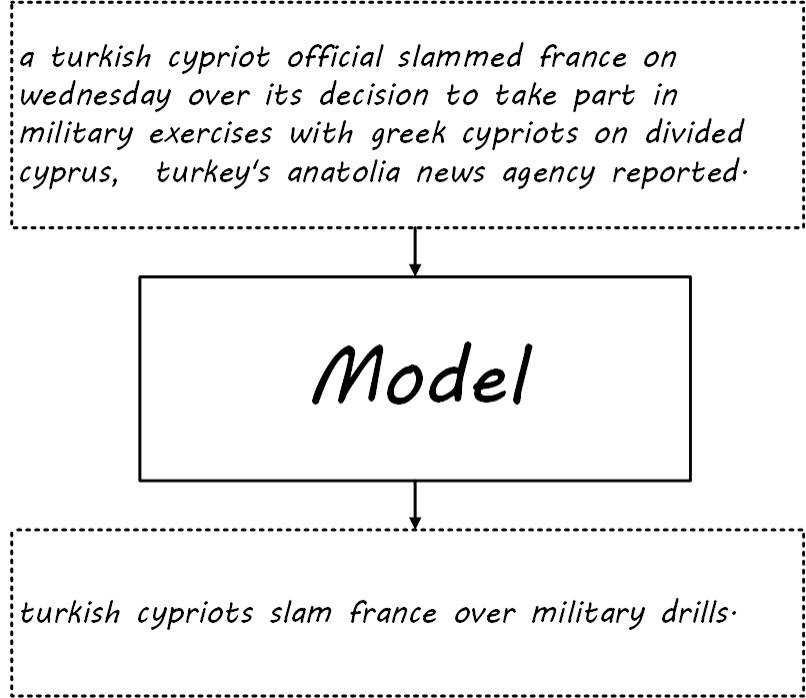
Seq2seq based Summarization

A bachelor’s graduation project involves developing a short sentence summarization model based on seq2seq and designing an emotional fusion mechanism. Now, let’s provide a brief summary of the entire model

Task
- Automatic text summarization is a type of natural language processing (NLP) task. For a longer text, it generates a short text that covers the core meaning of the original text, which is the summary of the original text. Automatic summarization technology refers to constructing mathematical models on computers, inputting long texts into the model, and then automatically generating short summaries through computation. According to the scale of the corpus needed for generating summaries and the scale of the summaries, summaries can be divided into multi-document summaries, long document summaries, and short document summaries. This paper mainly studies short document summarization: for a sentence or a few sentences of text, generate a short summary that summarizes the key information of the original text, and is fluent and readable, trying to reach the level of summaries written by human authors.
- Automatic text summarization is divided into extraction-based and generation-based methods, the former being the extraction of original sentences to form the summary, and the latter being the generation of the summary through a deep learning model, character by character. This paper mainly focuses on the generation of summaries and abstracts the problem into generating a short sentence of an average length of 8 words from a long sentence with an average length of 28 words.
Preparatory Knowledge
Recurrent Neural Network
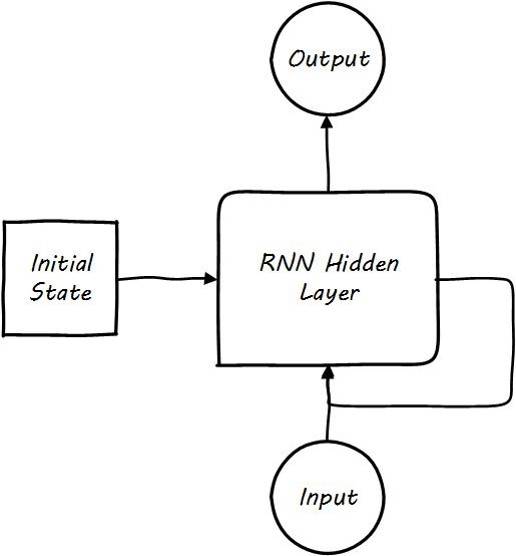
- Recurrent Neural Network (RNN), a variant of neural networks, is capable of effectively processing sequential data. All its hidden layers share parameters, with each hidden layer not only depending on the current moment’s input but also on the state of the previous hidden layer. The data flow is not propagated between network layers as in traditional neural networks, but rather circulates as a state within its own network.
![i0TtUA.jpg]()
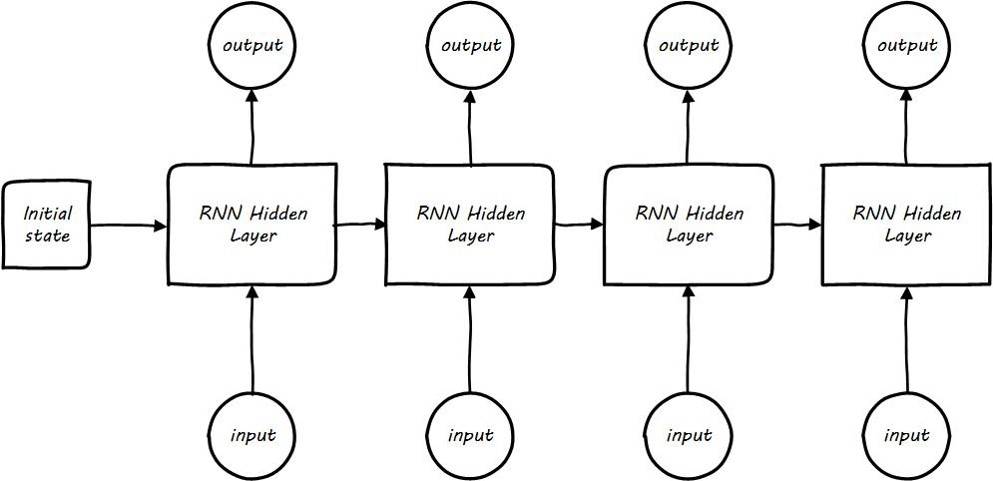
- After time step expansion:
![i0TN4I.jpg]()
LSTM and GRU
Recurrent neural networks can effectively capture the sequential information of sequence data and can construct very deep neural networks without generating a large number of parameters to be learned; however, due to parameter sharing, when gradients are chain-derived through time steps, it is equivalent to matrix power operations. If the eigenvalues of the parameter matrix are too small, it will cause gradient diffusion, and if the eigenvalues are too large, it will cause gradient explosion, affecting the backpropagation process, i.e., the long-term dependency problem of RNNs. When dealing with long sequence data, the long-term dependency problem can lead to the loss of long-term memory information in the sequence. Although people have tried to alleviate this problem by introducing gradient truncation and skip connection techniques, the effect is not significant until the long short-term memory neural networks and gated recurrent neural networks, as extended forms of RNNs, effectively solve this problem.
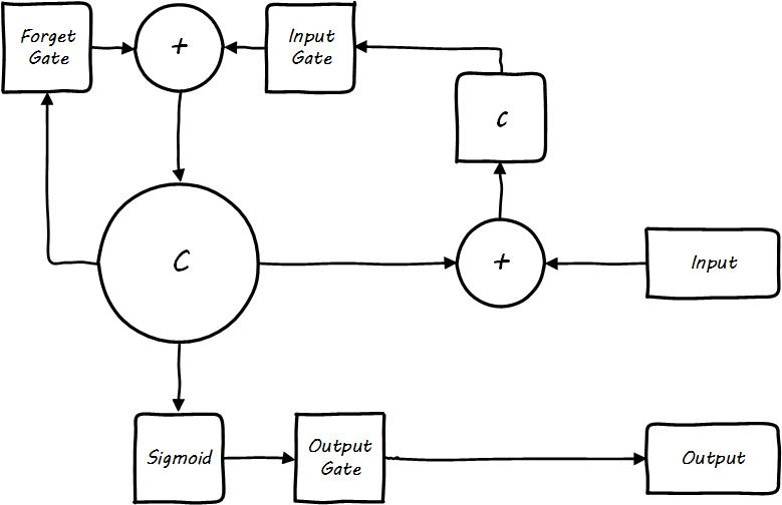
LSTM stands for Long Short-Term Memory, a type of neural network that introduces gate units in its nodes to capture long-term memory information. These gate units, as part of the network parameters, participate in training and control the extent to which the current hidden layer node memory (forgetting) past information and accepts new memory input.
