Paper Reading 1

Opening Work on Attention (Machine Translation)
Luong attention, global and local attention,
Opening Work on Attention (Automatic Text Summarization)
Generative Summary Techniques Collection: LVT, Switching Networks, Hierarchical Attention
Dialogue System, End-to-End Hierarchical RNN
Weibo summary, supplement micropoints
disan, directed transformer, attention mask
Attention Extractor
Generative Summary Based on Reinforcement Learning
w2v, negative sampling
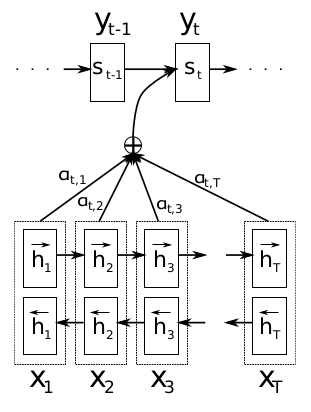
Neural Machine Translation By Jointly Learning To Align And Translate
- Published in 2015.5 (ICLR2015), author Dzmitry Bahdanau.
- Encoder-decoder model, translation task.
- The bidirectional GRU serves as the encoder. The encoding hidden layer vectors are composed of bidirectional connections.
- Different representations are generated for each word.
- The weight is determined by the vector of the hidden layer of all steps and the vector of the hidden layer of the previous decoding step.
- Generate weighted representations of the hidden layer vectors for
all step encoding.
![i0oB79.png]()
Effective Approaches to Attention-based Neural Machine Translation
Published in August 2015, the author (Minh-Thang Luong) used the RNN encoder-decoder model for the translation task.
During the decoding process, the attentional representation and the decoding hidden layer vector corresponding to the target word are concatenated and then passed through an activation function to generate the attention vector:
\[ h_t = tanh(W_c[c_t;h_t]) \]
Afterward, the attention vector is passed through softmax to generate a probability distribution.
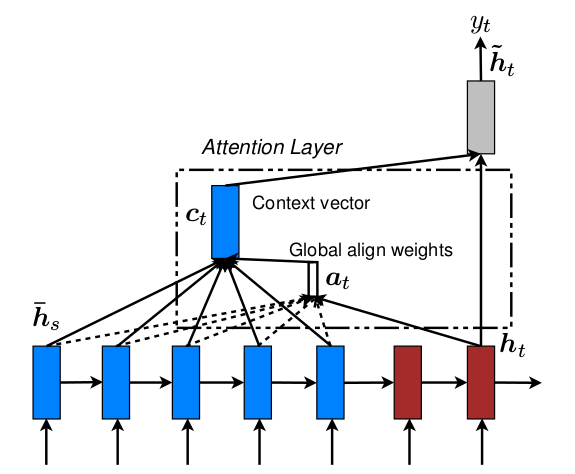
Global Attention
- The article first introduces the global attention model, which is an
attention-weighted generation of representations for all encoding hidden
layer information, leading to an unpredictable length of alignment
vectors (alignment vectors weigh the input information, with the length
being the same as the number of words in the input sentence). The model
proposed by Dzmitry Bahdanau in the aforementioned text is the global
attention model. The global attention model presented in this article is
more generalized: it does not use bidirectional RNN concatenation of
input vectors but employs a regular RNN instead; it calculates weights
directly using the hidden layer vector at the current step, rather than
the previous step, thus avoiding complex computations.
![i0oH9P.png]()
- Afterward, two effective approaches were introduced, namely local attention and input-feeding.
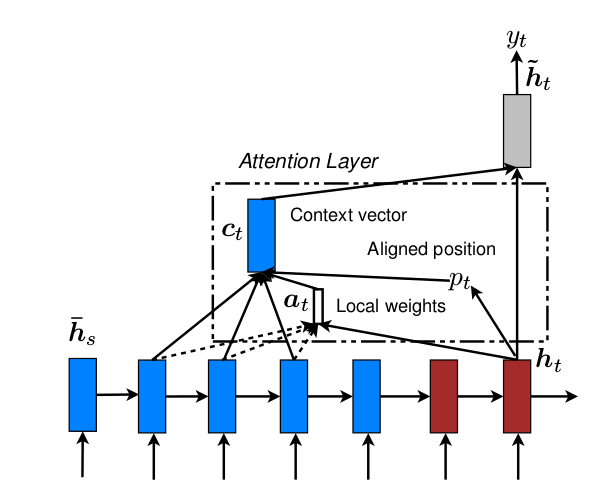
Local Attention
Local Attention: Instead of using all input information, it first generates an alignment position for each output word, then only generates representations with attention weighted to the input information within the window around the alignment position. The article proposes two methods for generating alignment positions:
Monotonic alignment: Simply setting the alignment position of the ith output word to i is obviously not advisable in abstracts.
