Lagrange,KKT,PCA,SVM

Introduction of the Lagrange multiplier method and its extension KKT conditions, as well as their applications in PCA and SVM
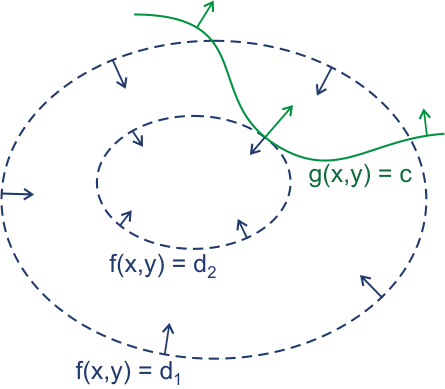
Image from Wikipedia’s illustrative introduction to the Lagrange multiplier method
Lagrange multiplier method
Lagrange multiplier method is a method for finding extrema under constraints, described as
The main idea is to synthesize the constraint conditions and the original function into a single function, convert it into an unconstrained condition, and then find the partial derivatives to obtain the extremum.
It can be seen from the figure that points with equal values of the function f can form blue rings similar to contour lines, with the constraint conditions represented by the green path. The problem can be transformed into finding the point along the green path where the blue ring associated with that point is either closest to the center or farthest from the center (maximum or minimum value).
Clearly, the point of tangency between the green path and the blue loop attains an extremum, at which their gradients (arrows) are parallel, described as
$\lambda$ is the Lagrange multiplier, representing the size multiple of the two parallel gradients in this formula, with the sign indicating that the two gradients are in opposite directions. The Lagrange multiplier is not equal to 0. The Lagrange equation is given by $F(x,y)=\nabla \Big[f \left(x, y \right) + \lambda \left(g \left(x, y \right) - c \right) \Big]$
Solving the above equation yields a set of $(x,y,\lambda)$ , which are the critical points and the Lagrange multipliers at the points of extremum. At this time, the Lagrange equations $F(x,y)=f(x,y)$ hold, because when the extremum is achieved, the constraint condition part must be 0 (we are moving along the constraint condition to find the tangent points, and the tangent points are on the constraint path).
Lagrange coefficients refer to the maximum growth value, $-\frac{\partial \Lambda}{\partial {c_k}} = \lambda_k$
Carroll-Kuhn-Tucker condition
If the constraint conditions are not only equations but also include inequality constraints, it is necessary to generalize the Lagrange multiplier method to the KKT conditions
The problem of optimization with inequality constraints is described as
Lagrange function is
KKT conditions are given by:
PCA
PCA stands for Principal Component Analysis, which optimizes the original dimensions of the data to form a set of new dimensions. These new dimensions are linear combinations of the original dimensions and are mutually independent. They are sorted by importance, with one dimension being understood as a column in a data matrix, where each row represents a sample
$x_1,…,x_p$ represents the original p dimensions, and the new dimensions are $\xi _1,….,\xi _p$
New dimensions are linear combinations of the original dimensions, represented as
In order to unify the scales across all new dimensions, the vector length of the coefficients of the linear combination of each new dimension is set to 1, i.e.,
Let A be the feature transformation matrix, composed of the coefficient vectors of the linear combinations of the new dimensions, then it is necessary to solve for an optimal orthogonal transformation A such that the variance of the new dimensions reaches an extremum. An orthogonal transformation ensures that the new dimensions are uncorrelated; the greater the variance, the more distinct the samples are in the new dimensions, which facilitates our data classification.
The problem is then transformed into an optimization problem with constraints, where the constraint is $\alpha _i^T \alpha _i=1$ , and the extremum of $var(\xi _i)$ is to be found, which can be solved using the Lagrange multiplier method
When i=1, we obtain the first new dimension, which is also the most important (with the largest variance), and then set i=2, adding the constraint condition $E[\xi _2 \xi _1-E[\xi _1][\xi _2]]=0$ , that is, the two new dimensions are uncorrelated, and obtain the second new dimension
Sequentially determine p new dimensions
PCA can optimize the original data, identify dimensions with discriminative power, and more importantly, if there are correlations among the dimensions of the original data, PCA can eliminate these correlations. Even if the correlations in the original data are low, if we only take the first k (k < q) new dimensions, we can perform dimensionality reduction with minimal loss of precision, greatly shortening the training time of the data
If we take the first k new dimensions and perform the inverse operation of PCA on them, we can achieve data denoising, because the new dimensions with very low importance generally reflect the random noise in the data. By discarding them and restoring the original data, we achieve the removal of noise
PCA is unsupervised, does not consider the category or label of the samples themselves, and is not necessarily the optimal solution in supervised learning; feature extraction for classification objectives can be achieved using the K-L transform
PCA using Covariance Matrix
- The above method for solving PCA is too complicated; it can be solved through the covariance matrix in practice (because there are efficient matrix eigenvalue decomposition algorithms)
- The optimization objective of PCA is to reselect a set of bases (features) such that the covariance between different features is 0 under the representation of this set of bases, and the variance within the same feature is maximized
- The problem can be restated as, for the data tensor X, zero-centering by feature columns (a total of m features) (simplifying the calculation of covariance), calculate the covariance matrix $C=\frac 1m X^T X$ . It is hoped to find a set of bases P such that the covariance matrix D of the transformed data $Y=PX$ is diagonal, with non-diagonal elements (covariances) equal to 0. If the diagonal elements (variances) are arranged from large to small, then taking the first k rows of the P matrix can reduce the feature dimension from m to k. It is easy to obtain $D=PCP^T$ , and since C is a real symmetric matrix, the problem then transforms into diagonalizing the real symmetric matrix C, and the new set of bases we need are the eigenvector set.
Algorithm:
There are m sets of n-dimensional data arranged into a matrix X with n rows and m columns
Zero-mean normalization of each row of X
Determine the covariance matrix C
Determine the eigenvalues and eigenvectors of the covariance matrix
Arrange the feature vectors according to the size of their eigenvalues from largest to smallest in rows, forming a new basis matrix P
If necessary, take the first k rows of P, and the reduced-dimensional data is $Y=PX$
def PCA(X, dims): m = len(X) mean = np.mean(X, axis=0) X = X - mean C = np.dot(X.T, X) / m Eigen_Value, Eigen_Vector = np.linalg.eig(C) index = np.argsort(Eigen_Value)[-1:-dims - 1:-1] PCA_Vector = Eigen_Vector[index] X_PCA = np.dot(PCA_Vector, X.T) return X_PCA.T
Support Vector Machine
In classification learning, we need to find a separating hyperplane that separates samples of different categories, and the best separating hyperplane is obviously one that is as far away as possible from the samples of each category, i.e., the hyperplane with the best tolerance to local perturbations of the training samples
The hyperplane is described by the equation $w^Tx+b=0$ , where w is the normal vector determining the direction of the hyperplane, and b is the displacement of the hyperplane to the far point
Solving an SVM, i.e., finding a solution that satisfies the constraints
Under the given conditions, to maximize the distance $\frac{2}{||w||}$ between two different support vectors to the hyperplane, which can be rewritten as an optimization problem
Derivation can be found in the other two blog posts: Machine Learning Notes and Statistical Learning Method Notes Handwritten Version
For this optimization problem, its Lagrange equation is
The term $\alpha$ is the Lagrange multiplier, taking the partial derivatives of the equation with respect to w and b, obtaining the dual problem
The above equation satisfies the KKT conditions, and is solved by the SMO algorithm