![i0TaCt.jpg]()
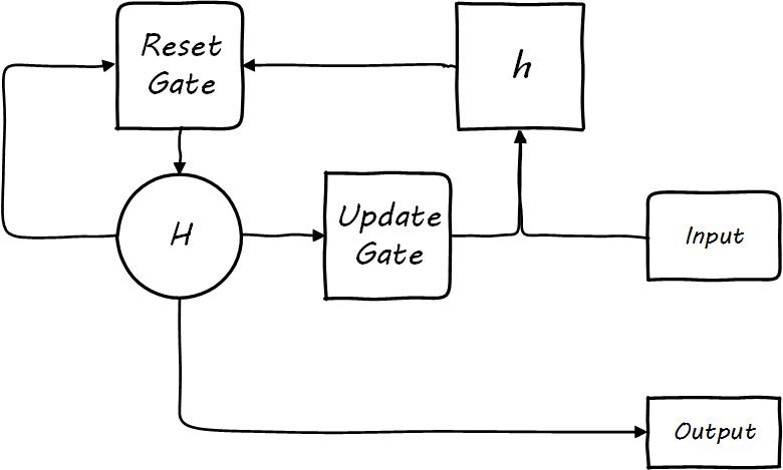
GRU stands for Gated Recurrent Unit, which differs from LSTM in that GRU integrates the forget gate and input gate into a reset gate, with the control values of the forget gate and input gate summing to 1. Therefore, GRU simplifies the parameters on the basis of LSTM, allowing the model to converge faster.
![i0Td8P.jpg]()
Word Embedding
One of the major advantages of deep learning is its ability to automatically learn features. In natural language processing, we specifically use techniques like word2vec to learn the feature representations of words, i.e., word embeddings.
Word vectors, also known as word embeddings, represent words in the form of continuous value vectors (Distributed Representation), rather than using a discrete method (One-hot Representation). In traditional discrete representation, a word is represented by a vector of length V, where V is the size of the dictionary. Only one element in the vector is 1, with the rest being 0, and the position of the 1 indicates the word’s index in the dictionary. Storing words in a discrete manner is inefficient, and the vectors cannot reflect the semantic and grammatical features of words, whereas word vectors can address these issues. Word vectors reduce the dimension of the vector from V to $\sqrt[k] V$ (usually k takes 4), with the values of each element no longer being 1 and 0, but continuous values. Word vectors are a byproduct of supervised learning obtained from the Neural Network Language Model (NNLM) for corpus, and the proposal of this model is based on a linguistic assumption: words with similar semantics have similar contexts, that is, the NNLM model can determine the corresponding central word under the given context.
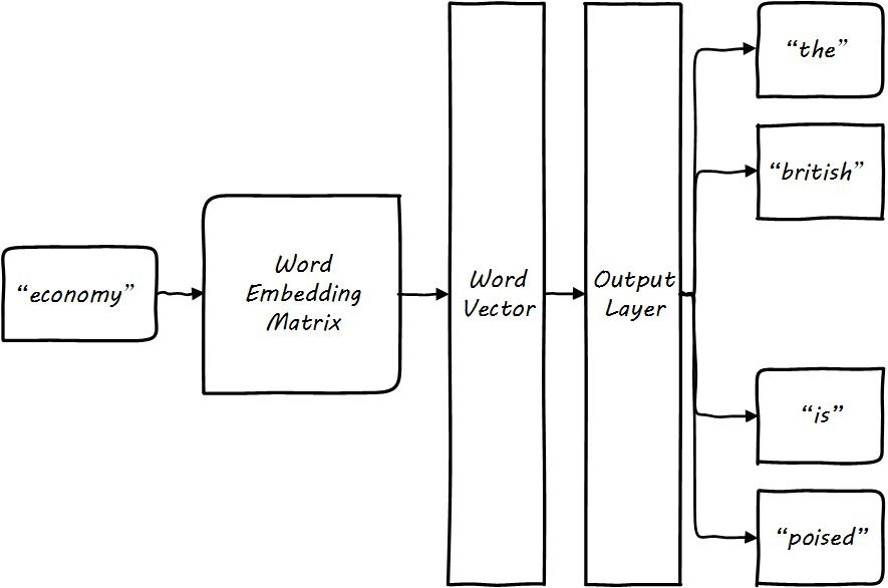
The figure below illustrates the skipgram model in word2vec:
![i0Twgf.jpg]()
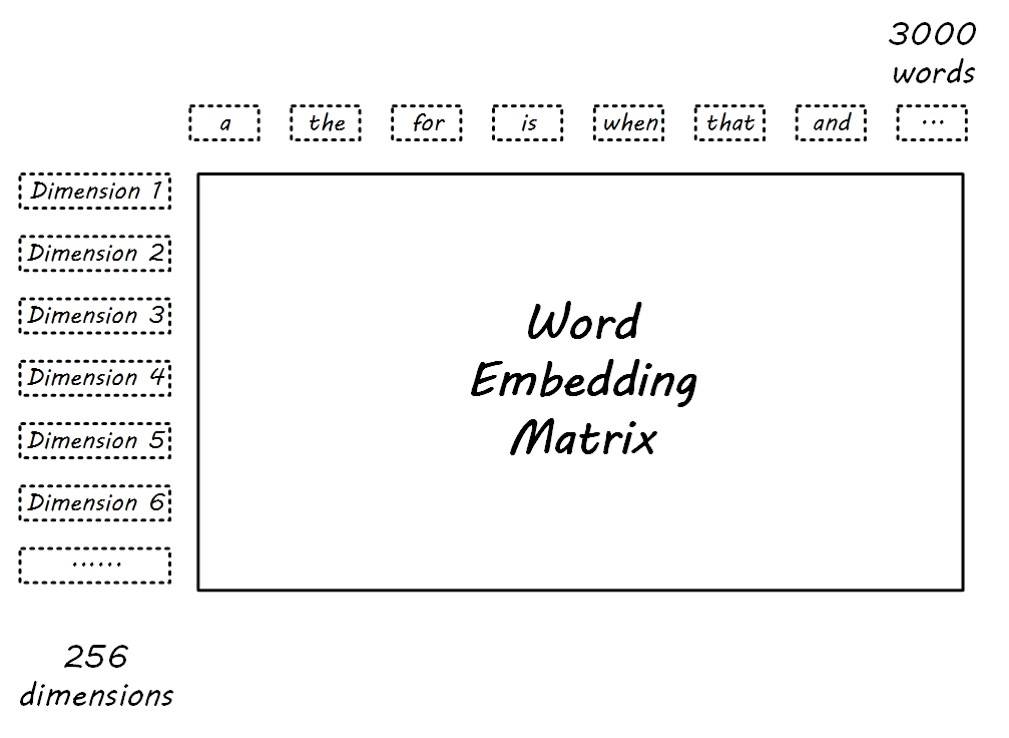
The obtained word embedding matrix is as follows:
![i0T0v8.jpg]()
Mikolov et al. proposed the Word2Vec model based on NNLM, where the input and output for supervised learning are respectively the center word and its context (i.e., the Skip Gram model) or the context and the center word (i.e., the CBOW model). Both methods can effectively train high-quality word vectors, but the CBOW model calculates the center word based on the context, has a fast training speed, and is suitable for training on large corpora; the Skip Gram model can fully utilize the training corpus, and its meaning is “jumping grammar model.” It not only uses adjacent words to form the context of the center word but also uses words that are one word apart as part of the context. As shown in Figure 2-1, the context of a center word in the corpus includes four words. If there are Wtotal words in the corpus, the Skip Gram model can calculate 4 · Wtotal times of loss and perform backpropagation learning, which is four times the number of learning times for the corpus compared to the CBOW model, so this model is suitable for fully utilizing small corpora to train word vectors.