Predictive Alignment: Training Alignment Positions.
\[ p_t = S \cdots sigmoid(v_p^T tanh(W_ph_t)) \\ \]
\(h_t\) is the hidden layer vector of the t-th generated word, and \(W_p\) and \(v_p\) are the weights that need to be trained. S is the length of the input word, and when multiplied by the sigmoid, it yields the value at any position in the input sentence
To maximize the weight of alignment positions, first generate a Gaussian distribution with alignment positions as the expectation and half-window length as the standard deviation, and then generate weights based on this.
\[ a_t(s) = align(h_t,h_s)exp(-\frac{(s-p_t)^2}{2\sigma ^2}) \]
![i0ost1.png]()
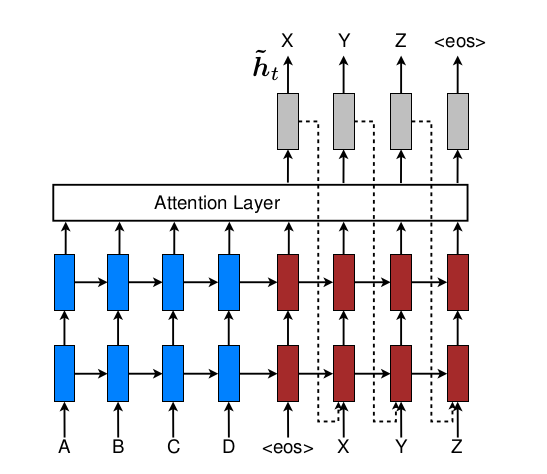
Input-feeding
- Input-feeding: When generating alignment, it still needs to rely on past alignments. The actual implementation involves using the attention vector from the previous step as the feed for the next decoding hidden layer. The benefit is that the model can fully understand the previous alignment decisions and creates a very deep network both horizontally and vertically.
- Experimental results indicate that the use of the prediction
alignment-based local attention model performs the best.
![i0oyfx.png]()
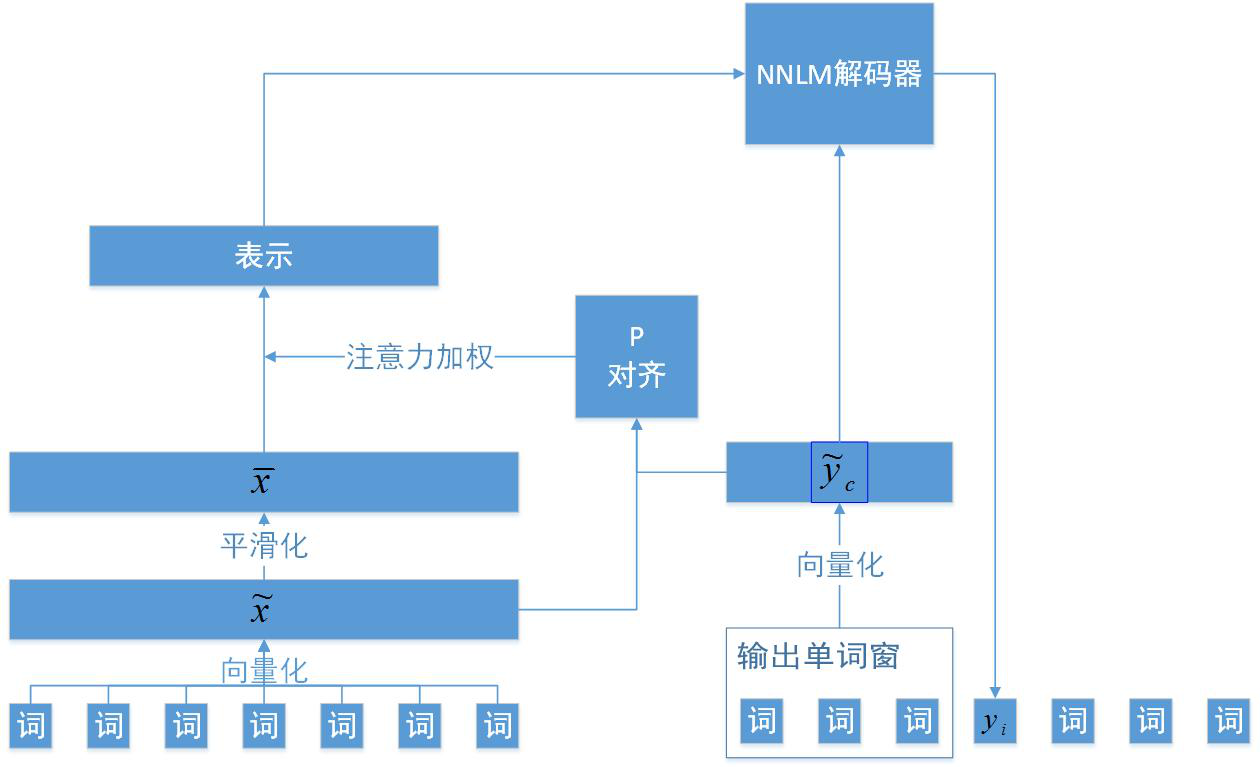
A Neural Attention Model for Abstractive Sentence Summarization
- Published in September 2015, author Alexander M. Rush, Decoder-Encoder Model, Abstract Task.
- Proposed an attention encoder using a standard NNLM decoder.
- Not using RNN, directly using word vectors.
- Utilize all input information and partial output information (yc) to construct attention weights.
- Directly weighting the word vector matrix of the smoothed input sentence rather than the RNN hidden layer vector.
