Notes for NLP with Graph-Structured Representations

Read Dr. Bang Liu’s paper Natural Language Processing and Text Mining with Graph-Structured Representations from the University of Alberta and take some notes.
Natural Language Processing Based on Graph Structural Representation
- The paper mainly encompasses work in four primary directions:
- Event Extraction, Story Generation
- Semantic Matching
- Recommendation
- Reading Comprehension
Related Fields and Methodology
- Graph construction related work in NLP
- Words as nodes
- Syntactic information as edges: Learning substructures of document semantic graphs for document summarization
- Co-occurrence information as edges: Graph-of-word and tw-idf: new approach to ad hoc ir; Shortest-path graph kernels for document similarity; Directional skip-gram: Explicitly distinguishing left and right context for word embeddings;
- Sentences, paragraphs, documents as nodes
- Word co-occurrence, position as edges: Textrank: Bringing order into texts;
- Similarity as edges: Evaluating text coherence based on semantic similarity graph;
- Links as edges: Pagerank
- Hybrid: Graph methods for multilingual framenets
- Methodology
- Clarify input and output, determine semantic granularity, graph construction (define nodes and edges, extract node and edge features), graph representation reconstruction, conduct experiments
- The key to introducing graphs in NLP is introducing structural and relational information.
- Graph representation reconstruction problems, such as
- Semantic matching: Tree or graph matching
- Event discovery: Community detection
- Phrase mining: Node classification and ranking
- Ontology creation: Relationship identification
- Question generation: Node selection
![GG2kes.png]()

Event Extraction and Story Generation
Related Work
- Text Clustering
- Similarity-based methods requiring specified cluster count
- Density-based methods less suitable for high-dimensional sparse text spaces
- Non-negative matrix factorization methods (spectral clustering)
- Probabilistic models, such as PLSA, LDA, GMM
- Story Structure Generation
