomial distribution. Therefore, the Beta distribution can serve as a prior for the parameters of the binomial distribution.
Beta-Binomial conjugate
- We can establish a Beta distribution prior for the kth largest number. If we now know there are m numbers uniformly distributed between [0,1], and some of them are larger than the kth largest number while others are smaller, we can incorporate this as additional data knowledge to form the posterior distribution.
- Assuming the number to be guessed is \(p=X_k\) , now we know that there are \(m_1\) numbers smaller than \(p\) , and \(m_2\) numbers larger than \(p\) , it is obvious that the probability density function of \(p\) becomes \(Beta(p|k+m_1,n-k+1+m_2)\)
- The knowledge of m numbers added into the data is equivalent to conducting m Bernoulli experiments, because the range we are discussing is on [0,1], and the m numbers only care whether they are larger or smaller than \(p\) , the value of \(p=X_k\) can represent this probability, therefore \(m_1\) follows a binomial distribution \(B(m,p)\)
|
A priori |
Data Knowledge |
Posterior |
|---|---|---|
|
Beta distribution |
Binomial distribution |
Beta distribution |
Therefore, we can obtain the Beta-Binomial conjugate
\[ Beta(p|\alpha,\beta)+BinomCount(m_1,m_2)=Beta(p|\alpha+m_1,\beta+m_2) \]
When the data conforms to a binomial distribution, both the prior distribution and the posterior distribution of the parameters can maintain the form of a Beta distribution. We can assign a clear physical meaning to the parameters in the prior distribution and extend this interpretation to the posterior distribution, therefore, the parameters \(\alpha,\beta\) in the Beta distribution are generally referred to as pseudo-counts, representing physical counts.
It can be verified that when both parameters of the Beta distribution are 1, it becomes a uniform distribution. At this point, the conjugate relationship can be considered as follows: Initially, the unevenness of the coin is unknown, and it is assumed that the probability of the coin landing on heads is uniformly distributed. After tossing the coin m times, data is obtained with \(m_1\) tosses landing on heads and the rest landing on tails. By calculating the posterior probability using Bayes' formula, the probability of the coin landing on heads can be determined to be exactly \(Beta(p|m_1+1,m_2+1)\)
Through this conjugation, we can derive an important formula concerning the binomial distribution:
\[ P(C \leq k) = \frac{n!}{k!(n-k-1)!}\int _p ^1 t^k(1-t)^{n-k-1}dt \quad C \sim B(n,p) \]
The following can now be proven:
The left side of the formula is the probability cumulative of the binomial distribution, and the right side is the probability integral of the \(Beta(t|k+1,n-k)\) distribution
Select n random variables uniformly distributed in [0,1], for the binomial distribution \(B(n,p)\) , if the number is less than \(p\) , it is considered successful; otherwise, it is a failure. The number of random variables less than \(p\) is C and follows the binomial distribution \(B(n,p)\)
At this point, we obtain \(P(C \leq k)=P(X_{k+1}>p)\) , which means that there are \(k\) variables less than \(p\) after n random variables are arranged in order
At this point, utilizing our probability density of the k-th largest number, we calculate it to be a Beta distribution, and then substitute it into the equation
\[ \begin{aligned} P(C \leq k) &=P(X_{k+1} > p) \\ &=\int _p ^1 Beta(t|k+1,n-k)dt \\ &=\frac{n!}{k!(n-k-1)!}\int _p ^1 t^k(1-t)^{n-k-1}dt \\ \end{aligned} \]
Proof by construction
By taking the limit of n to infinity in this formula and converting it to a Poisson distribution, the Gamma distribution can be derived.
In this section, we introduced other information to the prior, that is, there are several numbers larger and smaller than the k-th largest number. This information is equivalent to telling me: I can modify the prior of p; the position I previously tended to believe in has shifted. If I know several numbers are larger than p, then the prior position of p should be shifted to the right. If I know several numbers are smaller than p, then the prior position of p should be shifted to the left. What if I simultaneously know 100 numbers are larger than p and 100 numbers are smaller than p? The position of p remains unchanged, but I am more confident that the true position of p is now this prior position. Therefore, the Beta distribution is more concentrated at this prior position. This point will be seen again in the subsequent analysis of the meaning of the Dirichlet parameters. After adding prior knowledge and data, we form the posterior, which is the basic content of Bayes' formula.
Dirichlet-Multinomial Conjugacy
How should we calculate the joint distribution of guessing two numbers \(x_{k_1},x_{k_1+k_2}\) ?
Similarly, we set two extremely small intervals \(\Delta x\) , dividing the entire interval into five parts, with the extremely small intervals being \(x_1,x_2,x_3\) , after which the calculation can be obtained
\[ f(x_1,x_2,x_3)=\frac{\Gamma(n+1)}{\Gamma(k_1)\Gamma(k_2)\Gamma(n-k_1-k_2+1)}x_1^{k_1-1}x_2^{k_2-1}x_3^{n-k_1-k_2} \]
Organize it and it can be written as
\[ f(x_1,x_2,x_3)=\frac{\Gamma(\alpha _1+\alpha _2+\alpha _3)}{\Gamma(\alpha _1)\Gamma(\alpha _2)\Gamma(\alpha _3)}x_1^{\alpha _1-1}x_2^{\alpha _2-1}x_3^{\alpha _3-1} \]
This is the 3D form of the Dirichlet distribution. The \(x_1,x_2,x_3\) (which actually only has two variables) determines the joint distribution of two order statistics, and \(f\) represents the probability density.
Observing that under the condition of \(\alpha\) being determined, the preceding series of gamma functions are actually the denominator of the probability normalization, in the following text we will express the Dirichlet distribution in a more general form:
\[ Dir(\mathop{p}^{\rightarrow}|\mathop{\alpha}^{\rightarrow})=\frac{1}{\int \prod_{k=1}^V p_k^{\alpha _k -1}d\mathop{p}^{\rightarrow}} \prod_{k=1}^V p_k^{\alpha _k -1} \]
The normalization denominator, that is, the entire set of gammas, is made to be:
\[ \Delta(\mathop{\alpha}^{\rightarrow})=\int \prod _{k=1}^V p_k^{\alpha _k -1}d\mathop{p}^{\rightarrow} \]
参数
\[ Dir(p|\alpha)+MultCount(m)=Dir(p|\alpha+m) \]
The parameters in the above formula are all vectors, corresponding to the multi-dimensional case.