- Model as shown in the figure:
![i0ocp6.png]()
Abstractive Text Summarization using Sequence-to-sequence RNNs and Beyond
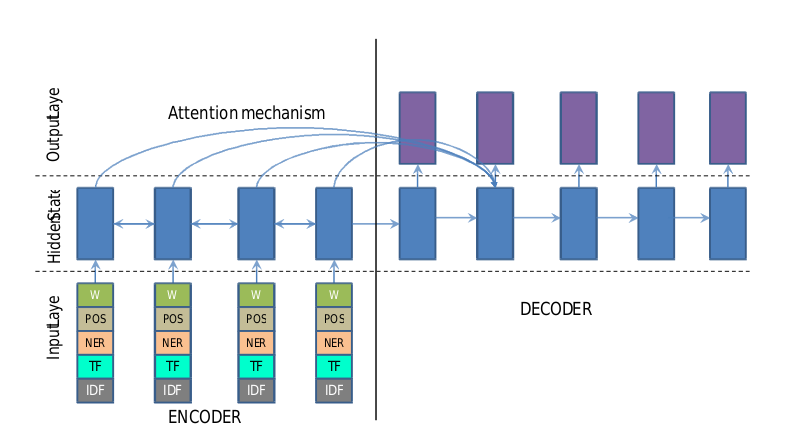
- Published in August 2016, author Ramesh Nallapati. Encoder-decoder model, using RNN, attention, summarization task.
- Based on the machine translation model by Dzmitry Bahdanau (bidirectional GRU encoding, unidirectional GRU decoding) for improvement.
- Improved techniques include LVT (large vocabulary trick), feature-rich encoder, switching generator-pointer, and hierarchical attention.
LVT
- Reduce the size of the softmax layer in the decoder to accelerate computation and convergence. The actual implementation is that the decoder's dictionary is limited to the input text within each mini-batch, and the most frequently occurring words from the decoder dictionary of the previous batch are added to the decoder dictionary of the subsequent batch (until a limit is reached).
Feature-rich Encoder
- Not using simple word vectors that only represent semantic distance,
but constructing new word vectors by integrating various semantic
features such as entity information, and separately forming vectors to
concatenate them.
![i0og1K.png]()
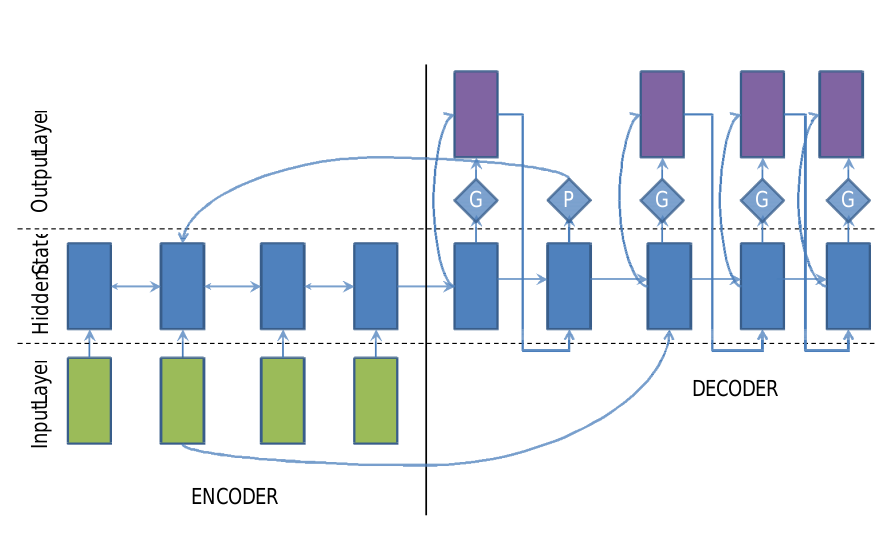
Switching Generator-pointer
- Resolve the issues of rare words and additional words. The
dictionary of the decoder is fixed, and how to deal with words outside
the dictionary in the test text. The proposed solution is to add a
switch to the decoder, where when the switch is on, it uses its own
dictionary to generate the abstract normally, and when the switch is
off, it generates a pointer to a word in the input text, copying it into
the abstract.
![i0oRXD.png]() ) Switching generator/pointer model When the switch
is G, use the traditional method to generate the abstract. When the
switch is P, copy words from the input to the abstract.
) Switching generator/pointer model When the switch
is G, use the traditional method to generate the abstract. When the
switch is P, copy words from the input to the abstract.
 ) Switching generator/pointer model When the switch
is G, use the traditional method to generate the abstract. When the
switch is P, copy words from the input to the abstract.
) Switching generator/pointer model When the switch
is G, use the traditional method to generate the abstract. When the
switch is P, copy words from the input to the abstract.Hierarchical Attention
- Traditional attention refers to focusing on the positions of key
words in sentences, and the hierarchical structure includes the upper
level, that is, the positions of key sentences in the text. Two-layer
bidirectional RNNs are used to capture attention at both the word level
and the sentence level. The attention mechanism runs simultaneously at
both levels, with the attention weights at the word level being
reweighted and adjusted by the attention weights at the sentence level.