Word2Vec model training is completed, and the weight matrix between the input layer and the hidden layer is the Word Embedding Matrix. Multiplying the vector representing the discrete word with the matrix yields the word vector, which is actually equivalent to looking up the corresponding word vector (Embedding Look Up) in the word embedding matrix. Word vectors can effectively represent the semantic relationships between words, essentially providing a method for machine learning models to extract text information features, facilitating the numerical input of words into the model for processing. Traditional language model training of word vectors incurs too much overhead in the output Softmax layer.
The Word2Vec model employs both Hierarchical Softmax and Noise Contrastive Estimation techniques, significantly accelerating the training process, making it possible to train high-quality word vectors with large-scale corpus in natural language processing.
Attention
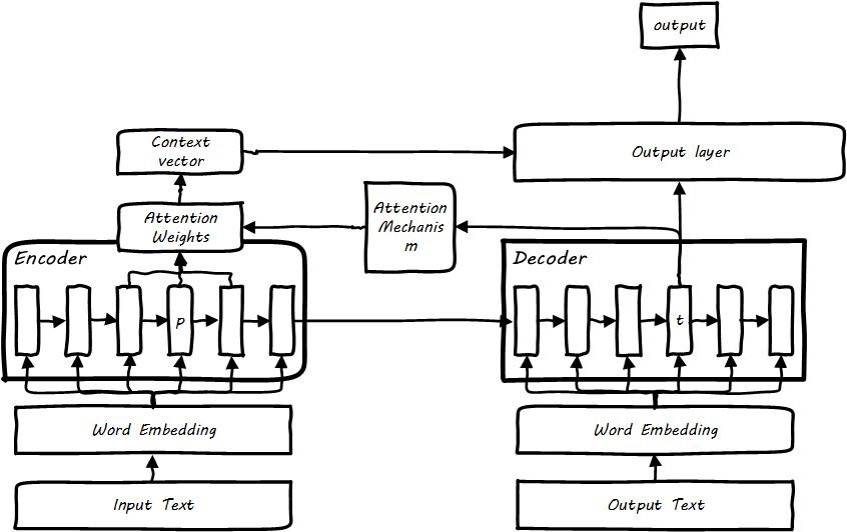
- In NLP tasks, the attention mechanism was first applied to machine translation, where a weight matrix is introduced to represent the contribution degree of each element in the encoder sequence to each word generated by the decoder. In practical implementation, the attention mechanism generates an attention weight, which performs attention-weighted generation of intermediate representations for the hidden layer states of various encoder elements, rather than