Whether it is the Beta distribution or the Dirichlet distribution, they both possess an important property, that is, their mean can be represented by the ratio of the parameters, for example, for the Beta distribution, \(E(p)=\frac{\alpha}{\alpha+\beta}\) , and for the Dirichlet distribution, the mean is a vector corresponding to the vector composed of the ratios of the parameters.
Dirichlet analysis
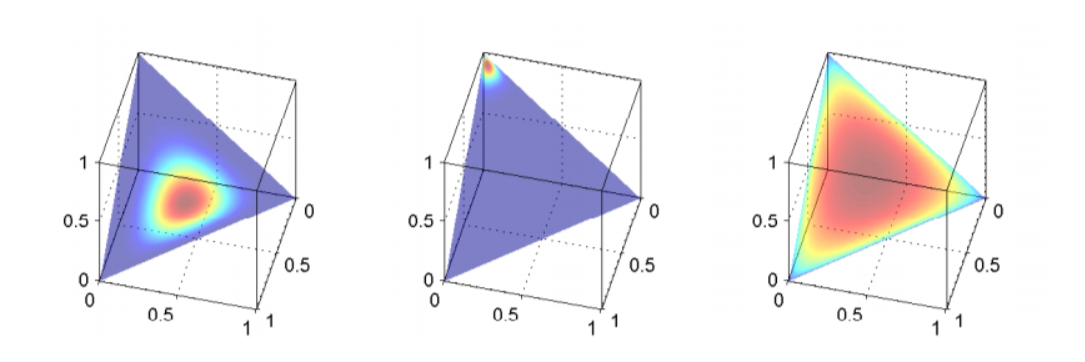
- According to the properties of Dirichlet, the ratio of its parameters represents a partition on [0,1], determining the locations of high probability in the Dirichlet distribution, and the magnitude of the parameters determines the proportion of high probability (steepness), as shown in the following figure, the polynomial distribution has three terms with parameters \(p_1,p_2,p_3\) , their sum is 1 and each is greater than zero, and in three-dimensional space it forms a triangular face, with each point on the surface representing a polynomial distribution; the red area has a high probability, and the blue area has a low probability:
- Controlled the mean shape and sparsity of polynomial distribution parameters.
- On the far left, the three parameters \(\alpha _1,\alpha _2,\alpha _3\) of Dirichlet are equal, indicating that the red region is centered, and the values of the three \(\alpha\) are all relatively large, with a smaller red region. If the heatmap is viewed as a contour plot, this would represent a steeper red region, suggesting that Dirichlet is very confident that the parameters of the polynomial distribution will be centered. For the parameters \(p_1,p_2,p_3\) of the three polynomial distributions, a larger possibility is that all three p values are equal.
- The middle figure, with three \(\alpha\) not equal, one \(\alpha\) being larger, causing the red area to lean towards one corner of the triangular face, leading to a larger p value for one and a higher probability of smaller p values for the other two. At this point, the parameter prior acts as a concentration parameter, focusing the probability attention on certain terms.
- On the far right, like the far left, the three \(\alpha\) are equal, the red area is centered, but the values of \(\alpha\) are all smaller, causing the red area to diverge, that is, Dirichlet believes that the three p values should be in the center, but is not very certain. The result is that there is a difference between the three p values, but the difference will not be too great (still near the center), and there will not be a very steep situation (the steepest is the infinite height at the center, with a probability of 1, so the three p values must be the same).
- The ratio of \(\alpha\) determines the location of high probability in the polynomial distribution, which mainly determines the proportions of various \(p\) , setting the concentration, while the size of \(\alpha\) determines the concentration of this location; the smaller \(\alpha\) , the more concentrated the location, the more certain the distribution of p, whereas the distribution of p is roughly determined by the position of the red area, but with a larger range of variation.
- When \(\alpha\) is much smaller than 1, the Dirichlet distribution approaches another extreme. In the example of the triangular face, the red region remains steep, but the steepness is at the three corners of the triangle. It can be imagined that \(alpha\) changes from large to 1 and then decreases, with the high-probability density region gradually spreading from the center to the entire face and then concentrating at the three corners.
- Intuitive Interpretations of the Parameters The concentration parameter Dirichlet distributions are very often used as prior distributions in Bayesian inference. The simplest and perhaps most common type of Dirichlet prior is the symmetric Dirichlet distribution, where all parameters are equal. This corresponds to the case where you have no prior information to favor one component over any other. As described above, the single value α to which all parameters are set is called the concentration parameter. If the sample space of the Dirichlet distribution is interpreted as a discrete probability distribution, then intuitively the concentration parameter can be thought of as determining how "concentrated" the probability mass of a sample from a Dirichlet distribution is likely to be. With a value much less than 1, the mass will be highly concentrated in a few components, and all the rest will have almost no mass. With a value much greater than 1, the mass will be dispersed almost equally among all the components. See the article on the concentration parameter for further discussion.
- When \(\alpha\) is much smaller than 1, the probability density will mainly accumulate on one or a few terms, that is, the red area is concentrated at the three corners. In this case, the polynomial distribution obtained from Dirichlet distribution sampling is likely to be at the corners, that is, the probability density accumulates on one term, and the probabilities of the other two terms are approximately 0. When \(\alpha\) is much larger than 1, the probability density will be dispersed to various parts, which corresponds to the leftmost figure in the three figures, and the possibility of the probabilities of the three terms being relatively similar is greater.
Role in LDA
- Summarizing conjugacy: Given a distribution A, the parameter distribution of A (or the distribution of the distribution) is B. If the posterior of B, obtained after knowledge of A's data, belongs to the same class of distribution as the prior, then A and B are conjugate, and B is called the parameter conjugate distribution of A (or the prior conjugate). In the example mentioned above, the Beta distribution is the parameter conjugate distribution of the binomial distribution, and the Dirichlet distribution is the parameter conjugate distribution of the multinomial distribution.
- LDA actually models text generation as a probabilistic generative model, specifically a three-layer Bayesian model, and assumes that the parameters of both the document-topic and topic-word multinomial distributions are prior Dirichlet distributions, using Dirichlet-Multinomial conjugacy to update its posterior with data knowledge.