![i0ofne.png]()
Recurrent Neural Network Regularization
- This paper introduces how to use dropout in recurrent neural networks to prevent overfitting
- Dropout refers to randomly dropping certain nodes of some hidden layers in deep neural networks during each training, while not dropping nodes during testing but multiplying the node outputs by the dropout probability. This method can effectively solve the time-consuming and prone to overfitting problems in deep learning.
- Two understandings of dropout exist: 1: It forces a neural unit to work together with other randomly selected neural units to achieve good results. It eliminates the weakened joint adaptability between neuron nodes, enhancing generalization ability. 2: It is equivalent to creating some noisy data, increasing the sparsity of the training data, and enhancing the discriminability of features.
- It is not possible to directly discard hidden layer nodes in RNNs because doing so would lose the long-term dependency information required by RNNs, introducing a significant amount of noise that disrupts the learning process.
- The author proposes hierarchical node dropping, that is, using a multi-layer RNN structure, even if a node in one layer at a certain time step is lost, the nodes at the same time step in other layers can still pass through, without disrupting the long-term dependency information of the sequence
- Effect as shown:
![i0ov7j.png]()
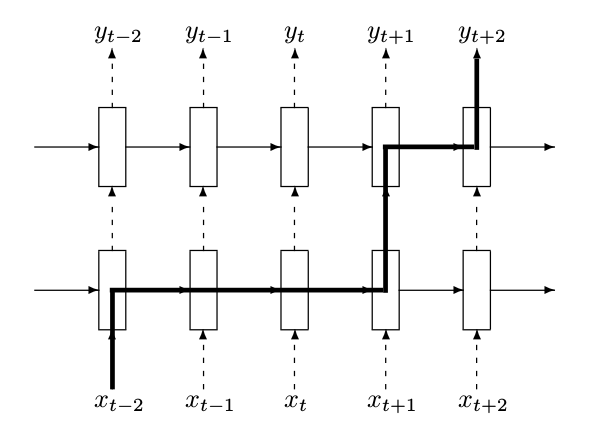
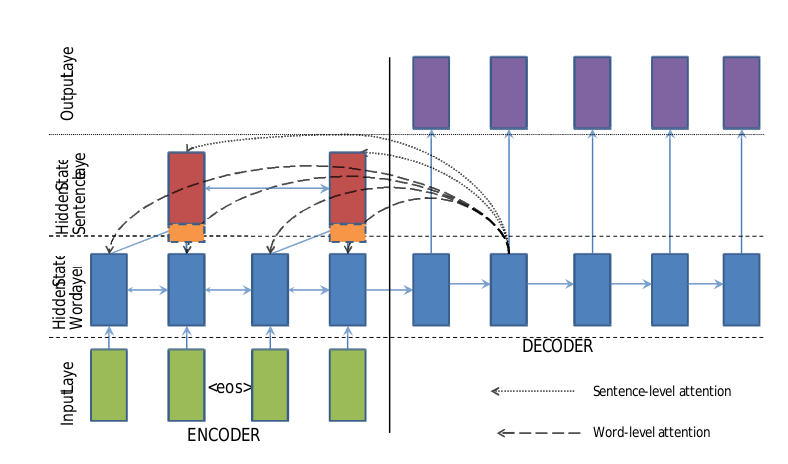
Building End-To-End Dialogue Systems Using Generative Hierarchical Neural Network Models
- This paper introduces the construction of a non-goal-driven natural language dialogue system using a fully data-driven hierarchical RNN end-to-end model.
- Training data consists of triples extracted from movie subtitles, where two speakers complete three expressions in the order of A-B-A.
- The hierarchical structure is not simply an increase in the number of RNN hidden layers, but rather the construction of two RNNs at the word level and sentence level, as shown in the figure below. The three-part dialogue is contained within two word-level RNN end-to-end systems, and the sentences generated in the middle serve as hidden layer vectors for the higher-level sentence-level RNN.
- The article employs the bootstrapping technique, using some pre-trained data as the initial values for the model. For example, word embedding matrices are initially trained in large corpora using w2v. In this article, the entire model is even pre-trained, with the principle being to pre-train the entire model using a two-stage dialogue large corpus of a QA system, with the third segment set to empty. In actual training, word embeddings are pre-trained first to complete the initialization of word embeddings, followed by pre-training the entire model for 4 epochs, and finally, the word embeddings are fixed and the entire model is pre-trained to the optimal value.
- The system infers the third segment from the first two segments of a given three-segment dialogue. Evaluation uses two criteria: word perplexity measures grammatical accuracy, and word classification error measures semantic accuracy.
- The paper finally summarized the reasons for the occurrence of a bad phenomenon. During the output of the maximum a posteriori probability, some usual answers often appear, such as "I don't know" or "I'm sorry." The author believes there are three reasons: 1: Insufficient data. Because dialogue systems have inherent ambiguity and multimodality, large-scale data is needed to train better results. 2: Punctuation and pronouns occupy a large proportion in dialogue, but the system finds it difficult to distinguish the meanings of punctuation and pronouns in different contextual environments. 3: Dialogues are generally very short, so a triple can provide too little information during inference, resulting in insufficient differentiation. Therefore, when designing natural language neural models, it is best to differentiate semantics and grammatical structures. The author also found that if the maximum a posteriori probability is not used and random output is employed, this problem does not occur, and the inferred sentences generally maintain the topic and appear with special words related to the topic.