- Continuously categorizing new events into existing clusters
- Generating story summaries for time-sequential events; traditional summarization methods cannot continuously generate; currently using Bayesian model methods, but Gibbs sampling is too time-consuming
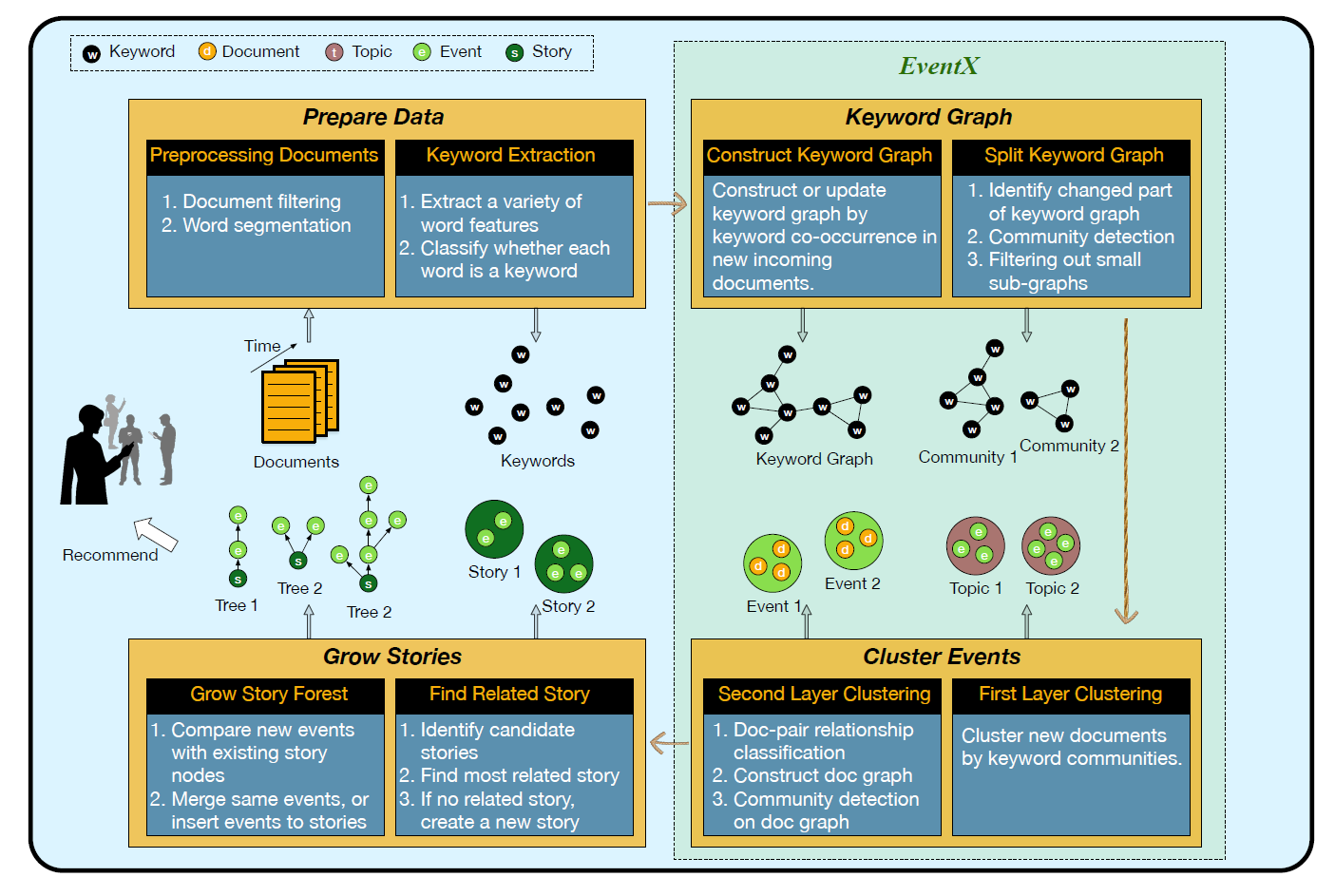
- Authors proposed EventX method, constructed Story Forest system, related to above two approaches, focusing on open-domain news document event extraction
Story Forest: Extracting Events and Telling Stories from Breaking News(TKDD)
- Story Forest: Extracting events and generating stories from news
- Definition: A topic is equivalent to a story forest, containing multiple story trees; each story tree’s nodes are events, with events as the minimal processing unit, essentially multiple news documents about a single event. The system assumes each article reports only one event
- Overall Architecture:
![GrQJun.png]()
Primary focus on EventX’s event clustering method, a two-layer clustering
Construct a keyword co-occurrence graph, with keywords as nodes, considering two points for edge creation: intra-document relevance (co-occurrence exceeding threshold in same document); corpus relevance (conditional probability exceeding threshold):
- Perform community detection on this keyword graph, clustering keywords, with each cluster considered to describe the same topic. Each topic is a collection of keywords, equivalent to a document (bag of words)
- Calculate similarity between each document and each topic, assigning documents to the topic with maximum similarity, completing the first layer: document clustering by theme
- After separating documents by topic, further subdivide events within each topic, the second clustering layer. Event cluster sizes are typically severely imbalanced; authors propose a supervised learning-guided clustering method
- Now viewing each document as a node, aiming to create edges between documents discussing the same event. Unable to manually design rules, they used supervised learning, training an SVM to judge whether documents describe the same event. After obtaining the document graph, perform community detection to complete the second clustering layer