simply using the hidden layer state of the last element. The simplest attention is the decoder’s attention to the encoder, which is divided into global and local attention. Global attention generates attention weights for the entire encoder sequence, while local attention first trains an attention alignment position and then takes a window around this position, weighting only the sequence within the window, making the attention more precise and focused. One byproduct of the attention mechanism is the alignment between words (Alignment). In machine translation, the alignment relationship can be understood as the degree of association between words and their translations. In automatic summarization, the application of the attention mechanism can effectively alleviate the problem of information loss when long sequences are encoded into intermediate representations by the encoder.
![i0TDKS.jpg]()
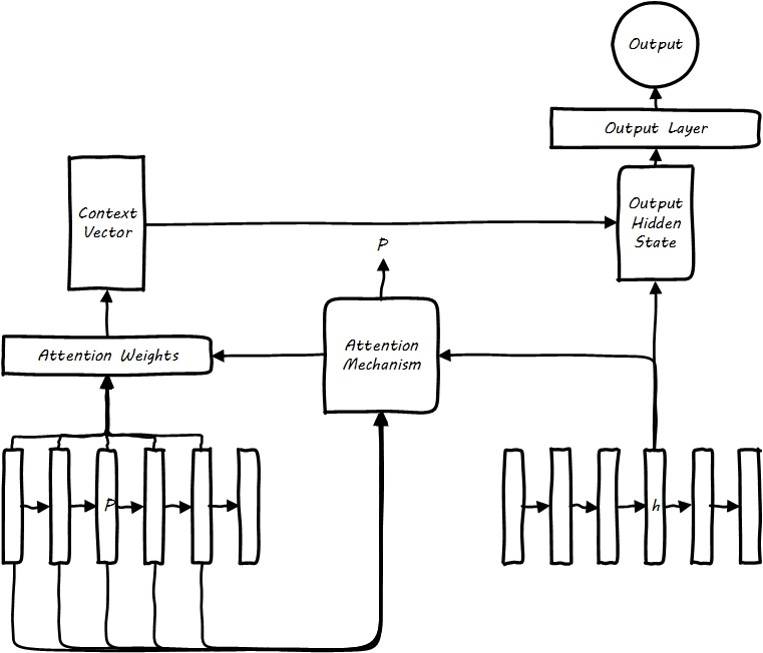
Sequence to sequence
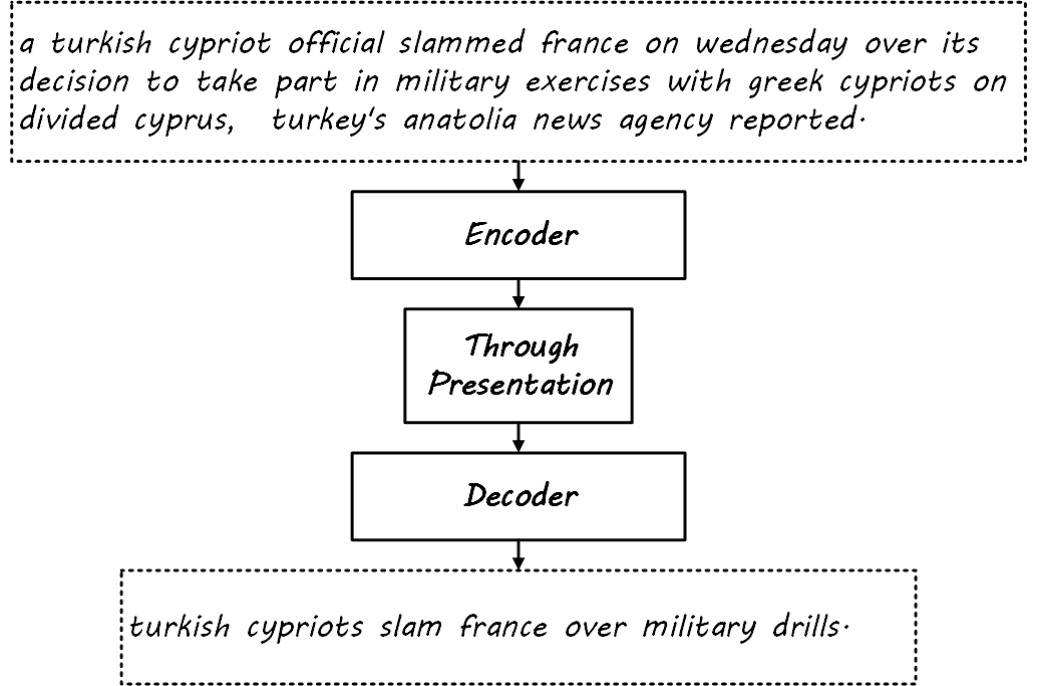
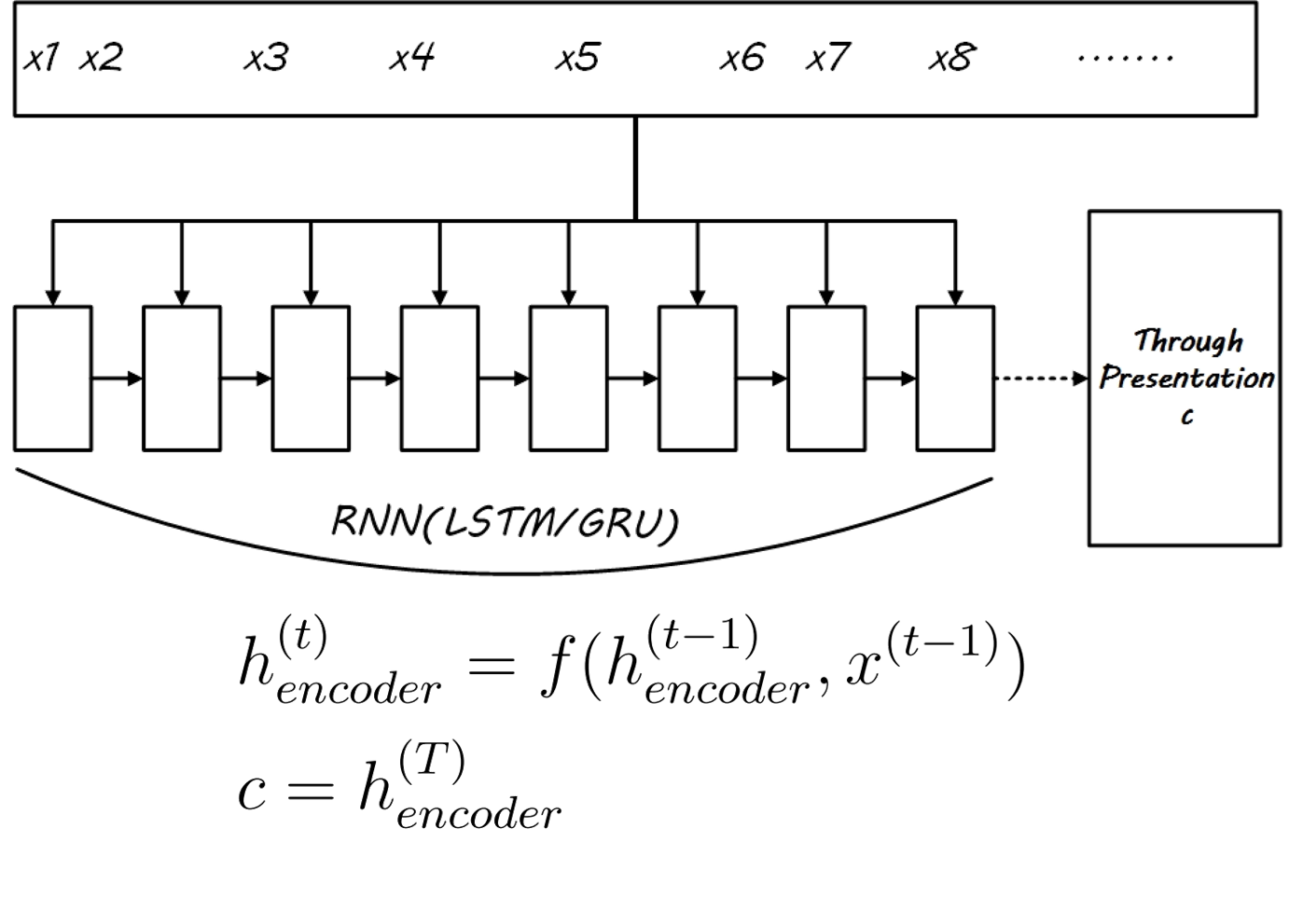
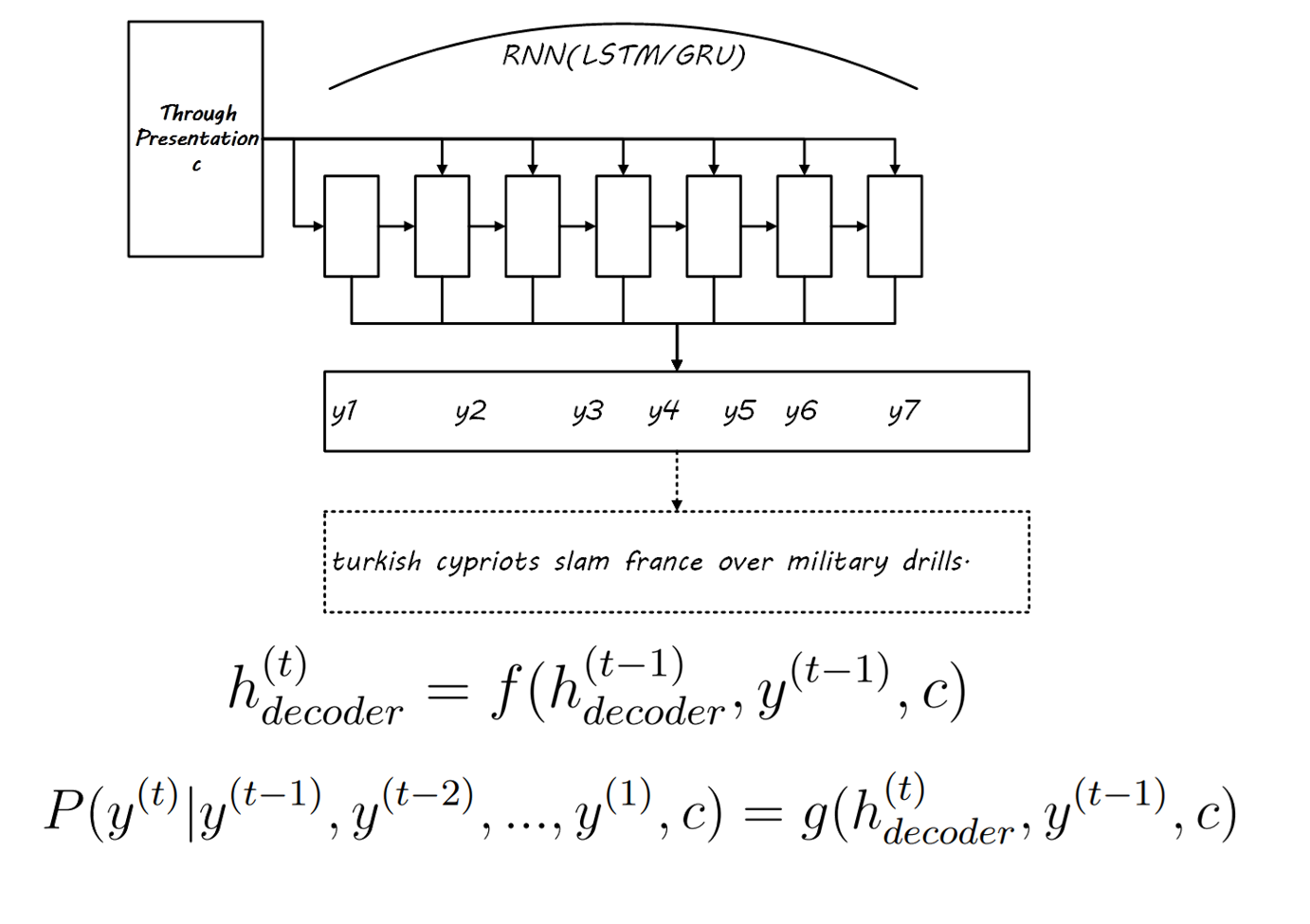
- seq2seq model, which uses an RNN as an encoder to encode the input sequence data into intermediate semantic representation, and then utilizes another RNN as a decoder to obtain the serialized output from the intermediate semantic representation. Generalized sequence-to-sequence and end-to-end learning may not necessarily use RNNs; CNNs or pure attention mechanisms can also be used.