News Event Summarization Complemented by Micropoints
- This is a paper from Peking University that uses data from Weibo. The work involves constructing some micropoints in Weibo posts with the same theme to supplement the abstracts extracted from traditional news. The experiment proves that this supplemented abstract can achieve better scores in ROUGE.
- The focus of the article's exposition is on extracting micropoints rather than on how to integrate micropoints into the original abstract.
- This team previously proposed two tools: a text clustering model CDW for extracting keywords from news articles; and a Snippet Growth Model for segmenting a blog post into segments (a few sentences each) that possess relatively complete meanings.
- Micropoints generation main steps: filtering blog posts, categorizing blog posts by topic, segmenting blog posts into fragments, selecting some fragments from blog posts of the same topic to form micropoints, and filtering micropoints.
- Screening blog posts considers two indicators: relevance and distinctiveness, which must be related to the original news abstract's theme without being too repetitive to cause redundancy. The author uses CDW to extract keywords from the original news from multiple perspectives, calculates the cosine similarity between the blog posts and these keywords to filter out multiple relevant blog posts. Additionally, the author utilizes Joint Topic Modeling (Joint topic modeling for event summarization across news and social media streams) to calculate the distinctiveness between the blog posts and the abstracts. The harmonic mean of the two calculated indicators is taken as the overall screening indicator.
- Categorize the blog posts by topic: obtain p(topic|tweet) by using LDA with restricted use, then construct a vector v(t) = (p(topic 1 |t), p(topic 2 |t), ..., p(topic n |t)) for each blog post using this conditional probability, and finally use DBSCAN to complete the topic clustering.
- Using the Snippet Growth Model proposed by the team before, the blog posts are divided into snippets, with the general method being to first take a sentence, then calculate the text similarity, distance measure, and influence measure between other sentences and this sentence to decide whether to add other sentences to the snippet where this sentence is located.
- A pile of fragments categorized by topic has been obtained, and the next step is to select several fragments that best represent the topic within a single topic's fragments. The method is to pick the few fragments with the smallest average distance to other fragments of the same topic. Since the sentences are not very long, the author represents a fragment with a bag-of-words, where the bag contains all the words that make up all the sentences in the fragment, represented by word vectors. The distance is measured using KL divergence. If the newly selected fragments are too close to the already selected fragments, they are discarded to ensure that the selected fragments still maintain diversity.
- The obtained fragments will form micropoints, but they need to be filtered before being supplemented into the abstract. The authors propose three indicators: information quantity, popularity, and conciseness. Information quantity refers to the information entropy gain of the abstract after supplementation; the higher the information quantity, the better. Popularity is measured by the number of comments on the original post, with more popular posts being less likely to be extreme. Popularity is preferred to prevent the supplementation of abstracts with extreme or morally incorrect posts. The higher the popularity, the better. Conciseness is described by the ratio of the length of the supplemented part to the length of the original abstract; the smaller the ratio, the more concise the supplementation, and it will not overshadow the original. At this point, the problem is reduced to a discrete optimization problem with constraints under a given conciseness requirement, where each fragment can bring benefits in terms of information quantity and popularity while consuming a certain amount of conciseness. The goal is to select fragments to maximize the benefits, which can be abstracted as a 0-1 knapsack problem and solved using dynamic programming. The authors also set thresholds and use a piecewise function: when popularity exceeds the threshold, the contribution of information gain to the benefit will be greater. This setting is to ensure that the abstract will not be supplemented with fragments where one side has a very high popularity or information gain while the other side is almost non-existent.
DiSAN: Directional Self-Attention Network for RNN/CNN-Free Language Understanding
- Update, the author later released fast disan, it seems to have modified the calculation of attention, details to be supplemented
- The author proposes a directed self-attention network that can also perform the encoding task in NLP problems without relying on RNN or CNN structures.
- The authors believe that among the existing encoders, RNN can capture the sequence information well, but it is slow. The use of a pure attention mechanism (just like the attention weighting of a sequence of word vectors without using RNN in A Neural Attention Model for Abstractive Sentence Summarization) can be used to speed up the operation using existing distributed or parallel computing frameworks, but the sequence information is lost. Therefore, the authors propose a pure attention encoder structure that can capture sequential order information, which combines the advantages of both.
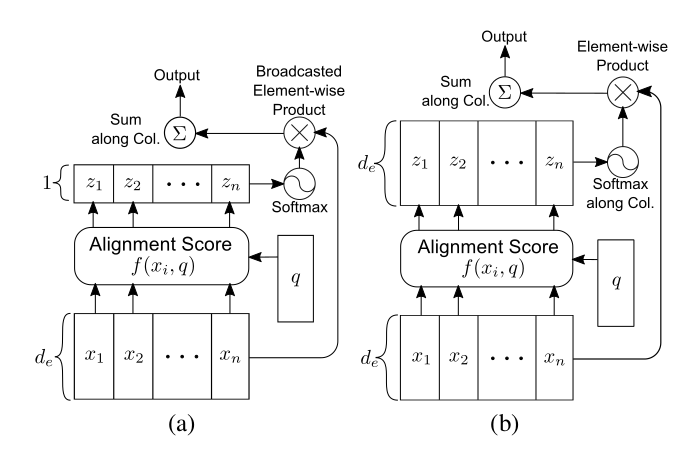
- The author first proposed three attention concepts: multi-dimensional attention, self-attention, and directed attention.