- To introduce the Dirichlet-Multinomial conjugacy, it is first necessary to introduce the Gamma function and its distribution. The Gamma function extends the factorial to the real number domain. After that, the Beta function, which can estimate the distribution, is introduced. With the introduction of the Gamma function, the parameters of the Beta distribution can be extended to the real number domain. Then, the Beta-Binomial conjugacy is introduced, which brings the benefit that the form of the posterior distribution is known when correcting with data. By extending this conjugacy relationship to higher dimensions (estimating multiple distributions), the Dirichlet-Multinomial conjugacy is obtained.
- The benefit of adding Dirichlet distribution as a prior for the document-to-topic and topic-to-word polynomial distributions is that by treating polynomial parameters as variables, prior information guides the range of parameter variation rather than specific values, making the model's generalization ability stronger within small training samples.
- The size of \(\alpha\) in the Dirichlet Process reflects the degree of granularity when fitting the Base Measure with the Dirichlet distribution; the larger \(\alpha\) , the less granular, and each term receives a fairly similar probability.
- The degree of dispersion corresponds to the LDA model, representing whether the document is concentrated on a few topics or distributed relatively evenly across all topics, or whether the topics are concentrated on a few words or distributed relatively evenly across the entire vocabulary.
Gibbs Sampling
Random Simulation
- Monte Carlo method, used for known distributions, involves generating a series of random samples that satisfy this distribution and using the statistics of these samples to estimate some parameters of the original distribution that are not easily analytically computed.
- Markov refers to a method of generating random samples where the process depends on the properties of Markov chains. By constructing the transition matrix of the Markov chain, it is possible to produce a sequence of samples that satisfy a given distribution when the Markov chain converges.
- A method of MCMC is random sampling, which calculates the acceptance rate using the known distribution and only accepts a portion of the samples. Gibbs sampling is an MCMC method with an acceptance rate of 1. It improves the acceptance rate but extends the sampling process.
Mars Chain
- Markov chain refers to a state transition where the probability depends only on the previous state
- Because the transition probability only depends on the previous state, the state transition probabilities can be written as a transition probability matrix. The probability distribution of each state after n transitions is the result obtained by multiplying the initial state probability distribution vector by the nth power of the matrix
- The matrix power remains constant after a certain number of iterations, meaning each row converges to the same probability distribution, and the initial probability transition also converges to the same distribution after sufficient iterations
- On the Definition of the Convergence of Markov Chains
- If a non-periodic Markov chain has a transition probability matrix P (which may have infinitely many states), and any two states are connected (any two states can be reached through a finite number of transitions), then \(lim_{n \rightarrow \infty}P_{ij}^n\) exists and is independent of \(i\) , and this convergent matrix is denoted as \(\pi(j)\)
- \(\pi (j)=\sum _{i=0}^{\infty} \pi (i) P_{ij}\)
- \(\pi\) is the unique non-negative solution of equation \(\pi P = \pi\)
- Stable Distribution Called the Markov Chain
Markov Chain Monte Carlo
Returning to random generation, for a given probability distribution, we hope to generate the corresponding samples. An idea is to construct a Markov chain whose stationary distribution is exactly this probability distribution: because when the Markov chain converges, its stationary distribution is the probability distribution of each state. After convergence, regardless of how long a state sequence is generated through state transitions, the distribution of states in this sequence maintains the stationary distribution. If the stationary distribution is the probability distribution to be generated, then the state sequence is a random sample sequence under the given probability distribution.
Therefore, the issue is how to construct the state transition matrix of a Markov chain given a stationary distribution. It mainly utilizes the detailed stationary condition of non-periodic Markov chains: if \(\pi(i)P_{ij}=\pi(j)P_{ij} \quad for \quad all \quad i,j\) , then \(\pi(x)\) is the stationary distribution of the Markov chain. A physical interpretation of this theorem is: if the probability mass of state i is stable, then the probability mass of the change from state i to state j is exactly complementary to the probability mass of the change from state j to state i.
The probability of transitioning from state i to state j is denoted as \(q(i,j)\) . If \(p(i)q(i,j)=p(j)q(j,i)\) , then \(p(x)\) is the stationary distribution of this Markov chain, and the transition matrix does not need to be changed. However, in general, your luck is not that good. In the case of knowing \(p(x)\) , we need to modify \(q\) . To do this, we multiply by an acceptance rate \(\alpha\) , so that:
\[ p(i)q(i,j)\alpha (i,j)=p(j)q(j,i)\alpha (j,i) \]
Why is it called the acceptance rate? Because it can be understood that this \(\alpha\) is multiplied by a probability after the original state transition, representing whether this transition is accepted.
How to determine the acceptance rate? In fact, it is self-evident \(\alpha (i,j)=p(j)q(j,i)\) , symmetric construction will suffice.
Therefore, after each transition, we sample a variable from a uniform distribution, and if the variable is less than the acceptance rate, we transition according to the original transition matrix; otherwise, we do not transition.
Such MCMC sampling algorithms have a problem: we actually did not modify the original transition probability matrix q, but calculated the acceptance rate based on q to ensure convergence to p. However, the acceptance rate may be calculated to be very small, leading to the state remaining stationary for a long time and slow convergence. In fact, multiplying both sides of the formula \(p(i)q(i,j)\alpha (i,j)=p(j)q(j,i)\alpha(j,i)\) by a multiple does not break the detailed balance condition, but the acceptance rate is improved. Therefore, it is sufficient to multiply both sides of the acceptance rate by a multiple and ensure that the two acceptance rates, after doubling, do not exceed 1. The general practice is to multiply the larger acceptance rate by 1. At this point, the most common MCMC method is obtained: the Metropolis-Hastings algorithm.
Gibbs Sampling
The previous discussion mentioned that MCMC actually does not alter the transition probability matrix, thus requiring an acceptance rate supplement. Even after scaling, there is always an acceptance rate less than 1, which reduces the convergence efficiency. Gibbs sampling aims to find a transition matrix Q such that the acceptance rate equals 1.
For the two-dimensional probability distribution \(p(x,y)\) , it is easy to obtain
\[ \begin{aligned} p(x_1,y_1)p(y_2|x_1) & =p(x_1)p(y_1|x_1)p(y_2|x_1) \\ & =p(x_1)p(y_2|x_1)p(y_1|x_1) \\ & =p(x_1,y_2)p(y_1|x_1) \\ \end{aligned} \]
From the left-hand side to the final form, this type is very similar to the detailed balance condition! In fact, if \(x=x_1\) is fixed, then \(p(y|x_1)\) can serve as the transition probability between any two different y-values on the line \(x=x_1\) . And this transition satisfies the detailed balance condition. Fixing y yields the same conclusion, therefore, between any two points in this two-dimensional plane, we can construct a transition probability matrix:
- If two points are on the vertical line \(x=x_1\) , then \(Q=p(y|x_1)\)
- If two points are on the horizontal line \(y=y_1\) , then \(Q=p(x|y_1)\)
- If the line connecting two points is neither vertical nor horizontal, then applying the transition matrix Q to any two points on the plane in such a way satisfies the detailed balance condition; the Markov chain on this two-dimensional plane will converge to \(p(x,y)\) .