![i0TrDg.jpg]()
- Some personal understanding of sequence-to-sequence models:
- (Information Theory) If the specific implementation forms of the encoder and decoder are not considered, and it is only assumed that the encoder can convert sequence data into an intermediate representation, and the decoder can convert the intermediate representation back into sequence data, then the entire sequence-to-sequence model is equivalent to one round of encoding and decoding of abstract information. Since the dimension of the intermediate representation is much smaller than the total dimension of the encoder, this encoding is lossy. The sequence-to-sequence model aims to make the result of the lossy encoding extract the abstract information from the original text, so the goal of training the network is to let the loss part be the redundant information that is not needed in the abstract. The decoder is equivalent to the inverse process of the encoder, restoring the abstract sequence data from the intermediate representation that contains the abstract information.
- (Study and Application) If the entire model is likened to the human brain, then the encoder’s hidden layer states are equivalent to the knowledge stored within the brain, while the decoder utilizes this knowledge to solve problems, that is, the encoder is a learning process and the decoder is an application process. This analogy can vividly explain various subsequent improvements to the sequence-to-sequence model: learning at time steps corresponds to learning on the real timeline, with earlier learned knowledge being more easily forgotten in the brain (hidden layer information from earlier time steps is severely lost by the final step), and the brain’s capacity being finite (the information storage capacity of the intermediate representation is fixed). Therefore, during learning, we selectively remember and forget information (application of LSTM and GRU), and even highlight key points in the process of memorization (attention mechanism), and can also rely on querying information from the external environment to solve problems without entirely depending on one’s own memory (memory networks).