- Traditional attention assigns weights to each word in a sentence,
with scalar values. In multi-dimensional attention, the weights are
vectors, with dimensions matching those of the word vectors. The
rationale for using multi-dimensional attention is that it applies
attention weighting to each feature of every word. Word vectors
inherently have polysemy, and the traditional attention mechanism that
weights the entire word vector cannot effectively distinguish between
the same word in different contextual environments. Multi-dimensional
attention applies weighting to each component of the word vector,
allowing for more attention weight to be given to features that can
represent the current contextual environment. My understanding is that
applying attention weighting to the components of the word vector is
equivalent to having slightly different representations of the same word
in different contextual environments, which can be used for distinction.
The figure below illustrates the difference between traditional
attention and multi-dimensional attention.
![i0ojBQ.png]() On
the right is multi-dimensional attention, where the attention weights
have become vectors, matching the dimensionality of the input word
vectors.
On
the right is multi-dimensional attention, where the attention weights
have become vectors, matching the dimensionality of the input word
vectors. - The general attention weights are generated with encoding input and a decoding output as parameters, and the weights are related to the current output. Self-attention is unrelated to the decoding end, either replacing the decoding output with each word in the sentence or with the entire input sentence. The former, combined with multi-dimensions, forms token2token attention, while the latter, combined with multi-dimensions, forms source2token.
- Directed attention involves adding a mask matrix when generating
token2token attention, with matrix elements being 0 or negative
infinity. The matrix can be upper triangular or lower triangular,
representing masks for two directions, for example, from i to j is 0,
and from j to i is negative infinity. This gives the attention between
words in token2token a direction; attention in the incorrect direction
is reduced to 0 after softmax, while attention in the correct direction
is unaffected. The mask matrix also has a third type, a non-diagonal
matrix, where the diagonal values are negative infinity. This way, a
word in token2token does not generate attention for itself. Directed
attention is as shown in the figure:
![i0ozAs.png]()
- The final architecture of the self-attentional network utilizes the above three types of attention. Firstly, the combination of the upper and lower triangular masks with multi-dimensional token2token generates two self-attention vectors, similar to BLSTM, and then these vectors are connected, passing through a multi-dimensional source2token to produce the final encoded output. The authors tested that this encoding can achieve the best level in natural language prediction and sentiment analysis tasks and can also be used as part of other models for other tasks.
 On
the right is multi-dimensional attention, where the attention weights
have become vectors, matching the dimensionality of the input word
vectors.
On
the right is multi-dimensional attention, where the attention weights
have become vectors, matching the dimensionality of the input word
vectors.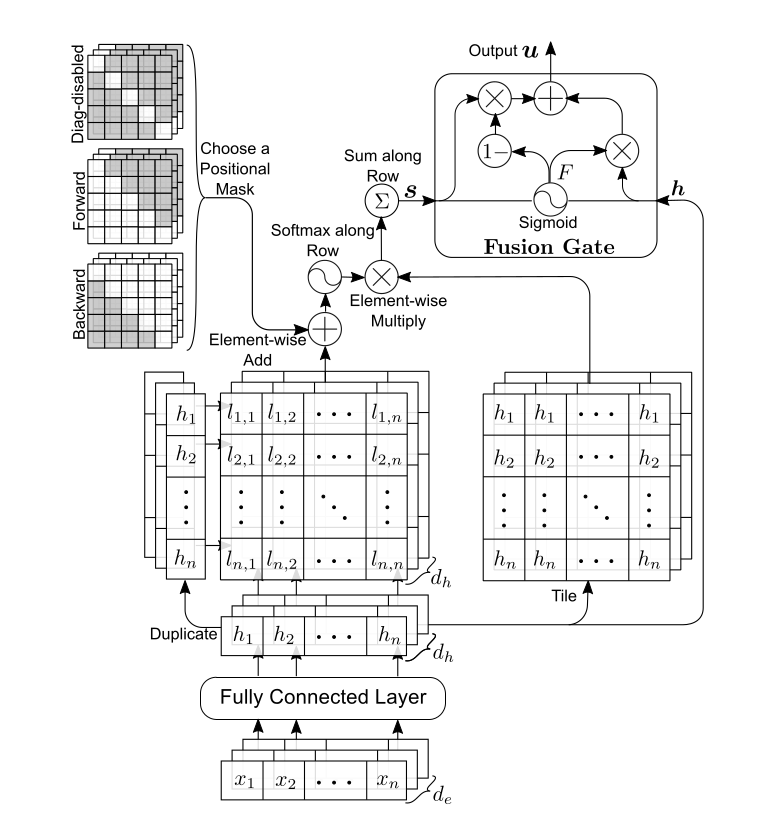
Neural Summarization by Extracting Sentences and Words
- This paper employs a fully data-driven model to accomplish extractive summarization. The model structure consists of a hierarchical text encoder and an attention-based extractor.
- The difference from the generative attention mechanism summarization lies in: using CNN instead of w2v to construct word embeddings; attention is used to directly extract words rather than to weight and generate intermediate representations.