After Gibbs sampling yields a new x dimension, the calculation of the new y dimension depends on the new x dimension because it is based on the previously selected coordinate axis transformation; otherwise, it cannot jump to the new state \((x_2,y_2)\) . What you actually get is \((x_1,y_2)\) and \((x_2,y_1)\) .
Therefore, given a two-dimensional probability distribution, the transition probabilities along the horizontal or vertical directions satisfying the detailed balance condition on this plane can be calculated. Starting from any state on the plane, a single transition only changes the abscissa or ordinate, that is, it moves horizontally or vertically. From the formula of the detailed balance condition, it can be seen that this balance is transitive; if the transition in one dimension satisfies the balance condition and is followed by another dimension, then the equivalent single transition of the two transitions is also balanced.
After all dimensions have been transferred once, a new sample is obtained. The sample sequence formed after the Markov chain converges is the random sample sequence we need. The state transition can be a cyclic transformation of the coordinate axes, i.e., this time horizontal transformation, next time vertical transformation, or it can be randomly selected each time. Although randomly selecting the coordinate axis each time will result in different new dimension values calculated in the middle, the stationary condition is not broken, and it can eventually converge to the same given distribution.
Similarly, the aforementioned algorithm can be generalized to multi-dimensional spaces. When generalized to multi-dimensional spaces, the transition probability constructed on the \(x\) axis is \(Q=p(x|¬ x)\) . It is noteworthy that the sampling samples obtained from the above method are not mutually independent, but only conform to the given probability distribution.
Role in LDA
- Firstly, it is clear that the MCMC method is used to generate samples from a known distribution, but Gibbs sampling only requires the use of complete conditional probabilities, generating samples that satisfy the joint distribution, unlike general sampling methods that directly sample from the joint distribution
- Gibbs sampling has this characteristic that allows it to infer parameters without knowing the joint probability, and further derive the joint probability distribution
- However, in LDA, Gibbs sampling is not used to directly infer parameters, but rather to approximate the posterior, completing the step of updating the prior with data knowledge. Moreover, since LDA has the hidden variable of topics, the joint distribution of Gibbs sampling is not the topic distribution of documents or the word distribution of topics, and is not directly linked to the parameters of the LDA model. Gibbs sampling in LDA samples the topic assignment of tokens, i.e., the distribution of the hidden variables.
- However, after all token themes are assigned, the parameters of the LDA model are determined, and two multinomial distributions (parameters) can be obtained through classical probability (maximum likelihood estimation), and the corresponding Dirichlet distribution (posterior distribution of parameters) is also updated. Moreover, since the document-word matrix is decomposed into themes, in fact, we do not need to maintain the \(Document \* word\) matrix, but rather maintain the \(Document \* topic + topic \* word\) matrix.
- Gibbs sampling word topic assignment is actually calculating the posterior distribution of latent variables, thereby obtaining the posterior distribution of parameters.
- In Gibbs sampling, parameters are continuously updated, for instance, if the update in this iteration is \(p(x_1^{t+1})=p(x_1|x_2^t,x_3^t)\) , the next iteration becomes \(p(x_2^{t+1})=p(x_2|x_1^{t+1},x_3^t)\) , using the updated \(x_1^{t+1}\) for calculation. In LDA, this process is achieved by updating the topic of the sampled word. In Bayesian inference, data is divided into batches, and the posterior updates the prior in an iterative manner, which is further refined to each coordinate update in Gibbs sampling.
- The Gibbs sampling formula can be seen below, which can be interpreted as determining one's own theme distribution based on the thematic distribution of other words, and iteratively updating the thematic distribution of all words; how to determine it includes two parts, which are similar to the information provided by tf and idf.
- When calculating the posterior distribution of topic assignments based on the sampling formula, we do not directly obtain the posterior distribution of the parameters. However, after sampling new topics based on the posterior distribution of topic assignments and updating the statistics, since the Gibbs sampling formula itself includes the statistics, this is equivalent to completing the calculation of the posterior and updating the prior with a single step. Alternatively, it can also be understood that in LDA, we are always performing Bayesian inference on the distribution of topic assignments (latent variables), i.e., \(p(topic|word,doc)\) , and after completing this, performing a maximum likelihood estimation (classical type) based on the topic assignments allows us to obtain the parameters of the model.
Text Modeling
- Next, we discuss how to perform probabilistic modeling on text. The
basic idea is that we assume all words in a document are generated
according to a pre-set probability distribution, and we aim to find this
probability distribution. Specifically, this is divided into the
following two tasks:
- What is the model like?
- What is the generation probability of each word or the model parameters?
Unigram model
What is the model like? The traditional unigram model, also known as the one-gram model, assumes that the generation of words is independent of each other; documents and words are independently exchangeable, regardless of order, as if all words are placed in a bag and a word is taken out each time according to a probability distribution, hence also known as the bag-of-words (BoW) model. The parameters of the bag-of-words model are the generation probabilities of each word, and the frequentist view holds that generation probabilities can be determined through word frequency statistics.
Here introduces a Bayesian framework for unigrams, laying the groundwork for the derivation of the two-layer Bayesian framework for LDA in the following text. The Bayesian school believes that the generation of words is not only one layer: there are many kinds of probability distributions for word probabilities, and the probability distribution itself also follows a probability distribution, as if God has many dice, he picks one die and throws it again, generating a word.