- (Circular Recurrent Neural Network) From the perspective of data flow and network structure, the entire sequence-to-sequence model can be regarded as a long RNN with certain time steps limited for input and output, as illustrated in Figure 3-1, the model is an RNN with 8 time steps, where the first 5 time steps have no output, and the last 3 time steps pass the output to the next time step to guide state changes. Joint training of the encoder and decoder is equivalent to training this large RNN. This RNN, which only performs input and output at some nodes, is structurally suitable for handling sequence-to-sequence tasks.
Sequence Loss
- The decoder outputs the probability distribution of the dictionary at each step, selecting the word with the highest probability (or performing 束搜索), with the loss being the cross-entropy between the probability at each step and the 01 distribution of the standard word, summed and averaged. In practice, a mask is also applied to address the issue of varying sentence lengths.
Basic Model
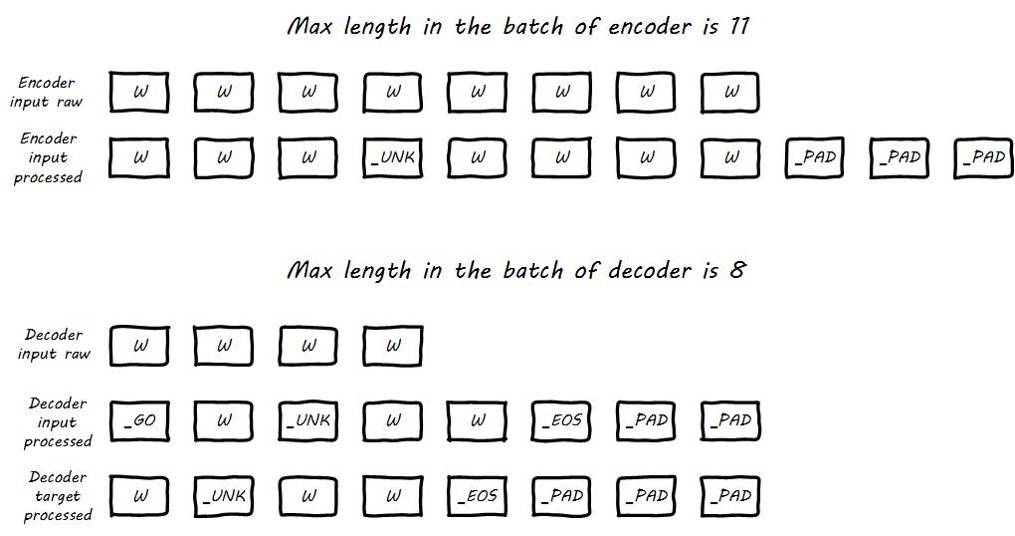
- Preprocessing: For the application of sequence-to-sequence models, certain preprocessing of the data is required, in addition to the commonly used stop word removal and UNK replacement, as well as padding. It also requires the design of start and end symbols for decoding, as follows:
![i0TsbQ.jpg]()
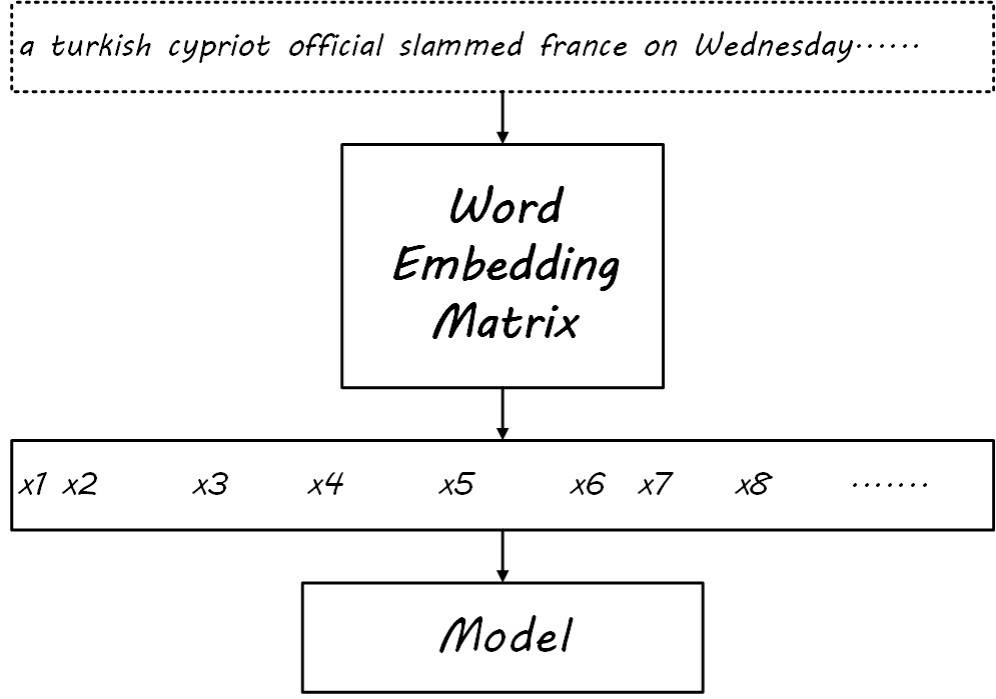
- After training word embeddings, perform an embedding lookup operation on the input to obtain features
![i0T6Ej.jpg]()
- Feature input encoder receives intermediate representation
![i0Tg5n.png]()
- Obtain the intermediate representation and output the abstract (equivalent to label), input the decoder for decoding
![i0TIrF.png]()
- The complete sequence-to-sequence model structure after incorporating the attention mechanism is as follows:
![i0TRCq.jpg]()
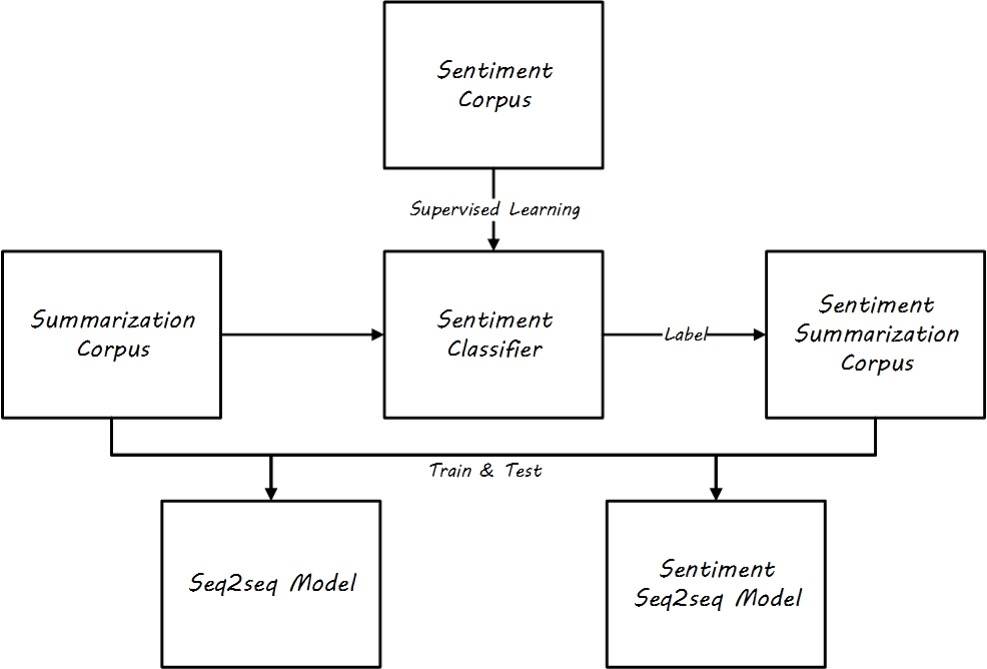
Emotional fusion mechanism
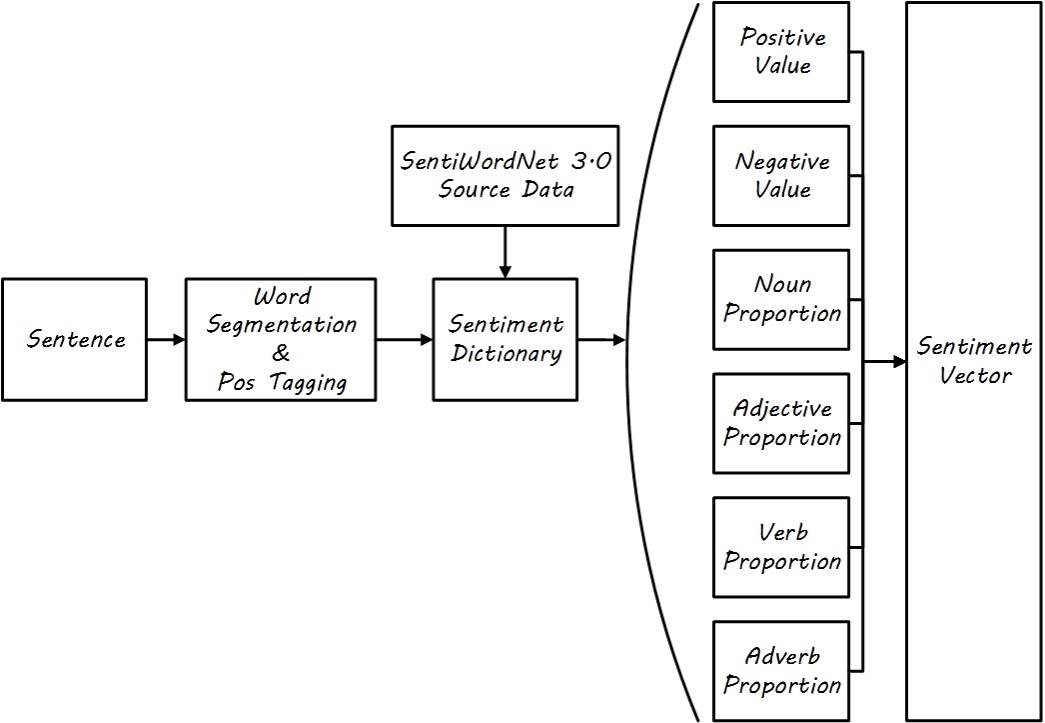
- The emotional mechanism primarily supplements the emotional features of text, manually constructing a six-dimensional feature through the search of an emotional dictionary, and it is hoped in the future to carry out this work by automatically constructing features.