- Because this paper uses data-driven extractive summarization, it requires a large amount of extractive summarization training data. Such training data is scarce, so the authors propose a method for generating extractive training data at the word and sentence levels: For sentence extraction, the authors' approach is to convert generative summarization into extractive summarization. First, obtain generative summarization, then compare each sentence in the original text with the generative summarization to decide whether it should be extracted. The comparison criteria include the position of the sentence in the document, the overlap of unigram and bigram grammar, the number of named entities appearing, etc.; for word extraction, the same approach is used to compare the degree of semantic overlap between the generative summarization and the words in the original text to decide whether the word should be extracted. For words that appear in the generative summarization but not in the original text, the authors' solution is to substitute with words that have a similar embedding distance to the original text words to form the training data.
- During encoding, use CNN to form word embeddings, represent sentences as sequences of word embeddings, and then use RNN to encode at the document level (with one sentence as an input at each time step).
- When performing sentence extraction, unlike generative models, the dependency of the extracted RNN output is on the previous extracted sentence multiplied by a confidence coefficient, which represents the probability of the previous sentence being extracted.
- As with generative models, there are differences between train and infer, and the issues that arise during the initial infer phase will accumulate and grow over time. To address this problem, the authors employ a "curriculum learning strategy": initially setting the confidence level to 1 when the training cannot accurately predict, and then gradually restoring the confidence level to the value trained out as the training progresses.
- Compared to sentence extraction, word extraction is more closely aligned with generative algorithms and can be regarded as a generative summary at the word level under dictionary constraints.
- Extractions-based abstracts have advantages in handling sparse vocabulary and named entities, allowing the model to check the context and relative position of these words or entities in the sentence to reduce attention weights and minimize the impact of such words.
- The problem to be addressed in the sampling method is to determine the number of samples. The authors select the three sentences with the highest sampling confidence as the abstract. Another issue is that the dictionary for each batch is generally different. The authors adopt a negative sampling solution.
A DEEP REINFORCED MODEL FOR ABSTRACTIVE SUMMARIZATION
Using reinforcement learning to optimize the current end-to-end generative summarization model
![i0TicT.png]()
Addressing the issues of long text summarization and repetitive phrase generation
Enhanced learning requires external feedback for the model, here the authors use 人工 evaluation of the generated abstracts and provide feedback to the model, enabling it to produce more readable abstracts
The improvement of the model mainly focuses on two points: internal attention was added to both the encoding and decoding ends, where the encoding end is a previously proposed method, and this paper mainly introduces the internal attention mechanism at the decoding end; a new objective function is proposed, which combines cross-entropy loss with rewards from reinforcement learning
The inner attention at both ends of encoding and decoding addresses the repetition phrase issue from two aspects, as the repetition problem is more severe in long text summarization compared to short text.
The addition of inner attention at the encoding end is based on the belief that repetition arises from the uneven distribution of attention over the input long text across different decoding time steps, which does not fully utilize the long text. The distribution of attention may be similar across different decoding time steps, leading to the generation of repetitive segments. Therefore, the authors penalize input positions that have already received high attention weights in the model, ensuring that all parts of the input text are fully utilized. The method of introducing the penalty is to divide the attention weight of a certain encoding input position at a new decoding time step by the sum of attention weights from all previous time steps, so that if a large attention weight was produced in the past, the newly generated attention weight will be smaller.
The addition of internal attention at the decoding end is based on the belief that repetition also originates from the repetition of the hidden states within the decoding end itself. The authors argue that the information relied upon during decoding should not only include the hidden layer state of the decoding end from the previous time step, but also the hidden layer states from all past time steps, with attentional weighting given. Therefore, a similar internal attention mechanism and penalty mechanism are introduced at the decoding end.
In this end-to-end model, attention is not a means of communication between the encoding and decoding ends, but is independent at both ends, depending only on the state before and the current state of the encoding/decoding ends, thus it is intrinsic attention (self-attention).
In constructing the end-to-end model, the authors also adopted some other techniques proposed by predecessors, such as using copy pointers and switches to solve the sparse word problem, encoding and decoding the shared word embedding matrix, and also particularly proposed a small trick: based on observation, repeated three-word phrases generally do not appear in abstracts, so in the 束 search at the decoding end, if a repeated three-word phrase appears, it should be pruned.
Afterward, the author analyzed two reasons why static supervised learning often fails to achieve ideal results in abstract evaluation criteria: one is exposure bias, where the model is exposed to the correct output (ground truth) during training but lacks a correct output for correction during inference, thus if a word is misinterpreted during inference, the error accumulates increasingly; the other is that the generation of abstracts itself is not static, lacks a standard answer, and good abstracts have many possibilities (these possibilities are generally considered in abstract evaluation criteria), but the static learning method using the maximum likelihood objective function kills these possibilities.