Semantic Matching
Related Work
- Document-level semantic matching, related work: Text matching, document graph structural representation
- Text Matching
- Interaction placed last, first extracting embeddings via Siamese networks, then scoring matched embedding pairs
- Early interaction, first extracting pair-wise interactions as features, then aggregating interactions through neural networks, finally scoring
- Document Graph Structural Representation
- Word graph: Constructing graphs via syntactic parsing to obtain SPO triples, potentially extended via Wordnet; window-based methods with nodes representing unique terms and directed edges representing co-occurrences within a fixed-size sliding window; using dependency relationships as edges; hyperlink-based graph construction
- Text graph: Nodes are sentences, paragraphs, documents; edges established based on word-level similarity, position, co-occurrence
- Concept graph: Based on knowledge graphs, extracting document entities as nodes (e.g., DBpedia), then performing DFS within 2 hops to find outgoing relations and entities; or based on Wordnet, Verbnet, finding semantic roles, constructing edges with semantic/syntactic relations
- Hybrid graph: Heterogeneous graph with multiple node and edge types, including lexical, tokens, syntactic structure nodes, part of speech nodes
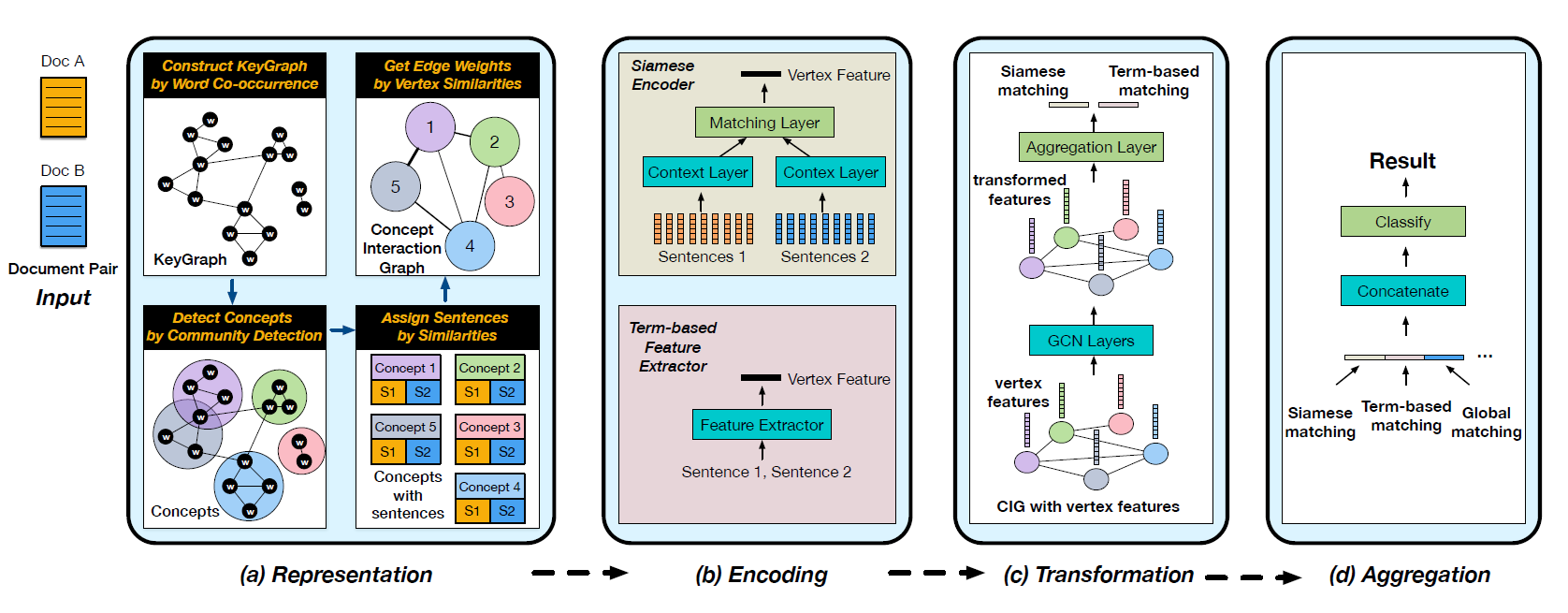
Matching Article Pairs with Graphical Decomposition and Convolutions(ACL 2019)
- Authors’ work in text matching and document graph structural representation involves proposing a document graph construction method, using GCN to extract document features for document-level matching
- This section can improve the previous work’s method of determining whether two documents discuss the same event
- Overall process:
![GrQUEV.png]()
- Graph Construction: Concept Interaction Graph
- First construct key graph, extracting keywords and entities from articles as nodes, creating edges if two nodes appear in the same sentence