- Firstly, train an emotion classifier, filter the original corpus to form an emotional corpus, and test the model on both the emotional corpus and the general corpus
![i0TW80.jpg]()
- Obtain sentiment vectors (i.e., sentiment features) from a dictionary
![i0Tf2V.jpg]()
- Directly concatenate the emotional features after the intermediate representation, input decoder
![i0ThvT.jpg]()
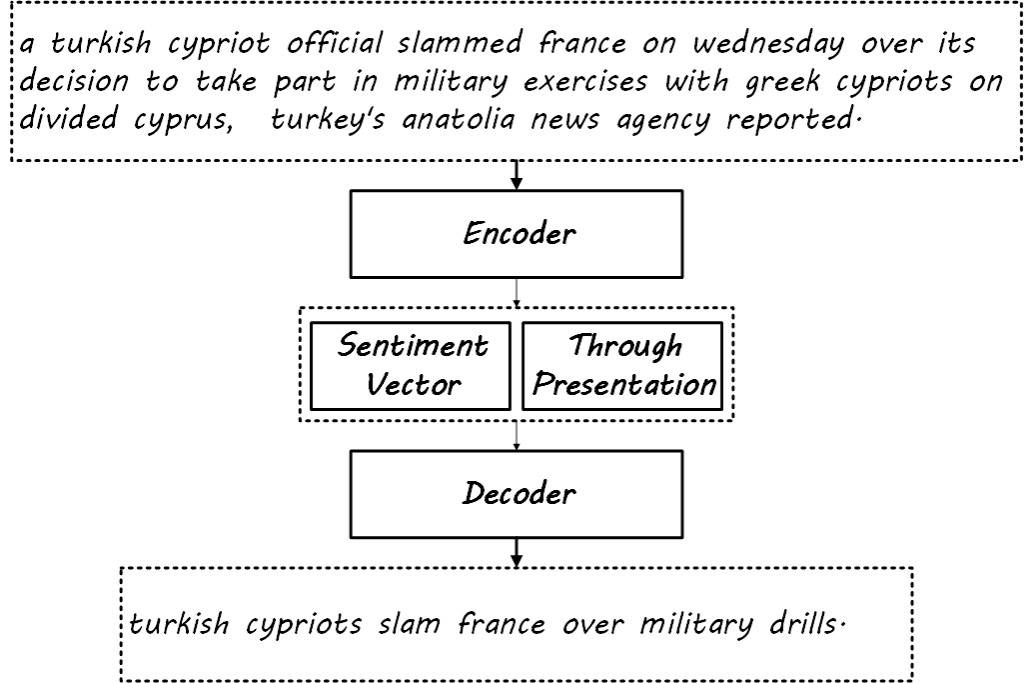
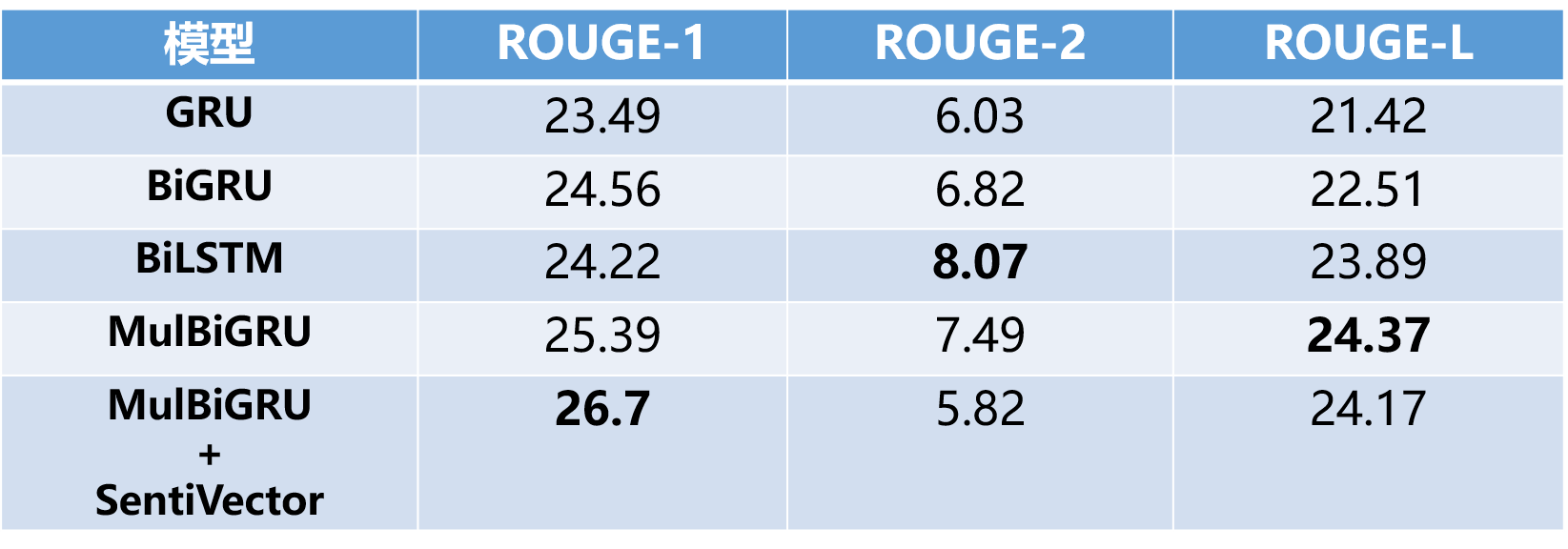
Results
- Results are recorded in the form of ROUGE-F1 values, a comparison of various methods under sentiment corpus
![i0T5KU.png]()
- Comparative Study of Sentiment Fusion Schemes under Common Corpus
![i0Tb5R.png]()
- Emotional classification accuracy, as a reference, the previously trained emotional classifier accuracy was 74%
![i0Tob4.png]()
- Because it is large corpus with small batch training, only ten iterations were trained, and the effect of the test set in each iteration is
![i0T7VJ.png]()
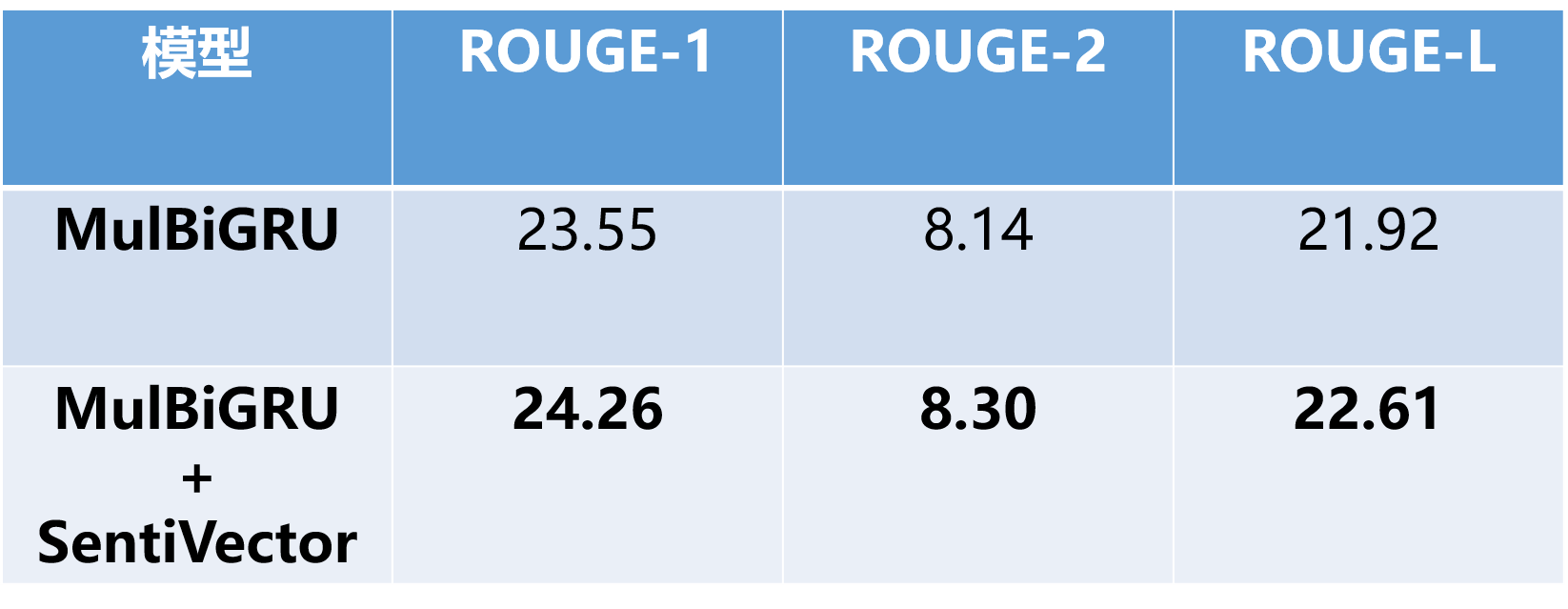


Problem
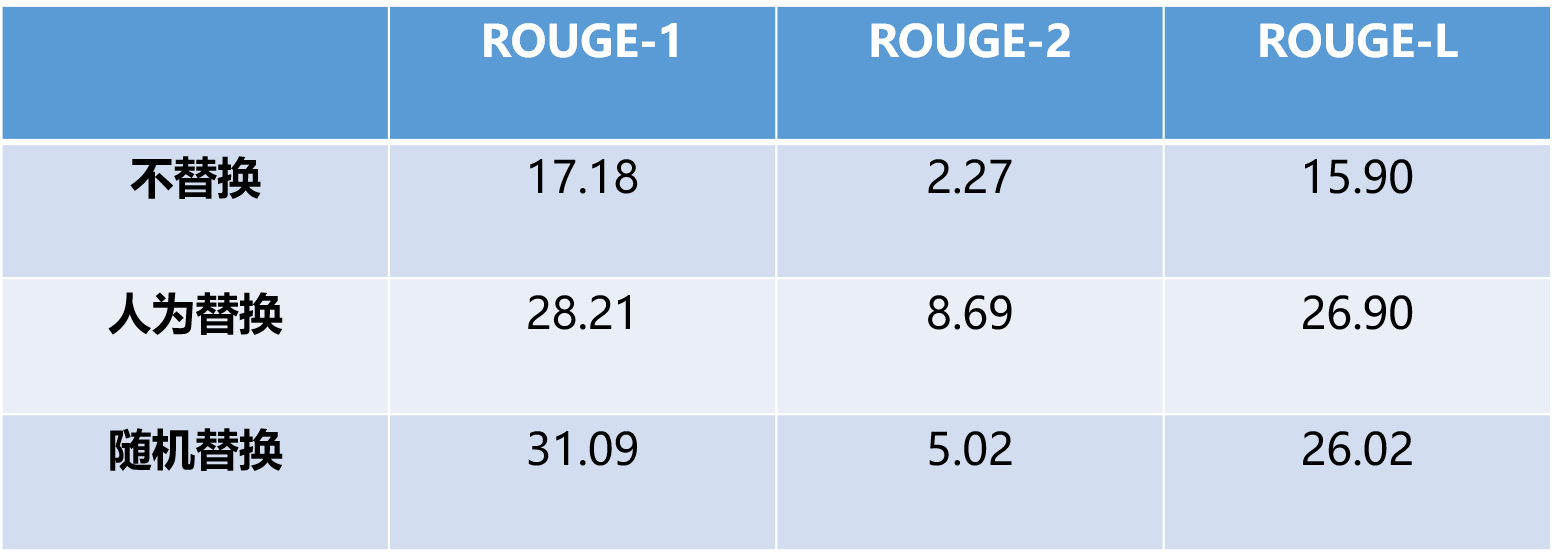
- Problem of unknown replacement: Many literature mentions the use of pointer switch technology to solve the rare words (unk) in generated abstracts, that is, selecting words from the original text to replace the unk in the abstract. However, since ROUGE evaluates the co-occurrence degree of words, even if the words from the original text are replaced, regardless of the position or word accuracy, it may result in an increase in ROUGE value, causing the evaluation results to be overestimated. This paper designs comparative experiments and finds that even random replacements without any mechanism can improve the ROUGE value
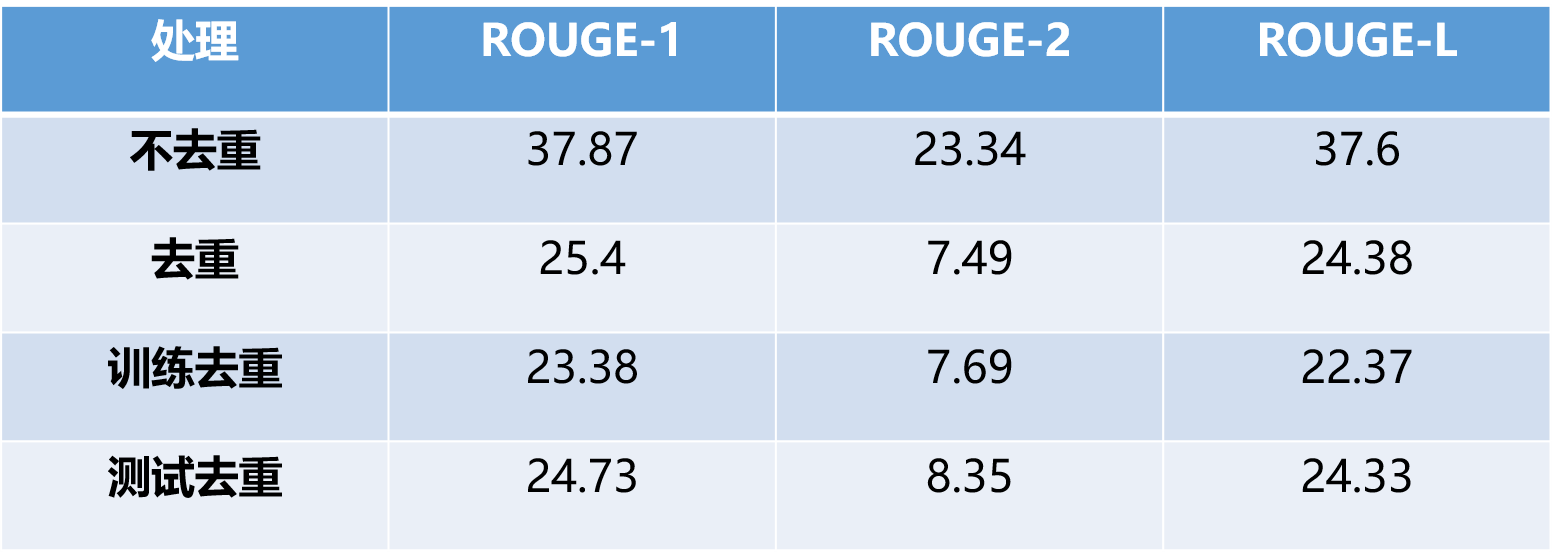
- Corpus Repetition Issue: During the examination of the corpus, we found a large number of short texts that are different but have the same abstracts. The repeated corpus comes from different descriptions of the same event or some functional text, such as “…… Wednesday…… Gold prices rose” and “…… Thursday…… Gold prices rose” both generating the same abstract “Gold prices rose.” The repetition of short