Therefore, the authors introduced policy learning, a strategy search reinforcement learning method, for the abstracting task beyond supervised learning. In reinforcement learning, the model is not aimed at generating outputs most similar to the labels, but at maximizing a certain indicator. Here, the authors refer to a reinforcement learning algorithm from the image annotation task: the self-critical policy gradient training algorithm:
\[ L_{rl} = (r(y)-r(y^s))\sum _{t=1}^n log p(y_t^s | y_1^s,...,y_{t-1}^s,x) \]
r is the 人工 evaluation reward function; the parameters of the two r functions are: the former is the baseline sentence obtained by maximizing the output probability, and the latter is the sentence obtained by sampling from the conditional probability distribution of each step; the goal is to minimize this L objective function. If the manually awarded sentence obtained from the sampling has more rewards than the baseline sentence, then this minimization of the objective function is equivalent to maximizing the conditional probability of the sampled sentence (after the calculation of the first two r functions, it becomes a negative sign)
Afterward, the author combines the two objective functions of supervised learning and reinforcement learning:
Distributed Representations of Words and Phrases and their Compositionality
Described the negative sampling version of w2v.
Training with phrases as the basic unit rather than words can better represent some idiomatic phrases.
Using NCE (Noise Contrast Estimation) instead of hierarchical softmax, NCE approximates the maximization of the logarithmic probability of softmax, as in W2V, we only care about learning good representations, therefore, a simplified version of NCE, negative sampling, is used to replace the conditional probability of the output with the following formula:
\[ p(w_O | w_I) = \frac {exp(v_{w_O}^T v_{w_I})}{\sum _{w=1}^W exp(v_{w_O}^T v_{w_I})} \]
$$ log \sigma (v_{w_O}^T v_{w_I}) + \sum_{i=1}^k E[w_i \sim P_n(w)] [log \sigma (v_{w_O}^T v_{w_I})]
Each time, only the target label and k noise labels (i.e., non-target labels) are activated in the softmax output layer, i.e., for each word, there are k+1 samples, 1 positive sample, and k negative samples obtained by sampling, which are then classified using logistic regression. The above expression is the likelihood function of logistic regression, where Pn is the probability distribution of the noise.
Downsample common words because the vector representation of common words is easy to stabilize; even after several million training iterations, there is little change, so each word's training is skipped with a certain probability:
The skip-gram model trained in this way has good additive semantic compositionality (the component-wise addition of two vectors), i.e., Russia + river is close to the Volga River, because the vectors are logarithmically related to the probabilities of the output layer, and the sum of two vectors is related to the product of two contexts, which is equivalent to logical AND: high probability multiplied by high probability results in high probability, and the rest is low probability. Therefore, it has this simple arithmetic semantic compositionality.

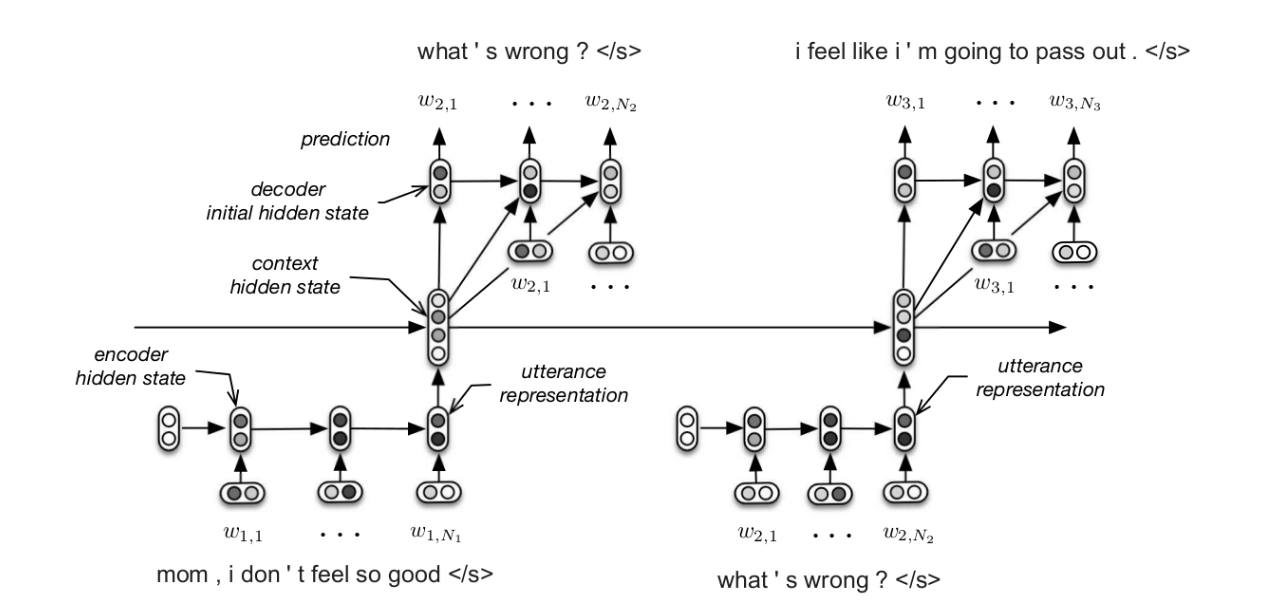 三段式对话包含在两个词水平RNN端到端系统中
中间生成的句表示又作为更高层次即句水平RNN的隐藏层向量
三段式对话包含在两个词水平RNN端到端系统中
中间生成的句表示又作为更高层次即句水平RNN的隐藏层向量