That is, the next document of the Unigram model is just a bag of words, with the generation of these words following a distribution, denoted as \(\mathop{p}^{\rightarrow}\) , and the distribution of word generation itself also follows a distribution, denoted as \(p(\mathop{p}^{\rightarrow})\) . Translated into mathematical formulas, the above two distributions represent the generation probability of a document:
\[ p(W)=\int p(W|\mathop{p}^{\rightarrow})p(\mathop{p}^{\rightarrow})d\mathop{p}^{\rightarrow} \]
In the view of the Bayesian school, we should first assume a prior distribution, and then correct it using training data. Here, we need to assume \(p(\mathop{p}^{\rightarrow})\) , which is the prior of the distribution, and what is the training data? It is the word frequency distribution extracted from the corpus. Assuming \(\mathop{n}^{\rightarrow}\) is the word frequency sequence of all words, then this sequence satisfies the multinomial distribution:
\[ \begin{aligned} p(\mathop{n}^{\rightarrow}) &= Mult(\mathop{n}^{\rightarrow}|\mathop{p}^{\rightarrow},N) \\ &= C_N ^{\mathop{n}^{\rightarrow}} \prod_{k=1}^V p_k^{n_k} \\ \end{aligned} \]
Since the training data satisfies multiple distributions, we naturally want to utilize the Dirichlet-Multinomial conjugacy, thus assuming the prior distribution of \(p(\mathop{p}^{\rightarrow})\) to be the Dirichlet distribution:
\[ Dir(\mathop{p}^{\rightarrow}|\mathop{\alpha}^{\rightarrow})=\frac{1}{\int \prod_{k=1}^V p_k^{\alpha _k -1}d\mathop{p}^{\rightarrow}} \prod_{k=1}^V p_k^{\alpha _k -1} \]
\(V\) is the size of the corpus dictionary, and the parameters \(\alpha\) of the Dirichlet distribution need to be set manually. After that, the posterior distribution of \(p(\mathop{p}^{\rightarrow})\) is obtained based on the conjugate after data correction:
\[ \begin{aligned} p(\mathop{p}^{\rightarrow}|W,\mathop{\alpha}^{\rightarrow}) &= Dir(\mathop{p}^{\rightarrow}|\mathop{\alpha}^{\rightarrow})+MultCount(\mathop{n}^{\rightarrow}) \\ &= Dir(\mathop{p}^{\rightarrow}|\mathop{\alpha}^{\rightarrow}+\mathop{n}^{\rightarrow}) \\ \end{aligned} \]
After obtaining the posterior, one can use maximum likelihood estimation or mean estimation to calculate \(\mathop{p}^{\rightarrow}\) , here we use the mean of the Dirichlet distribution from the posterior to estimate, combining the previously mentioned properties of the Dirichlet distribution, we have:
\[ \mathop{p_i}^{~}=\frac{n_i+\alpha _i}{\sum _{i=1}^{V} (n_i+\alpha _i)} \]
The physical interpretation of this formula: Unlike the general use of word frequency as an estimate, we first assume the word frequency (i.e., the prior pseudo-count \(\alpha _i\) ), then add the word frequency given by the data \(n_i\) , and normalize it as a probability.
Now that the probability distribution of word generation \(\mathop{p}^{\rightarrow}\) has been obtained, the generation probability of documents under this distribution is obviously:
\[ p(W|\mathop{p}^{\rightarrow})=\prod _{k=1}^V p_k^{n_k} \]
The distribution of word generation probabilities, by bringing the conditional generation probability of documents under the word generation distribution into the previously mentioned document probability integral formula, yields the generation probability of the document under all distribution scenarios. Substituting and simplifying it results in a very nice formula.
\[ p(W|\mathop{\alpha}^{\rightarrow})=\frac{\Delta(\mathop{\alpha}^{\rightarrow}+\mathop{n}^{\rightarrow})}{\Delta(\mathop{\alpha}^{\rightarrow})} \]
\(\Delta\) is the normalization factor:
\[ \Delta(\mathop{\alpha}^{\rightarrow})=\int \prod _{k=1}^V p_k^{\alpha _k -1}d\mathop{p}^{\rightarrow} \]
PLSA model
- PLSA, or Probabilistic Latent Semantic Analysis model, posits that there exists an implicit thematic hierarchy between documents and words. Documents contain multiple themes, each corresponding to a distribution of words. When generating words, the model first selects a theme and then selects words from within that theme to generate them (in actual computation, it is the probability summation of each theme).
- Compared to the unigram model without Bayes, PLSA adds an additional layer of topics between documents and words.
- PLSA does not introduce Bayesian, it is just a model containing latent variables, performing maximum likelihood estimation, so the parameters can be iteratively learned using the EM algorithm, and the specific calculations are omitted here.
Role in LDA
- Now, let's organize, the Unigram model mainly includes two parts
- Word Generation Probability Distribution
- Parameter Distribution of Word Generation Probability Distribution
- PLSA model mainly consists of two parts
- Word Generation Probability Distribution
- Subject Generation Probability Distribution
- The Unigram model exhibits the distribution of the distribution, which is the significance of introducing parameter priors for the word distribution: making the word distribution a variable, turning the selection of a word from rolling a die into first selecting a die, and then rolling it to choose a word. Whether the introduction of priors is actually useful is a topic of contention between the Bayesian school and the frequentist school.
- PLSA model provides a very intuitive modeling for human language generation, introducing topics as implicit semantics, and defining the distribution of topic representative words, viewing articles as a mixture of topics.