- Key graph nodes can be directly used as concepts, or overlapping community detection can be performed to divide the key graph into multiple intersecting subgraphs, with subgraphs serving as concept nodes, intersections creating edges
- Concepts and sentences are now bag-of-words, enabling similarity calculation and sentence assignment to concepts
- Concepts are now sentence collections, viewed as bag-of-words, with edges between concepts based on sentence set TF-IDF vector similarity
- Critically, since matching is performed, input is sentence pairs, transformed into graph pairs. Authors merge two CIGs into a large CIG, placing sentence sets from two articles describing the same concept in one concept node
Constructing Matching Network with GCN
- After obtaining a large CIG, matching between two documents becomes matching between sentence sets from two documents within each node
- Construct an end-to-end process: use Siamese networks to extract node features, use GCN for inter-node feature interaction, aggregate features for prediction
Each node contains two sentence sets, concatenated into two long sentences, input into Siamese networks, extracting features using BiLSTM or CNN, then feature aggregation:
- Obtaining matching vector for each node, representing similarity-related features between two documents at that concept. Additionally, authors extracted traditional similarity features (TF-IDF, BM25, Jaccard, Ochiai) and concatenated them with matching vectors
- Next, pass through GCN
- Aggregate all node features using simple mean pooling, then pass through a linear layer for classification (0, 1)
- On long news corpora (avg 734 tokens), graph matching significantly outperforms traditional two-tower models (DUET, DSSM, ARC at 50-60 F1, graph model reaching 70-80)
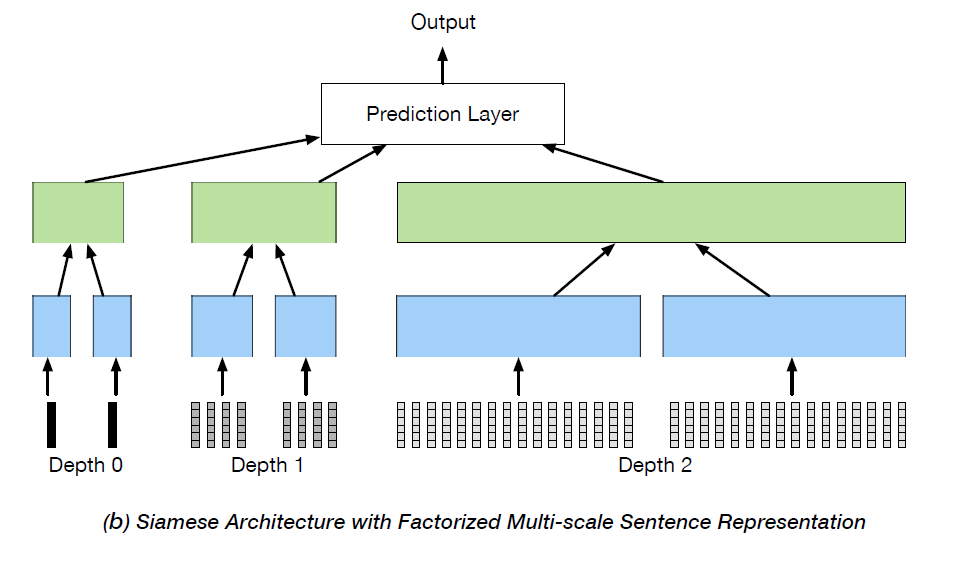
Matching Natural Language Sentences with Hierarchical Sentence Factorization(WWW 2018)
- Sentence pair semantic matching task, primarily utilizing AMR parsing to obtain sentence structure
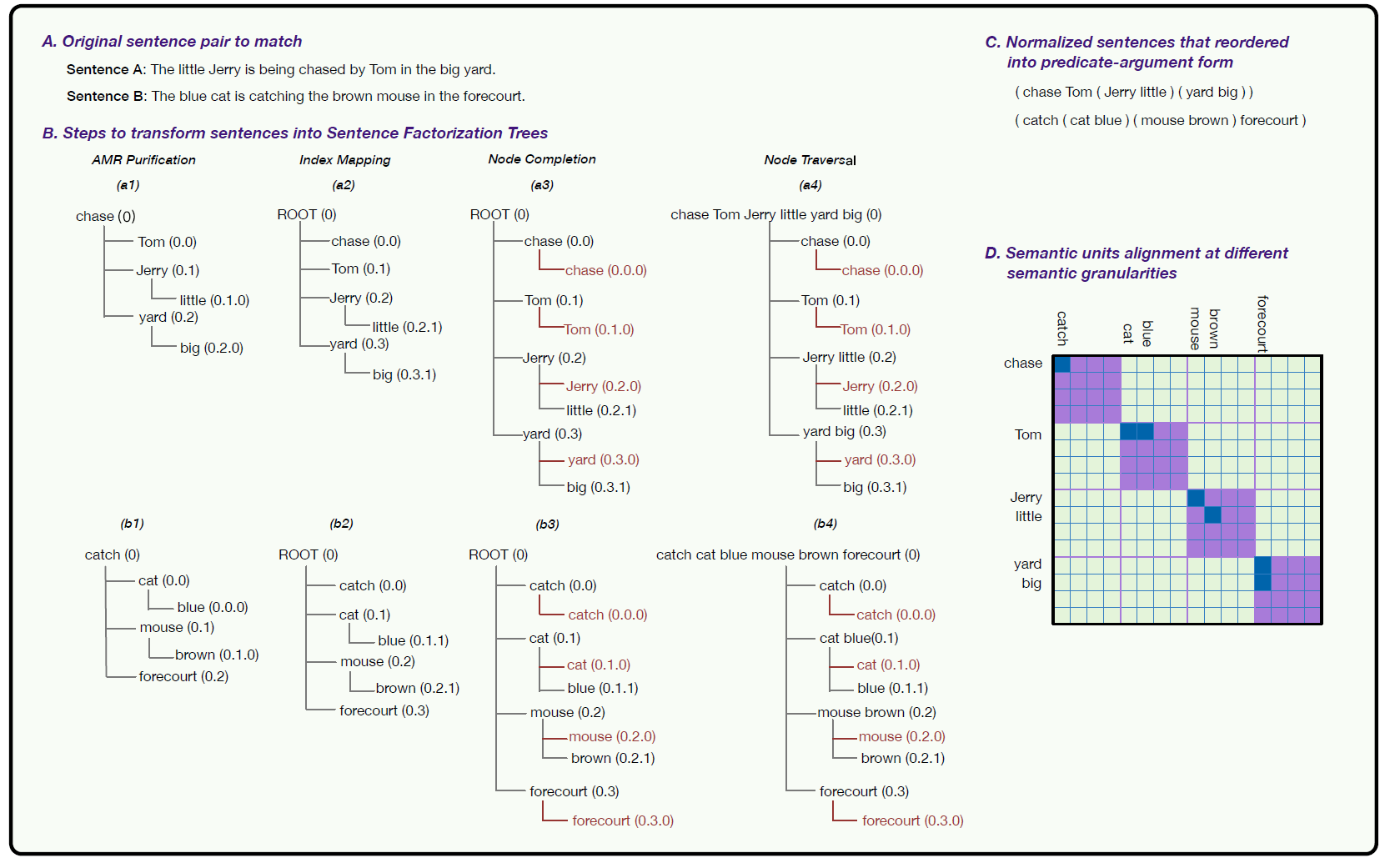
- Five steps