abstracts can cause the model to learn some phrases that should not be solidified at the decoding end. Moreover, if there are repeated identical abstracts in the training set and test set, the solidified abstracts can lead to an artificially high accuracy of generated abstracts. For such texts, this paper conducted four groups of experiments:
- Without deduplication: Retain the original text, do not deduplicate, and perform training and testing
- De-duplication: Remove all short texts corresponding to duplicate abstracts from the corpus.
- Training De-duplication: Partial de-duplication, only removing duplicate data from the training corpus, meaning that the well-trained model is not affected by duplicate text.
- Test deduplication: Partial deduplication, only removing the parts of the test set that are duplicated in the training set. Good learning models were affected by duplicate texts, but there was no corresponding data in the test set for the duplicate texts. Under duplicate corpus training, both ROUGE-1 and ROUGE-L exceeded 30, far beyond the normal training models, and after deduplication, they returned to normal levels. The results of the two partial deduplication methods indicate: when training deduplication, models not affected by duplicate corpus did not show significant reactions to the duplicate data in the test set, approximating the normal models with complete deduplication; when testing deduplication, although the model was affected by duplicate corpus, there was no duplicate data in the test set for the model to utilize the learned fixed abstracts, so the results would not be overly high. Moreover, due to learning the pattern of the same abstract corresponding to different short texts, the encoding end actually has a more flexible structure, leading to ROUGE scores higher than those of training deduplication.
![i0TLP1.png]()
Environmental Implementation
- Here is the GitHub address: - Abstract_Summarization_Tensorflow
- Ubuntu 16.04
- Tensorflow 1.6
- CUDA 9.0
- Cudnn 7.1.2
- Gigawords dataset, trained on part of the data, approximately 300,000
- GTX1066, training time 3 to 4 hours
References