LDA text modeling
Model Overview
- LDA integrates the advantages of Unigram and PLSA, adding Dirichlet
prior assumptions for the word and topic dice respectively
- Word Generation Probability Distribution (Temporarily Noted as A)
- Parameter Distribution of Word Generation Probability Distribution (temporarily noted as B)
- Subject Generation Probability Distribution (Temporarily Noted as C)
- Parameter Distribution of the Probability Distribution of Topic Generation (temporarily denoted as D)
- It is easy for beginners to confuse that the topic generation
probability distribution is not the parameter distribution of the word
generation probability distribution; one must distinguish the
hierarchical relationship in the LDA model from the conjugate
relationships within each level. Additionally, the relationship between
topics and words is not one-to-many; they are many-to-many. In fact, in
the LDA model, a document is generated in this way (assuming there are K
topics):
- Sample K from the A distribution under the condition of the B distribution
- For each document, a C distribution is obtained by drawing under the
condition of the D distribution, and the following process is repeated
to generate words:
- From a C distribution, a topic z is sampled
- From the z-th A distribution, a word is sampled
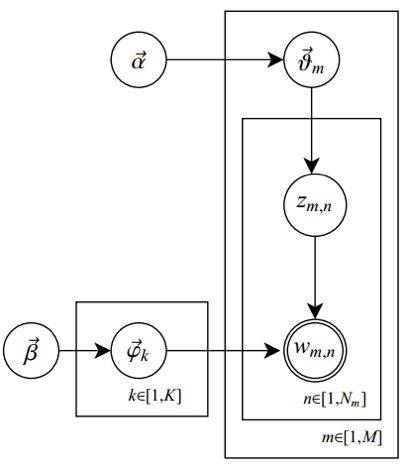
- Assuming there are \(m\) documents, \(n\) words, and \(k\) topics, then \(D+C\) is \(m\) independent Dirichlet-Multinomial conjugates, and \(B+A\) is \(k\) independent Dirichlet-Multinomial conjugates. The two Dirichlet parameters are a k-dimensional vector ( \(\alpha\) ) and an n-dimensional vector ( \(\beta\) ). Now we can understand the illustration at the beginning of this paper, where we express the symbols in their actual meanings, corresponding to the title illustration. This illustration actually describes these \(m+k\) independent Dirichlet-Multinomial conjugates in LDA:
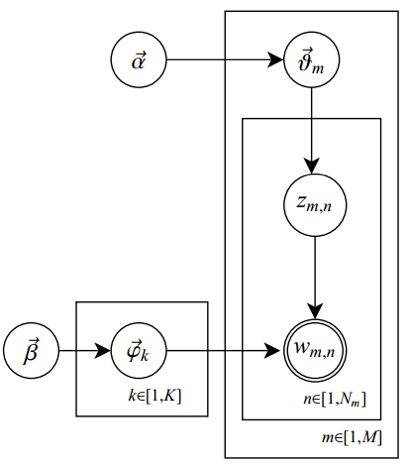
Establish distribution
Now we can model the LDA topic model with \(m+k\) Dirichlet-Multinomial conjugate pairs, drawing on the final document generation distribution derived from the derivation of the Unigram model, we can separately calculate:
\[ \begin{aligned} p(\mathop{z}^{\rightarrow}|\mathop{\alpha}^{\rightarrow}) = \prod _{m=1}^M \frac{\Delta(\mathop{n_m}^{\rightarrow}+\mathop{\alpha}^{\rightarrow})}{\Delta(\mathop{\alpha}^{\rightarrow})} \\ p(\mathop{w}^{\rightarrow}|\mathop{z}^{\rightarrow},\mathop{\beta}^{\rightarrow}) = \prod _{k=1}^K \frac{\Delta(\mathop{n_k}^{\rightarrow}+\mathop{\beta}^{\rightarrow})}{\Delta(\mathop{\beta}^{\rightarrow})} \\ \end{aligned} \]
The final result is the joint distribution of words and topics:
\[ p(\mathop{w}^{\rightarrow},\mathop{z}^{\rightarrow}|\mathop{\alpha}^{\rightarrow},\mathop{\beta}^{\rightarrow}) = \prod _{m=1}^M \frac{\Delta(\mathop{n_m}^{\rightarrow}+\mathop{\alpha}^{\rightarrow})}{\Delta(\mathop{\alpha}^{\rightarrow})} \prod _{k=1}^K \frac{\Delta(\mathop{n_k}^{\rightarrow}+\mathop{\beta}^{\rightarrow})}{\Delta(\mathop{\beta}^{\rightarrow})} \]
Sampling
We mentioned earlier that we estimate model parameters within the framework of Bayesian inference, which requires us to obtain the posterior probability of topic assignments; here, Gibbs sampling is needed to help approximate the posterior
According to the definition of Gibbs sampling, we need to sample using the fully conditional probability of topic assignments \(p(z_i=k|\mathop{z_{¬ i}}^{\rightarrow},\mathop{w}^{\rightarrow})\) , to approximate \(p(z_i=k|\mathop{w}^{\rightarrow})\) , \(z_i\) , which represent the topic of the ith word (here the subscript i represents the nth word in the mth document), while the vector w represents all the words we are currently observing.
After establishing the entire probability model, we trained it using the following methods: we set the hyperparameters, randomly initialized various word frequency statistics (including the number of words of topic k in article m, the number of words of vocabulary t belonging to topic k, the total number of words in article m, and the total number of words in topic k), then sequentially performed Gibbs sampling on all words in the corpus, sampled their topics, and assigned this topic to the word, and updated the four word frequencies (i.e., using conjugate posterior updates), cyclically sampled until convergence, that is, the topic distribution after sampling basically conforms to the topic distribution generated by the model under the posterior probability, and the data can no longer provide more knowledge to the model (no longer updated).
- Gibbs sampling requires restricting a certain dimension, sampling according to the conditional probability of the other dimensions, in text topic modeling, the dimension is the word, and calculating the conditional probability of the other dimensions is to exclude the count of the current word and its topic from the four word frequencies.
- After sampling the topic, assign this topic to words, increase the frequency counts of four words, if it has converged, then the topic before and after sampling is the same, and if the word frequencies have not changed, it is equivalent to the posterior not being updated with knowledge from the data.
Formula Derivation: The following section introduces two derivation methods, the first being the derivation based on the conjugate relationship as presented in the article "LDA Mathematical Mysteries," and the second being the derivation based on the joint distribution as described in the article "Parameter Estimation for Text Analysis."