- AMR parsing and alignment: AMR represents sentences as directed acyclic graphs; by copying and splitting nodes with multiple parents, the directed acyclic graph can be converted to a tree. AMR leaf nodes represent concepts, others are relationships representing concept connections or concept parameters. After obtaining AMR graph, alignment is needed to connect specific tokens with concepts. Authors used existing tool JAMR
- AMR purification: A token might connect to multiple concepts; authors select only the shallowest concept connection, remove relationship content, retain edges without edge labels, obtaining simplified AMR tree
- Index mapping: Add root node, reset node coordinates
- Node completion: Similar to padding, ensuring tree depths are identical
- Node traversal: Perform depth-first search, concatenating child tree content to each non-leaf node
- The root node obtains a reorganized sentence representation, similar to predicate-argument form. Authors suggest this can uniformly express two sentences, avoiding semantic matching errors caused by word order and less important words
- Subsequently use Ordered Word Mover Distance. The formula represents transportation cost (embedding distance), transportation volume (word proportion), α, β represent word frequency vectors of both sentences, with uniform distribution directly substituted. Traditional WMD didn’t consider word order; authors introduced two penalty terms, with T primarily concentrated on diagonal when I is large. P is an ideal T distribution, with row-column elements satisfying standard Gaussian distribution distance from diagonal, hoping T becomes a diagonal matrix
- This method calculates OWMD distance for AMR representations of two sentences, completing unsupervised text similarity calculation. Can also utilize AMR Tree for supervised learning
- Note that different AMR tree layers represent different semantic granularities of the entire sentence. Authors selected first three layers, inputting different granularity semantic units into context layer, summing token embeddings within the same semantic unit, assuming maximum k child nodes per layer, padding if insufficient
![GbgQUA.png]()