Based on the conjugation relationship, the following derivation is obtained:
The object of the sample is the theme corresponding to the word, with a probability of:
\[ p(z_i=k|\mathop{w}^{\rightarrow}) \]
Using Gibbs sampling to sample the topic of a word requires calculating conditional probabilities with the topics of other words as conditions:
\[ p(z_i=k|\mathop{z_{¬ i}}^{\rightarrow},\mathop{w}^{\rightarrow}) \]
By Bayes' theorem, this conditional probability is proportional to (sampling, we can scale up the probabilities of each sample proportionally):
\[ p(z_i=k,w_i=t|\mathop{z_{¬ i}}^{\rightarrow},\mathop{w_{¬ i}}^{\rightarrow}) \]
Expand this formula according to thematic distribution and word distribution:
\[ \int p(z_i=k,w_i=t,\mathop{\vartheta _m}^{\rightarrow},\mathop{\varphi _k}^{\rightarrow}|\mathop{z_{¬ i}}^{\rightarrow},\mathop{w_{¬ i}}^{\rightarrow})d\mathop{\vartheta _m}^{\rightarrow} d\mathop{\varphi _k}^{\rightarrow} \]
Since all the conjugates are independent, the above expression can be written as:
\[ \int p(z_i=k,\mathop{\vartheta _m}^{\rightarrow}|\mathop{z_{¬ i}}^{\rightarrow},\mathop{w_{¬ i}}^{\rightarrow})p(w_i=t,\mathop{\varphi _k}^{\rightarrow}|\mathop{z_{¬ i}}^{\rightarrow},\mathop{w_{¬ i}}^{\rightarrow})d\mathop{\vartheta _m}^{\rightarrow} d\mathop{\varphi _k}^{\rightarrow} \]
The probability chain is decomposed, and since the two expressions are respectively related to the topic distribution and the word distribution, they can be written as the product of two integrals:
\[ \int p(z_i=k|\mathop{\vartheta _m}^{\rightarrow})p(\mathop{\vartheta _m}^{\rightarrow}|\mathop{z_{¬ i}}^{\rightarrow},\mathop{w_{¬ i}}^{\rightarrow})d\mathop{\vartheta _m}^{\rightarrow} \cdot \int p(w_i=t|\mathop{\varphi _k}^{\rightarrow})p(\mathop{\varphi _k}^{\rightarrow}|\mathop{z_{¬ i}}^{\rightarrow},\mathop{w_{¬ i}}^{\rightarrow})d\mathop{\varphi _k}^{\rightarrow} \]
Given the topic distribution of the mth document and the distribution of the kth topic word, we seek the probability of the ith word being t and the probability that the ith word corresponds to the kth topic, then it is obvious that:
\[ p(z_i=k|\mathop{\vartheta _m}^{\rightarrow})=\mathop{\vartheta _{mk}} \\ p(w_i=t|\mathop{\varphi _k}^{\rightarrow})=\mathop{\varphi _{kt}} \\ \]
And according to the conjugate relationship, there is
\[ p(\mathop{\vartheta _m}^{\rightarrow}|\mathop{z_{¬ i}}^{\rightarrow},\mathop{w_{¬ i}}^{\rightarrow})=Dir(\mathop{\vartheta _m}^{\rightarrow}|\mathop{n_{m,¬ i}}^{\rightarrow}+\mathop{\alpha}^{\rightarrow}) \\ p(\mathop{\varphi _k}^{\rightarrow}|\mathop{z_{¬ i}}^{\rightarrow},\mathop{w_{¬ i}}^{\rightarrow})=Dir(\mathop{\varphi _k}^{\rightarrow}|\mathop{n_{k,¬ i}}^{\rightarrow}+\mathop{\beta}^{\rightarrow}) \\ \]
Therefore, the entire expression can be regarded as the product of the k-th and t-th terms of the expected vectors of two Dirichlet distributions. According to the properties of Dirichlet previously mentioned, it is easy to obtain that these expectations are fractional values obtained in proportion to the Dirichlet parameters, so the final probability calculation is (note that it is proportional to):
\[ p(z_i=k|\mathop{z_{¬ i}}^{\rightarrow},\mathop{w}^{\rightarrow})∝\frac{n_{m,¬ i}^{(k)}+\alpha _k}{\sum _{k=1}^K (n_{m,¬ i}^{(k)}+\alpha _k)} \cdot \frac{n_{k,¬ i}^{(t)}+\beta _t}{\sum _{t=1}^V (n_{k,¬ i}^{(t)}+\beta _t)} \]
This probability can be understood as (excluding the current i-th token):
\[ (文档m中主题k所占的比例) * (主题k中词t所占的比例) \]
Observed that the denominator of the first term is the sum of the subject, which is actually unrelated to k, therefore it can be written as:
\[ p(z_i=k|\mathop{z_{¬ i}}^{\rightarrow},\mathop{w}^{\rightarrow})∝ (n_{m,¬ i}^{(k)}+\alpha _k) \cdot \frac{n_{k,¬ i}^{(t)}+\beta _t}{\sum _{t=1}^V (n_{k,¬ i}^{(t)}+\beta _t)} \]
We take another look at how to derive based on the joint distribution
We have previously obtained the joint distribution of words and topics:
\[ p(\mathop{w}^{\rightarrow},\mathop{z}^{\rightarrow}|\mathop{\alpha}^{\rightarrow},\mathop{\beta}^{\rightarrow}) = \prod _{m=1}^M \frac{\Delta(\mathop{n_m}^{\rightarrow}+\mathop{\alpha}^{\rightarrow})}{\Delta(\mathop{\alpha}^{\rightarrow})} \prod _{k=1}^K \frac{\Delta(\mathop{n_k}^{\rightarrow}+\mathop{\beta}^{\rightarrow})}{\Delta(\mathop{\beta}^{\rightarrow})} \]
According to Bayes' formula, there is
\[ p(z_i=k|\mathop{z_{¬ i}}^{\rightarrow},\mathop{w}^{\rightarrow})=\frac{p(\mathop{w}^{\rightarrow},\mathop{z}^{\rightarrow})}{p(\mathop{w}^{\rightarrow},\mathop{z_{¬ i}}^{\rightarrow})} \\ =\frac{p(\mathop{w}^{\rightarrow}|\mathop{z}^{\rightarrow})} {p(\mathop{w_{¬ i}}^{\rightarrow}|\mathop{z_{¬ i}}^{\rightarrow})p(w_i)} \cdot \frac{p(\mathop{z}^{\rightarrow})} {\mathop{p(z_{¬ i})}^{\rightarrow}} \\ \]
Since \(p(w_i)\) is an observable variable, we omit it, obtaining an expression proportional to it. We then express this expression in the form of \(\Delta\) (fraction divided by fraction, the denominators cancel each other out):
\[ ∝ \frac{\Delta(\mathop{n_{z}}^{\rightarrow})+\mathop{\beta}^{\rightarrow}}{\Delta(\mathop{n_{z,¬ i}}^{\rightarrow})+\mathop{\beta}^{\rightarrow}} \cdot \frac{\Delta(\mathop{n_{m}}^{\rightarrow})+\mathop{\alpha}^{\rightarrow}}{\Delta(\mathop{n_{m,¬ i}}^{\rightarrow})+\mathop{\alpha}^{\rightarrow}} \]
By substituting the expression of \(\Delta\) into the calculation, we can also obtain:
\[ p(z_i=k|\mathop{z_{¬ i}}^{\rightarrow},\mathop{w}^{\rightarrow})∝ (n_{m,¬ i}^{(k)}+\alpha _k) \cdot \frac{n_{k,¬ i}^{(t)}+\beta _t}{\sum _{t=1}^V (n_{k,¬ i}^{(t)}+\beta _t)} \]
Text Analysis: A Pseudo-Algorithm Diagram of Gibbs Sampling for Parameter Estimation

It can be seen that the conditional probability is mainly calculated by recording four n values (two matrices and two vectors), and the topic is also updated by updating four n values for incremental updates. The algorithm first assigns initial values by random uniform sampling, and then updates the topic according to the sampling formula (first subtracting the old topic distribution and then adding the new topic distribution), where formula 78 is the \(p(z_i=k|\mathop{z_{¬ i}}^{\rightarrow},\mathop{w}^{\rightarrow})\) we calculated previously, and formulas 81 and 82 are the \(\mathop{\vartheta _{mk}},\mathop{\varphi _{kt}}\) . We can directly obtain them from the four n values, without considering the \(¬ i\) condition during sampling, specifically:
\[ \mathop{\vartheta _{mk}} = \frac{n_{m}^{(k)}+\alpha _k}{\sum _{k=1}^K (n_{m}^{(t)}+\alpha _k)} \\ \mathop{\varphi _{kt}} = \frac{n_{k}^{(t)}+\beta _t}{\sum _{t=1}^V (n_{k}^{(t)}+\beta _t)} \]
Training and Testing
- Next, we train the LDA model, first randomly initializing the
Dirichlet parameters (prior), then using text to supplement data
knowledge, and finally obtaining the correct posterior. The training
process is iterative:
- Iterate what? Sample and update the themes corresponding to the words
- What iteration? The complete conditional probability of Gibbs sampling
- Iterative effects? Changes in topic allocation, changes in statistics, and changes in the fully conditional probability for the next Gibbs sampling
- When to iterate? Gibbs sampling converges, i.e., the distribution of topics stabilizes and remains unchanged over a certain time interval, or the degree of model convergence is measured according to perplexity and other indicators.
- The difference between training and testing lies in that training involves sampling and updating the entire document collection, with both document-to-topic and topic-to-word distributions being updated, whereas testing retains the topic-to-word distribution unchanged, only sampling the current test document to convergence to obtain the topic distribution of that document.
- In fact, the two hyperparameters \(\alpha\) and \(\beta\) have undergone many iterations of posterior substitution for prior after training, with the parameter values becoming very large. \(\alpha\) discarded the final posterior result, and re-used the initial prior values when generating the topic distribution for new documents. This means that the document-to-topic distributions obtained during the training set are actually not usable when testing new documents. We utilize the topic-to-word distribution: because only the set of topics is for the entire document space (training set and test set), the topic-to-word distribution is also established on the dictionary of the entire document space. We retain the final posterior results for these k \(\beta\) vectors because this posterior has absorbed the likelihood knowledge of the data, resulting in large parameter values and small uncertainty. Essentially, each \(\beta\) vector is equivalent to determining a polynomial distribution from a topic to words, which is to say determining a topic. We use these determined topics to test the distribution of a new document across various topics. Therefore, when testing new documents, the parameter \(\alpha\) is generally set to be symmetric, i.e., with equal components (without prior preference for any particular topic), and with small values (i.e., high uncertainty; otherwise, the generated topic distribution would be uniform), which is analogous to the idea of maximum entropy. The test is conducted by using known fixed topics to obtain the document-to-topic distribution.
- LDA training is actually an unparameterized Bayesian inference, which can be implemented using MCMC and non-MCMC methods. Among the MCMC methods, Gibbs sampling is often used, while non-MCMC methods can employ variational inference and other iterative approaches to obtain parameters.
LDA in Gensim
- Gensim's LDA provides several parameters, among which the default
value for \(\alpha\) is as follows:
alpha ({numpy.ndarray, str}, optional) – Can be set to an 1D array of length equal to the number of expected topics that expresses our a-priori belief for the each topics’ probability. Alternatively, default prior selecting strategies can be employed by supplying a string: 'asymmetric': Uses a fixed normalized asymmetric prior of 1.0 / topicno. 'default': Learns an asymmetric prior from the corpus.
- gensim does not expose \(\beta\) to users; users can only set \(\alpha\) , which can be customized and can also be set as symmetric or asymmetric. The symmetric setting means all are 1, while the asymmetric setting fits the Zipf law (?), and it is possible that \(\beta\) has an asymmetric default setting.
More
Parameter estimation for text analysis points out that hidden topics actually come from high-order co-occurrence relationships between words
LDA is used for document query, where LDA is trained on candidates, and a test is conducted each time a new query is received
Based on a similarity ranking method, the similarity between the topic distribution of candidates and queries is calculated using JS distance or KL divergence, and then sorted
Based on the Predictive likelihood ranking method, calculate the probability of each candidate appearing for a given query, based on thematic decomposition of topic z:
\[ \begin{aligned} p\left(\vec{w}_{m} | \tilde{\vec{w}}_{\tilde{m}}\right) &=\sum_{k=1}^{K} p\left(\vec{w}_{m} | z=k\right) p\left(z=k | \tilde{\vec{w}}_{\tilde{m}}\right) \\ &=\sum_{k=1}^{K} \frac{p\left(z=k | \vec{w}_{m}\right) p\left(\vec{w}_{m}\right)}{p(z=k)} p\left(z=k | \tilde{\vec{w}}_{\tilde{m}}\right) \\ &=\sum_{k=1}^{K} \vartheta_{m, k} \frac{n_{m}}{n_{k}} \vartheta_{\tilde{m}, k} \end{aligned} \]
LDA for clustering
- In fact, the distribution of topics is a soft clustering division of documents. If each document is assigned to the topic with the highest probability, that would be a hard division.
- Or use topic distribution as the feature vector of the document and then further cluster using various clustering algorithms
- Evaluation of clustering results can utilize a known clustering partitioning result as a reference, and assess using the Variation of Information distance
LDA evaluation metrics, perplexity, defined as the reciprocal geometric mean of the likelihood measured on the validation set:
\[ \mathrm{P}(\tilde{\boldsymbol{W}} | \boldsymbol{M})=\prod_{m=1}^{M} p\left(\tilde{\vec{w}}_{\tilde{m}} | \mathcal{M}\right)^{-\frac{1}{N}}=\exp -\frac{\sum_{m=1}^{M} \log p\left(\tilde{\bar{w}}_{\tilde{m}} | \mathcal{M}\right)}{\sum_{m=1}^{M} N_{m}} \]
Assuming the distribution of the validation set and the training set is consistent, a high perplexity of LDA on the validation set indicates a larger entropy, greater uncertainty, and that the model has not yet learned a stable parameter.